kaggle入门项目:Titanic存亡预测验证与实现
Posted fancyutech
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kaggle入门项目:Titanic存亡预测验证与实现相关的知识,希望对你有一定的参考价值。
原kaggle比赛地址:https://www.kaggle.com/c/titanic
原kernel地址:A Data Science Framework: To Achieve 99% Accuracy
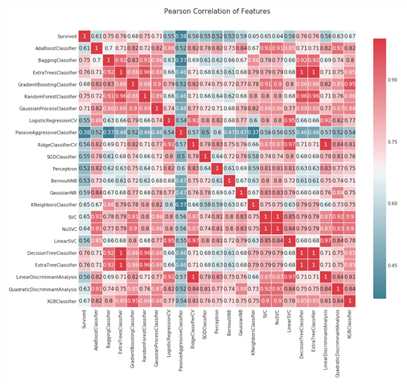
首先我们绘制出皮尔森系相关度的热力图,关于皮尔森系数可以翻阅资料,是一个很简洁的判断相关度的公式。
终于要进行最终的模型拟合了,我们使用投票法则,首先构建一个投票算法的list,将我们所需要的算法全部包含进去:
vote_est = [ #Ensemble Methods: http://scikit-learn.org/stable/modules/ensemble.html (‘ada‘, ensemble.AdaBoostClassifier()), (‘bc‘, ensemble.BaggingClassifier()), (‘etc‘,ensemble.ExtraTreesClassifier()), (‘gbc‘, ensemble.GradientBoostingClassifier()), (‘rfc‘, ensemble.RandomForestClassifier()), #Gaussian Processes: http://scikit-learn.org/stable/modules/gaussian_process.html#gaussian-process-classification-gpc (‘gpc‘, gaussian_process.GaussianProcessClassifier()), #GLM: http://scikit-learn.org/stable/modules/linear_model.html#logistic-regression (‘lr‘, linear_model.LogisticRegressionCV()), #Navies Bayes: http://scikit-learn.org/stable/modules/naive_bayes.html (‘bnb‘, naive_bayes.BernoulliNB()), (‘gnb‘, naive_bayes.GaussianNB()), #Nearest Neighbor: http://scikit-learn.org/stable/modules/neighbors.html (‘knn‘, neighbors.KNeighborsClassifier()), #SVM: http://scikit-learn.org/stable/modules/svm.html (‘svc‘, svm.SVC(probability=True)), #xgboost: http://xgboost.readthedocs.io/en/latest/model.html (‘xgb‘, XGBClassifier()) ]
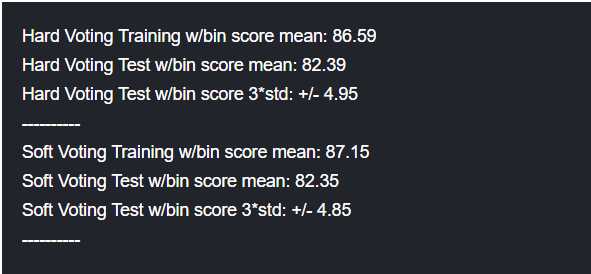
重要的来了,我们使用VotingClassifier()进行投票,这里的投票法分为硬投票和软投票,硬投票按照算法标签进行排序,软投票通过类概率进行选择。


#Hard Vote or majority rules vote_hard = ensemble.VotingClassifier(estimators = vote_est , voting = ‘hard‘) vote_hard_cv = model_selection.cross_validate(vote_hard, data1[data1_x_bin], data1[Target], cv = cv_split) vote_hard.fit(data1[data1_x_bin], data1[Target]) print("Hard Voting Training w/bin score mean: {:.2f}". format(vote_hard_cv[‘train_score‘].mean()*100)) print("Hard Voting Test w/bin score mean: {:.2f}". format(vote_hard_cv[‘test_score‘].mean()*100)) print("Hard Voting Test w/bin score 3*std: +/- {:.2f}". format(vote_hard_cv[‘test_score‘].std()*100*3)) print(‘-‘*10) #Soft Vote or weighted probabilities vote_soft = ensemble.VotingClassifier(estimators = vote_est , voting = ‘soft‘) vote_soft_cv = model_selection.cross_validate(vote_soft, data1[data1_x_bin], data1[Target], cv = cv_split) vote_soft.fit(data1[data1_x_bin], data1[Target]) print("Soft Voting Training w/bin score mean: {:.2f}". format(vote_soft_cv[‘train_score‘].mean()*100)) print("Soft Voting Test w/bin score mean: {:.2f}". format(vote_soft_cv[‘test_score‘].mean()*100)) print("Soft Voting Test w/bin score 3*std: +/- {:.2f}". format(vote_soft_cv[‘test_score‘].std()*100*3)) print(‘-‘*10)
