熟悉常用的HBase操作,编写MapReduce作业
Posted 李文辉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了熟悉常用的HBase操作,编写MapReduce作业相关的知识,希望对你有一定的参考价值。
1
***创建数据表studen 其中info,course分别为表studen的两个列族, info存储学生个人信息——学号、姓名、性别、年龄 course 则存储课程信息*** create \'studen\',\'info\',\'course\' 接着添加学号为2015001的学生信息 put \'studen\',\'001\',\'info:S_No\',\'2015001\' 此行代码插入一个行健为001的数据,且在列族info中添加一个列S_No,值为2015001。同时由于Hbase一次只能添加一个列数据,所以下面继续添加2015001其他信息 put \'studen\',\'001\',\'info:S_Name\',\'Zhangsan\' put \'studen\',\'001\',\'info:S_Sex\',\'male\' put \'studen\',\'001\',\'info:S_Age\',\'23\'
2

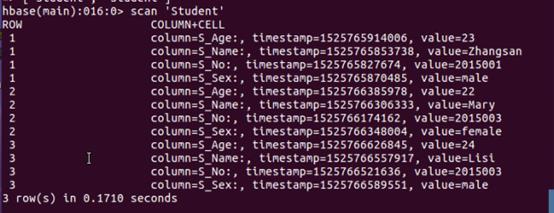





3
cd /home/hadoop/wc sudo gedit mapper.py import sys for i in stdin: i = i.strip() words = i.split() for word in words: print \'%s\\t%s\' % (word,1) from operator import itemgetter import sys current_word = None current_count = 0 word = None for i in stdin: i = i.strip() word, count = i.split(\'\\t\',1) try: count = int(count) except ValueError: continue if current_word == word: current_count += count else: if current_word: print \'%s\\t%s\' % (current_word, current_count) current_count = count current_word = word if current_word == word: print \'%s\\t%s\' % (current_word, current_count) cd /home/hadoop/wc sudo gedit reducer.py chmod a+x /home/hadoop/mapper.py #上传 cd /home/hadoop/wc wget http://www.gutenberg.org/files/5000/5000-8.txt wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt #下载 cd /usr/hadoop/wc hdfs dfs -put /home/hadoop/hadoop/gutenberg/*.txt /user/hadoop/input
以上是关于熟悉常用的HBase操作,编写MapReduce作业的主要内容,如果未能解决你的问题,请参考以下文章