JVM学习记录-垃圾回收算法
Posted 纪莫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM学习记录-垃圾回收算法相关的知识,希望对你有一定的参考价值。
简述
因为各个平台的虚拟机的垃圾收集器的实现各有不同,所以只介绍几个常见的垃圾收集算法。
JVM中常见的垃圾收集算法有以下四种:
标记-清除算法(Mark-Sweep)。
复制算法(Copying)。
标记整理算法(Mark-Compact)。
分代收集算法(Generational Collecting)。
标记-清除算法
标记-清除算法是现代垃圾回收算法的思想基础,主要分为两个阶段:标记阶段和清除阶段。首先根据可达分析算法,标记处可以回收的对象,标记完成后,进行清除阶段,将标记为可回收的对象进行清除。这个算法有两个弱点,一个弱点是效率问题,标记和清除效率都不高,另一弱点,也是最大的弱点就是会产生空间碎片。当内存中空间碎片过多时,在创建较大的对象过程中,无法分配出足够的联系内存空间,会不得以的出发一次垃圾回收动作。
标记-清除算法执行过程如下图所示:

复制算法
与标记-清除算法相比,复制算法是一种相对效率高的回收算法,它的核心思想是:将原有的内存空间划分为大小相等的两块,每次只使用其中一块,在垃圾回收时,将正在使用的内存中的存活的对象复制到未使用的的内存块中,然后清除正在使用的内存块,然后交换两个内存的角色(即使用块变成未使用块,未使用块变成使用块)。复制算法可以保证回收后没有空间碎片。但是复制算法的弱点是将系统可用内存折半,这个代价有些太大。
执行过程如下:
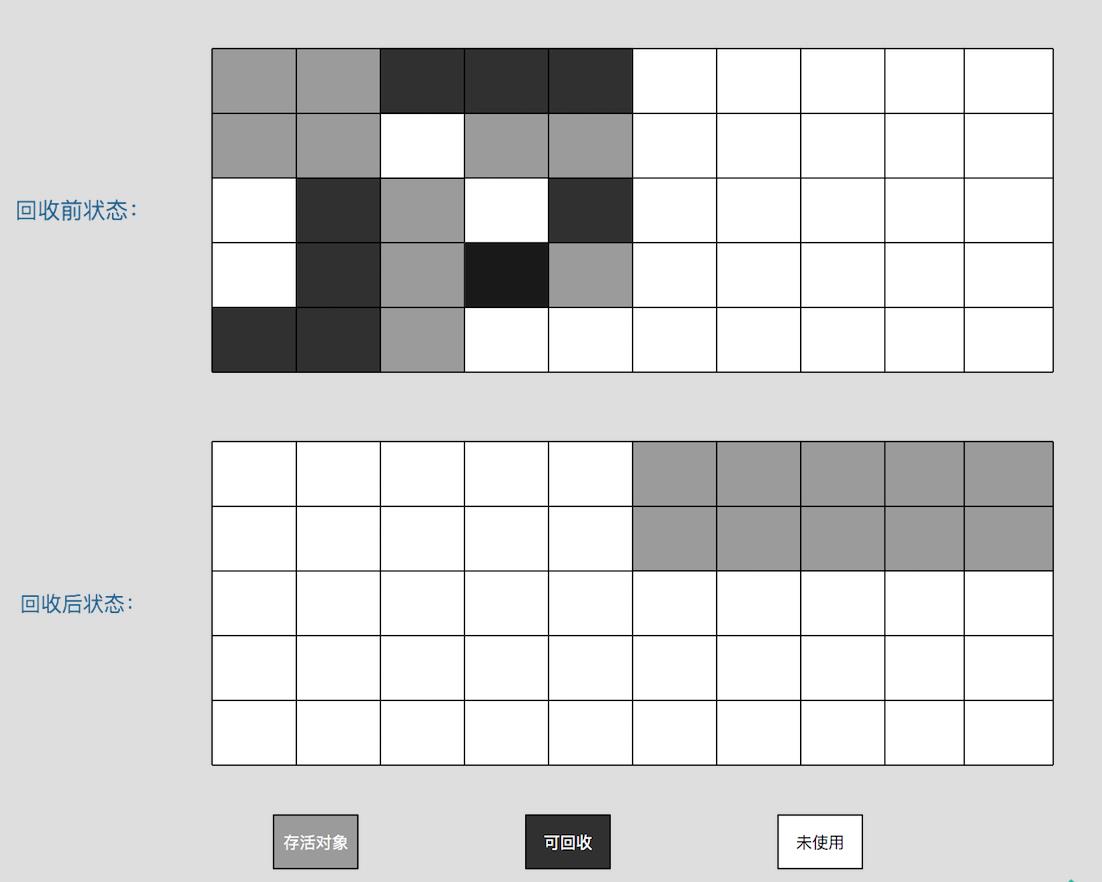