然后是两种投票的结果:
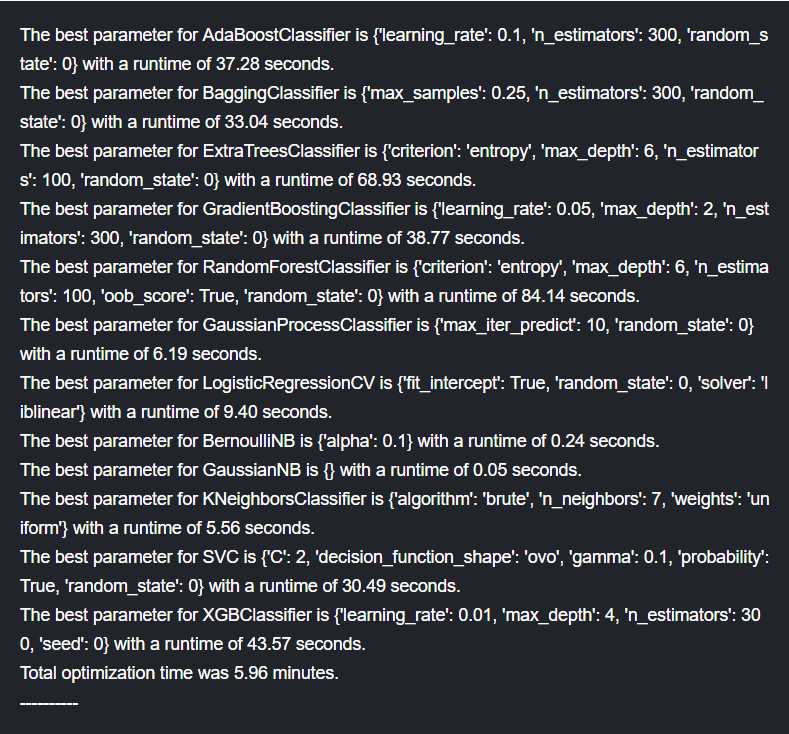
接下来就是及其耗费时间和算力的GridSearchCV选取所有算法的超参数了,我们将所有算法的参数可能取值设定好(包含在一个list里),然后放入循环,对每一个算法进行FridSearch,最终得出所有算法的最佳参数和相应运算时间。
#WARNING: Running is very computational intensive and time expensive. #Code is written for experimental/developmental purposes and not production ready! #Hyperparameter Tune with GridSearchCV: http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html grid_n_estimator = [10, 50, 100, 300] grid_ratio = [.1, .25, .5, .75, 1.0] grid_learn = [.01, .03, .05, .1, .25] grid_max_depth = [2, 4, 6, 8, 10, None] grid_min_samples = [5, 10, .03, .05, .10] grid_criterion = [‘gini‘, ‘entropy‘] grid_bool = [True, False] grid_seed = [0] grid_param = [ [{ #AdaBoostClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html ‘n_estimators‘: grid_n_estimator, #default=50 ‘learning_rate‘: grid_learn, #default=1 #‘algorithm‘: [‘SAMME‘, ‘SAMME.R‘], #default=’SAMME.R ‘random_state‘: grid_seed }], [{ #BaggingClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.BaggingClassifier.html#sklearn.ensemble.BaggingClassifier ‘n_estimators‘: grid_n_estimator, #default=10 ‘max_samples‘: grid_ratio, #default=1.0 ‘random_state‘: grid_seed }], [{ #ExtraTreesClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesClassifier.html#sklearn.ensemble.ExtraTreesClassifier ‘n_estimators‘: grid_n_estimator, #default=10 ‘criterion‘: grid_criterion, #default=”gini” ‘max_depth‘: grid_max_depth, #default=None ‘random_state‘: grid_seed }], [{ #GradientBoostingClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier #‘loss‘: [‘deviance‘, ‘exponential‘], #default=’deviance’ ‘learning_rate‘: [.05], #default=0.1 -- 12/31/17 set to reduce runtime -- The best parameter for GradientBoostingClassifier is {‘learning_rate‘: 0.05, ‘max_depth‘: 2, ‘n_estimators‘: 300, ‘random_state‘: 0} with a runtime of 264.45 seconds. ‘n_estimators‘: [300], #default=100 -- 12/31/17 set to reduce runtime -- The best parameter for GradientBoostingClassifier is {‘learning_rate‘: 0.05, ‘max_depth‘: 2, ‘n_estimators‘: 300, ‘random_state‘: 0} with a runtime of 264.45 seconds. #‘criterion‘: [‘friedman_mse‘, ‘mse‘, ‘mae‘], #default=”friedman_mse” ‘max_depth‘: grid_max_depth, #default=3 ‘random_state‘: grid_seed }], [{ #RandomForestClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier ‘n_estimators‘: grid_n_estimator, #default=10 ‘criterion‘: grid_criterion, #default=”gini” ‘max_depth‘: grid_max_depth, #default=None ‘oob_score‘: [True], #default=False -- 12/31/17 set to reduce runtime -- The best parameter for RandomForestClassifier is {‘criterion‘: ‘entropy‘, ‘max_depth‘: 6, ‘n_estimators‘: 100, ‘oob_score‘: True, ‘random_state‘: 0} with a runtime of 146.35 