利用KNIME建立Spark Machine learning模型 2:泰坦尼克幸存预测
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用KNIME建立Spark Machine learning模型 2:泰坦尼克幸存预测相关的知识,希望对你有一定的参考价值。
本文利用KNIME基于Spark决策树模型算法,通过对泰坦尼克的包含乘客及船员的特征属性的训练数据集进行训练,得出决策树幸存模型,并利用测试数据集对模型进行测试。
1、从Kaggle网站下载训练数据集和测试数据集
2、在KNIME创建新的Workflow,起名:TitanicKNIMESpark

3. 读取训练数据集
KNIME支持从Hadoop集群读取数据,本文为了简化流程直接从本地读取数据集。
在Node Repository的搜索框里输入CSV Reader,找到CSV Reader节点,并将它拖入画布。

双击或右击CSV Reader对节点进行配置,设置数据集的目录。

右击节点,点击Excute, 然后右击节点,点击File table查看结果

4.利用Missing Value节点对缺失值进行处理
类似第三步的操作找到Missing Value节点,并拖入画布(本文以下操作类似,不再重复),并根据需要设置属性,这里采用简单取平均值的方法处理缺失值。建立CSV Reader节点到Missing Value节点的连接。

右击节点,点击Excute, 然后右击节点,点击Output Table查看结果

5、添加Create Spark Context节点,设置Spark Context
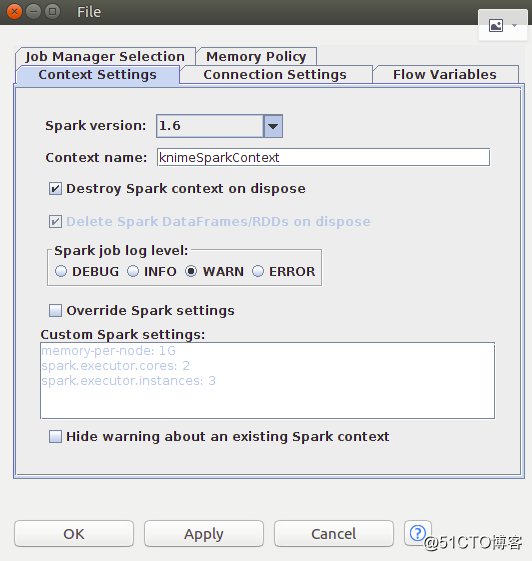
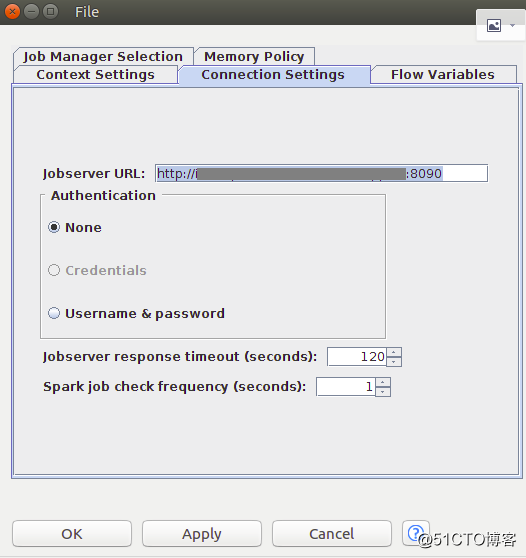
6 .添加Table to Spark节点,将KNIME数据表转换成Spark的DataFrame/RDD,配置Table to Spark节点并建立Missing Value节点到Table to Spark节点的连接,建立Create Spark Context节点到Table to Spark节点的连接。
这里采用默认配置。
7. 添加Spark Normalizer节点,将Survived属性从数字类型转换成为字符类型,配置Spark Normalizer节点并建立Table to Spark节点到Spark Normalizer节点的连接。

右击节点,点击Excute, 然后右击节点,点击Normalized Spark DataFrame/RDD查看结果.

8. 添加Spark Decision Tree Learner节点,配置决策树算法参数,并建立Spark Normalizer节点到Spark Decision Tree Learner节点的连接。

右击节点,点击Excute, 然后右击节点,点击Decision Tree Model查看结果.

9利用测试数据集和Spark Predictor节点对模型进行测试。
复制CSV Reader,Missing Value和Table to Spark节点并参考3,4,6步进行配置读取测试数据集并对数据进行处理和转换。添加Spark Predictor节点, 配置 Spark Predictor节点,并将新添加的Table to Spark节点以及Spark Decision Tree Learner节点和Spark Predictor相连接。
CSV Reader配置测试数据集。

Spark Predictor节点配置Prediction column

右击节点,点击Excute, 然后右击节点,点击Labled Data查看结果.

10.可以添加其他节点对结果进行后续处理,这里添加只添加Spark Column Filter节点过滤掉不需要的column。
添加Spark Column Filter节点并进行配置。

右击节点,点击Excute, 然后右击节点,点击Filtered Spark DataFrame/RDD查看结果。

最终整个workflow如下图所示

以上是关于利用KNIME建立Spark Machine learning模型 2:泰坦尼克幸存预测的主要内容,如果未能解决你的问题,请参考以下文章