在JVM的新生代(堆内存分为新生代和老年代)中就是使用的这种收集算法,在新生代中大部分对象都是“朝生夕死”,所以复制算法也不是非要按照对半平分内存,而是分为较大的一个Eden空间和两个较小的Survivor空间(from和to),每次进行新生代回收时会将Eden区和from Survivor区还存活着的对象复制到to Survivor区,然后清理掉Eden区和from Survivor区的可回收对象,如果to Survivor区中没有足够的空间来接受还存活着的对象,则会把多余的对象放到老年代区。这种改进的(非平分内存)复制算法,既保证了空间的连续性,又避免了大量的内存空间的浪费。
复制算法适用于新生代,是因为在新生代中,垃圾对象通常多于存活对象,这中情况适用复制算法效果会比较好。
标记整理算法
复制算法的高效性,是因为新生代的存活对象多,垃圾对象少。但是在老年代中,常见的情况下大部分都是存活对象,如果依然只用复制算法,效率就会大大折扣。因为存活对象太多,复制的成本太高了。
基于老年代的特点,产生了一种标记整理算法,标记整理算法也是分两个阶段,标记阶段和整理阶段,标记阶段也是先标记出存活的对象,在整理阶段是将存活的对象都向内存的一端进行压缩移动,然后清理掉端边界以外的空间。
标记整理算法执行过程如下:
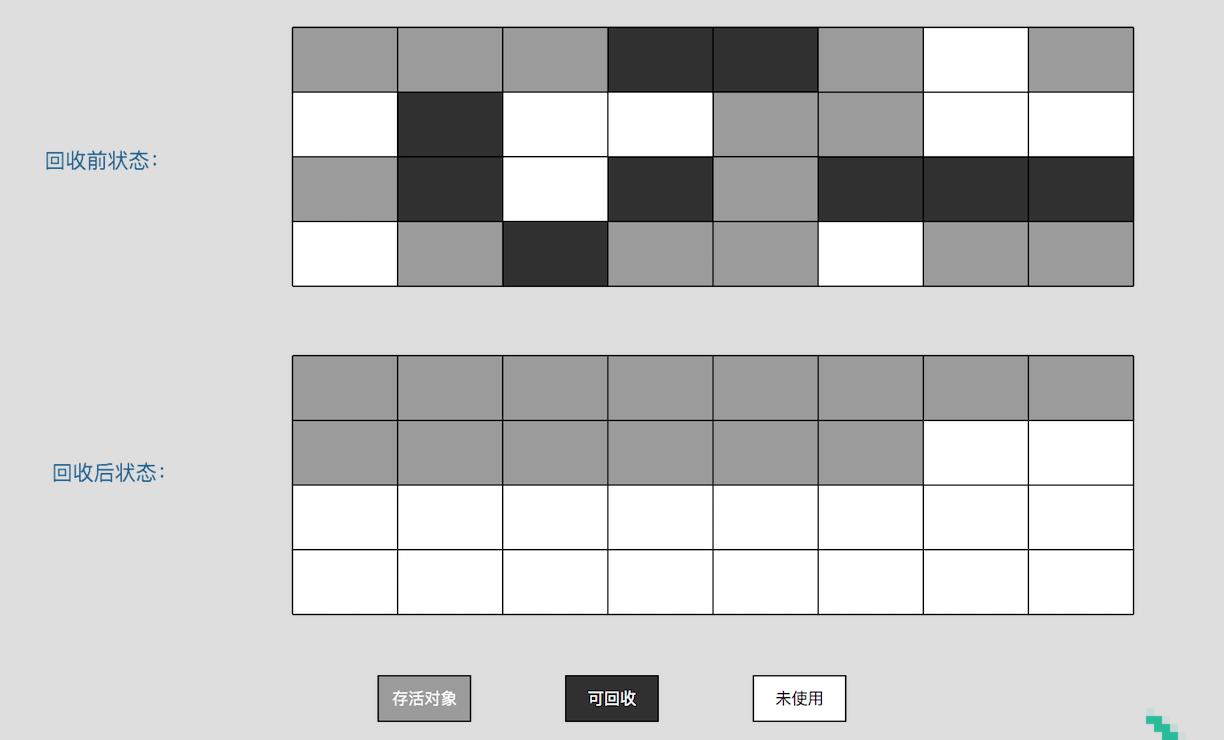
这种算法既避免了产生空间碎片,又不需要将内存平分,因此效率还是可以的。
分代收集算法
当前的商业虚拟机都采用“分代收集算法”,其主要思想是:根据垃圾回收对象的特性,使用合适的算法进行回收。基于这种思想,分代算法将堆内存分为特点鲜明的几块,根据每块的特点,选择适用的收集算法,进而提高回收效率。
在新生代时使用复制算法,在老年代时使用标记压缩算法。
这种分代算法在HotSpot虚拟机上使用,几乎所有的垃圾回收器都区分新生代和老年代。
以上是关于JVM学习记录-垃圾回收算法的主要内容,如果未能解决你的问题,请参考以下文章