seconds. ‘random_state‘: grid_seed }], [{ #GaussianProcessClassifier ‘max_iter_predict‘: grid_n_estimator, #default: 100 ‘random_state‘: grid_seed }], [{ #LogisticRegressionCV - http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegressionCV.html#sklearn.linear_model.LogisticRegressionCV ‘fit_intercept‘: grid_bool, #default: True #‘penalty‘: [‘l1‘,‘l2‘], ‘solver‘: [‘newton-cg‘, ‘lbfgs‘, ‘liblinear‘, ‘sag‘, ‘saga‘], #default: lbfgs ‘random_state‘: grid_seed }], [{ #BernoulliNB - http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.BernoulliNB.html#sklearn.naive_bayes.BernoulliNB ‘alpha‘: grid_ratio, #default: 1.0 }], #GaussianNB - [{}], [{ #KNeighborsClassifier - http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html#sklearn.neighbors.KNeighborsClassifier ‘n_neighbors‘: [1,2,3,4,5,6,7], #default: 5 ‘weights‘: [‘uniform‘, ‘distance‘], #default = ‘uniform’ ‘algorithm‘: [‘auto‘, ‘ball_tree‘, ‘kd_tree‘, ‘brute‘] }], [{ #SVC - http://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html#sklearn.svm.SVC #http://blog.hackerearth.com/simple-tutorial-svm-parameter-tuning-python-r #‘kernel‘: [‘linear‘, ‘poly‘, ‘rbf‘, ‘sigmoid‘], ‘C‘: [1,2,3,4,5], #default=1.0 ‘gamma‘: grid_ratio, #edfault: auto ‘decision_function_shape‘: [‘ovo‘, ‘ovr‘], #default:ovr ‘probability‘: [True], ‘random_state‘: grid_seed }], [{ #XGBClassifier - http://xgboost.readthedocs.io/en/latest/parameter.html ‘learning_rate‘: grid_learn, #default: .3 ‘max_depth‘: [1,2,4,6,8,10], #default 2 ‘n_estimators‘: grid_n_estimator, ‘seed‘: grid_seed }] ] start_total = time.perf_counter() #https://docs.python.org/3/library/time.html#time.perf_counter for clf, param in zip (vote_est, grid_param): #https://docs.python.org/3/library/functions.html#zip #print(clf[1]) #vote_est is a list of tuples, index 0 is the name and index 1 is the algorithm #print(param) start = time.perf_counter() best_search = model_selection.GridSearchCV(estimator = clf[1], param_grid = param, cv = cv_split, scoring = ‘roc_auc‘) best_search.fit(data1[data1_x_bin], data1[Target]) run = time.perf_counter() - start best_param = best_search.best_params_ print(‘The best parameter for {} is {} with a runtime of {:.2f} seconds.‘.format(clf[1].__class__.__name__, best_param, run)) clf[1].set_params(**best_param) run_total = time.perf_counter() - start_total print(‘Total optimization time was {:.2f} minutes.‘.format(run_total/60)) print(‘-‘*10)
我们可以看到gridsearch非常耗时,这还是在千数据量的情况下。我的8250u跑了数分钟,其实作者的耗时(截图中体现)比我的耗时更长了点。可想而知如果面对百万千万的数据集确实需要更强的算力和更长的时间了。
然后我们根据已经选出的每个算法的最佳参数,再使用投票法。结果如下。

最后终于要输出结果了,作者给出了我们之前涉及到的所有方法的最终预测代码与准确率:
