记一次 openstack 云主机热迁移失败与恢复过程
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次 openstack 云主机热迁移失败与恢复过程相关的知识,希望对你有一定的参考价值。
背景:最近把openstack上的所有机器的磁盘逐一重新分区,之前是两块磁盘用RAID1,但是ceph已经配置了3份副本,这样相当于存6份副本了,目前磁盘资源不太够。机器用的是HP P440ar的阵列卡,支持建立不同模式的逻辑卷,所以把磁盘分区修改为RAID1系统盘+RAID0数据盘,磁盘容量和数据盘读写速度扩大一倍,而且即使其中一块磁盘故障了也不影响物理机的运行,而其上的虚拟机是基于ceph网络存储的,坏了一个osd也不会影响运行。
故障概括:有一个计算节点的neutron-linuxbridge-agent忘记配置,直接把虚拟机热迁移到此机器了,结果在最后一步创建网络接口的时候报错,虚拟机已经运行了起来,但是网络不通,把网络组建配置好之后重启虚拟机实例也没有自动创建接口,不知道在哪步出差错了,也没去深究具体原因了,这方法也适合其他情况出现迁移(冷或热)失败的恢复。
环境:Openstack Mitaka,Ceph Hammer,rbd存储池名称 images_rbd_pool = vms
原理:复制原实例系统盘到新的实例中,直接操作ceph底层rbd镜像
操作过程:
1、新建一个配置与原实例一致的云主机,把两个实例关机后,本文是把实例SA的系统盘替换到新建实例SA2上,把实例SA删除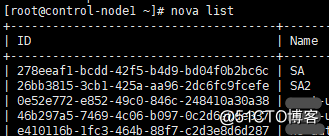
2、查看系统盘状态,确认已断开连接
系统盘的名称默认是实例的"<id>_disk"rbd ls vms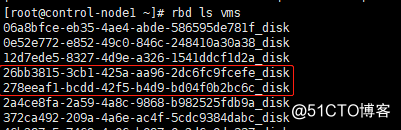
rbd status vms/26bb3815-3cb1-425a-aa96-2dc6fc9fcefe_disk
rbd status vms/278eeaf1-bcdd-42f5-b4d9-bd04f0b2bc6c_disk
注:若磁盘处于被挂载状态是这样显示
3、把新建实例的系统盘镜像改名,再把原实例系统盘镜像名称改为新实例
rbd mv vms/26bb3815-3cb1-425a-aa96-2dc6fc9fcefe_disk vms/26bb3815-3cb1-425a-aa96-2dc6fc9fcefe_disk_bak
rbd mv vms/278eeaf1-bcdd-42f5-b4d9-bd04f0b2bc6c_disk vms/26bb3815-3cb1-425a-aa96-2dc6fc9fcefe_disk
rbd ls vms
4、新建一个空的rbd镜像作为原实例的系统盘镜像,防止删除原云主机实例时候报错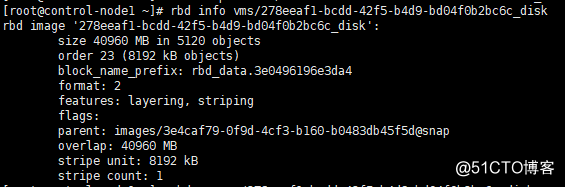
理论上随便建一个就可以,删除的时候应该不会校验其他信息,为了尽量保持一致就新建一个大小和版本格式一致的:rbd create --size 40960 --image-format 2 vms/278eeaf1-bcdd-42f5-b4d9-bd04f0b2bc6c_disk
5、在openstack删除原来的云主机,启动新的实例即可,网络接口方面的配置省略。
总结:以后在做危险操作之前最好先做个快照,有备无患:
rbd snap create vms/[email protected]_20180511
rbd snap protect vms/[email protected]_20180511即使操作过程中出现不可预计错误导致程序执行了删除操作也可以恢复回去(做快照后不可直接删除)
以上是关于记一次 openstack 云主机热迁移失败与恢复过程的主要内容,如果未能解决你的问题,请参考以下文章