理解MapReduce计算构架
Posted phoenlix
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解MapReduce计算构架相关的知识,希望对你有一定的参考价值。
1.编写map函数,reduce函数
(1)创建mapper.py文件
cd /home/hadoop/wc
gedit mapper.p
(2)mapper函数
#!/usr/bin/env python
import sys
for i in stdin:
i = i.strip()
words = i.split()
for word in words:
print \'%s\\t%s\' % (word,1)
(3)reducer.py文件创建
cd /home/hadoop/wc
gedit reducer.py
(4)reducer函数
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for i in stdin:
i = i.strip()
word, count = i.split(\'\\t\',1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print \'%s\\t%s\' % (current_word, current_count)
current_count = count
current_word = word
if current_word == word:
print \'%s\\t%s\' % (current_word, current_count)
2.将其权限作出相应修改
chmod a+x /home/hadoop/mapper.py
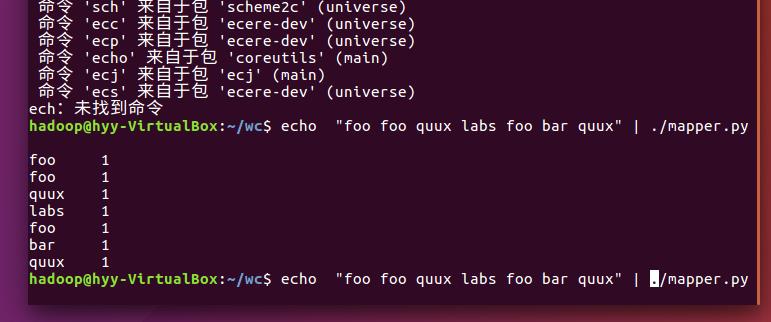
echo "foo foo quux labs foo bar quux" | /home/hadoop/wc/mapper.py
echo "foo foo quux labs foo bar quux" | /home/hadoop/wc/mapper.py | sort -k1,1 | /home/hadoop/wc/reducer.p
3.本机上测试运行代码
放到HDFS上运行
下载并上传文件到hdfs上
cd /home/hadoop/wc wget http://www.gutenberg.org/files/5000/5000-8.txt wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt
cd /usr/hadoop/wc hdfs dfs -put /home/hadoop/hadoop/gutenberg/*.txt /user/hadoop/input
以上是关于理解MapReduce计算构架的主要内容,如果未能解决你的问题,请参考以下文章