#prepare data for modeling print(data_val.info()) print("-"*10) #data_val.sample(10) #handmade decision tree - submission score = 0.77990 data_val[‘Survived‘] = mytree(data_val).astype(int) #decision tree w/full dataset modeling submission score: defaults= 0.76555, tuned= 0.77990 #submit_dt = tree.DecisionTreeClassifier() #submit_dt = model_selection.GridSearchCV(tree.DecisionTreeClassifier(), param_grid=param_grid, scoring = ‘roc_auc‘, cv = cv_split) #submit_dt.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_dt.best_params_) #Best Parameters: {‘criterion‘: ‘gini‘, ‘max_depth‘: 4, ‘random_state‘: 0} #data_val[‘Survived‘] = submit_dt.predict(data_val[data1_x_bin]) #bagging w/full dataset modeling submission score: defaults= 0.75119, tuned= 0.77990 #submit_bc = ensemble.BaggingClassifier() #submit_bc = model_selection.GridSearchCV(ensemble.BaggingClassifier(), param_grid= {‘n_estimators‘:grid_n_estimator, ‘max_samples‘: grid_ratio, ‘oob_score‘: grid_bool, ‘random_state‘: grid_seed}, scoring = ‘roc_auc‘, cv = cv_split) #submit_bc.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_bc.best_params_) #Best Parameters: {‘max_samples‘: 0.25, ‘n_estimators‘: 500, ‘oob_score‘: True, ‘random_state‘: 0} #data_val[‘Survived‘] = submit_bc.predict(data_val[data1_x_bin]) #extra tree w/full dataset modeling submission score: defaults= 0.76555, tuned= 0.77990 #submit_etc = ensemble.ExtraTreesClassifier() #submit_etc = model_selection.GridSearchCV(ensemble.ExtraTreesClassifier(), param_grid={‘n_estimators‘: grid_n_estimator, ‘criterion‘: grid_criterion, ‘max_depth‘: grid_max_depth, ‘random_state‘: grid_seed}, scoring = ‘roc_auc‘, cv = cv_split) #submit_etc.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_etc.best_params_) #Best Parameters: {‘criterion‘: ‘entropy‘, ‘max_depth‘: 6, ‘n_estimators‘: 100, ‘random_state‘: 0} #data_val[‘Survived‘] = submit_etc.predict(data_val[data1_x_bin]) #random foreset w/full dataset modeling submission score: defaults= 0.71291, tuned= 0.73205 #submit_rfc = ensemble.RandomForestClassifier() #submit_rfc = model_selection.GridSearchCV(ensemble.RandomForestClassifier(), param_grid={‘n_estimators‘: grid_n_estimator, ‘criterion‘: grid_criterion, ‘max_depth‘: grid_max_depth, ‘random_state‘: grid_seed}, scoring = ‘roc_auc‘, cv = cv_split) #submit_rfc.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_rfc.best_params_) #Best Parameters: {‘criterion‘: ‘entropy‘, ‘max_depth‘: 6, ‘n_estimators‘: 100, ‘random_state‘: 0} #data_val[‘Survived‘] = submit_rfc.predict(data_val[data1_x_bin]) #ada boosting w/full dataset modeling submission score: defaults= 0.74162, tuned= 0.75119 #submit_abc = ensemble.AdaBoostClassifier() #submit_abc = model_selection.GridSearchCV(ensemble.AdaBoostClassifier(), param_grid={‘n_estimators‘: grid_n_estimator, ‘learning_rate‘: grid_ratio, ‘algorithm‘: [‘SAMME‘, ‘SAMME.R‘], ‘random_state‘: grid_seed}, scoring = ‘roc_auc‘, cv = cv_split) #submit_abc.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_abc.best_params_) #Best Parameters: {‘algorithm‘: ‘SAMME.R‘, ‘learning_rate‘: 0.1, ‘n_estimators‘: 300, ‘random_state‘: 0} #data_val[‘Survived‘] = submit_abc.predict(data_val[data1_x_bin]) #gradient boosting w/full dataset modeling submission score: defaults= 0.75119, tuned= 0.77033 #submit_gbc = ensemble.GradientBoostingClassifier() #submit_gbc = model_selection.GridSearchCV(ensemble.GradientBoostingClassifier(), param_grid={‘learning_rate‘: grid_ratio, ‘n_estimators‘: grid_n_estimator, ‘max_depth‘: grid_max_depth, ‘random_state‘:grid_seed}, scoring = ‘roc_auc‘, cv = cv_split) #submit_gbc.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_gbc.best_params_) #Best Parameters: {‘learning_rate‘: 0.25, ‘max_depth‘: 2, ‘n_estimators‘: 50, ‘random_state‘: 0} #data_val[‘Survived‘] = submit_gbc.predict(data_val[data1_x_bin]) #extreme boosting w/full dataset modeling submission score: defaults= 0.73684, tuned= 0.77990 #submit_xgb = XGBClassifier() #submit_xgb = model_selection.GridSearchCV(XGBClassifier(), param_grid= {‘learning_rate‘: grid_learn, ‘max_depth‘: [0,2,4,6,8,10], ‘n_estimators‘: grid_n_estimator, ‘seed‘: grid_seed}, scoring = ‘roc_auc‘, cv = cv_split) #submit_xgb.fit(data1[data1_x_bin], data1[Target]) #print(‘Best Parameters: ‘, submit_xgb.best_params_) #Best Parameters: {‘learning_rate‘: 0.01, ‘max_depth‘: 4, ‘n_estimators‘: 300, ‘seed‘: 0} #data_val[‘Survived‘] = submit_xgb.predict(data_val[data1_x_bin]) #hard voting classifier w/full dataset modeling submission score: defaults= 0.75598, tuned = 0.77990 #data_val[‘Survived‘] = vote_hard.predict(data_val[data1_x_bin]) data_val[‘Survived‘] = grid_hard.predict(data_val[data1_x_bin]) #soft voting classifier w/full dataset modeling submission score: defaults= 0.73684, tuned = 0.74162 #data_val[‘Survived‘] = vote_soft.predict(data_val[data1_x_bin]) #data_val[‘Survived‘] = grid_soft.predict(data_val[data1_x_bin]) #submit file submit = data_val[[‘PassengerId‘,‘Survived‘]] submit.to_csv("../working/submit.csv", index=False) print(‘Validation Data Distribution: \\n‘, data_val[‘Survived‘].value_counts(normalize = True)) submit.sample(10)
最终的输出我就不再贴图了,和我们所需要的最终结果关系不大,无非是各个feature的数量总结。
我们在当前文件夹生成了‘submit.csv’的文件,直接提交到kaggle上吧。
Step 7: Optimize and Strategize
最后我们惊奇的发现,尽管使用了那么多算法,进行了那么多参数调整,我们得出的最终准确率竟然和我们手动推出来的决策树几乎一样!但是作者最后说,仅用了几个算法在这一个数据集上并不能得出什么可靠的结论,我们需要记住一下几点:
1.训练集的分布和测试集的分布并不一样,因此我们自己所做的CV分数和kaggle提交上去的准确率确实会有很大差别。
2.在相同的数据集下,基于决策树的算法在调整参数之后似乎会收敛到同一个准确率。
3.如果忽略调参,没有任何的MLA能强过自制的算法
所以如果想取得更好的成果还是要进行更多的数据处理和特征工程。
完
以上是关于kaggle入门项目:Titanic存亡预测验证与实现的主要内容,如果未能解决你的问题,请参考以下文章