智能手机跑大规模神经网络的主要策略
Posted zhaowei121
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能手机跑大规模神经网络的主要策略相关的知识,希望对你有一定的参考价值。
计算机具有高储量的硬盘和强大的CPU和GPU。但是智能手机却没有,为了弥补这个缺陷,我们需要技巧来让智能手机高效地运行深度学习应用程序。

介绍
深度学习是一个令人难以置信的灵活且强大的技术,但运行的神经网络可以在计算方面需要非常大的电力,且对磁盘空间也有要求。这通常不是云空间能够解决的问题,一般都需要大硬盘服务器上运行驱动器和多个GPU模块。
不幸的是,在移动设备上运行神经网络并不容易。事实上,即使智能手机变得越来越强大,它们仍然具有有限的计算能力、电池寿命和可用磁盘空间,尤其是对于我们希望保持尽可能轻的应用程序。这样做可以实现更快的下载速度、更小的更新时间和更长的电池使用时间,这些都是用户所欣赏的。
为了执行图像分类、人像模式摄影、文本预测以及其他几十项任务,智能手机需要使用技巧来快速,准确地运行神经网络,而无需使用太多的磁盘空间。
在这篇文章中,我们将看到一些最强大的技术,使神经网络能够在手机上实时运行。
使神经网络变得更小更快的技术
基本上,我们对三个指标感兴趣:模型的准确性、速度以及它在手机上占用的空间量。由于没有免费午餐这样的好事,所以我们必须做出妥协。
对于大多数技术,我们会密切关注我们的指标并寻找我们称之为饱和点的东西。这是一个指标的收益停止而其他指标损失的时刻。通过在饱和点之前保持优化值,我们可以获得最佳值。
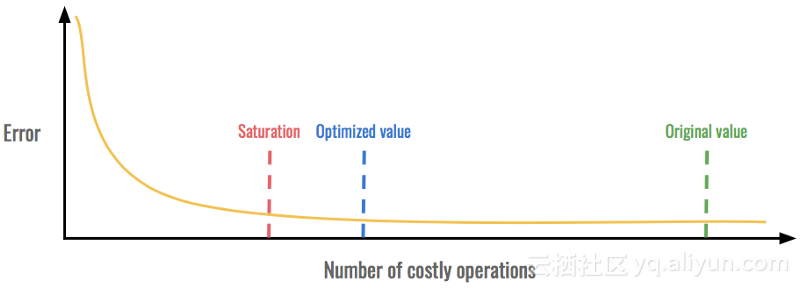
在这个例子中,我们可以在不增加错误的情况下显着减少昂贵的操作次数。但是,在饱和点附近,错误变得太高而无法接受。
1.避免完全连接的层
完全连接的层是神经网络最常见的组成部分之一,它们曾经创造奇迹。然而,由于每个神经元都连接到前一层的所有神经元,因此它们需要存储和更新众多参数。这对速度和磁盘空间是不利的。
卷积层是利用输入中的局部一致性(通常是图像)的层。每个神经元不再连接到前一层的所有神经元。这有助于在保持高精度的同时减少连接/重量的数量。
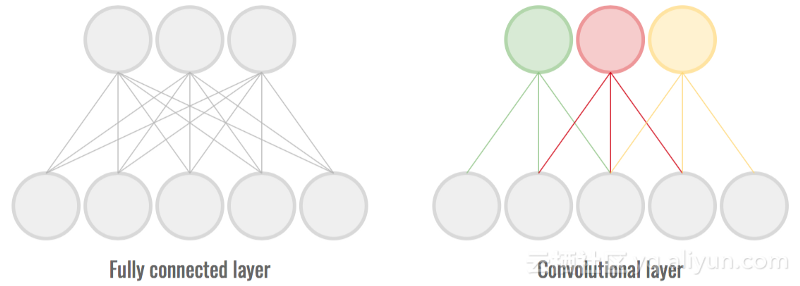
完全连接层中的连接/权重比卷积层中多得多。
使用很少或没有完全连接的层可以减少模型的大小,同时保持高精度。这可以提高速度和磁盘使用率。
在上面的配置中,具有1024个输入和512个输出的完全连接层,这个完全连接层大约有500k个参数。如果是具有相同特征和32个卷积层特征映射,那么它将只具有50K参数,这是一个10倍的改进!
2.减少通道数量和内核大小
这一步代表了模型复杂性和速度之间的一个非常直接的折衷。卷积层中有许多通道允许网络提取相关信息,但需付出代价。删除一些这样的功能是节省空间并使模型变得更快的简单方法。
我们可以用卷积运算的接受域来做同样的事情。通过减小内核大小,卷积对本地模式的了解较少,但涉及的参数较少。
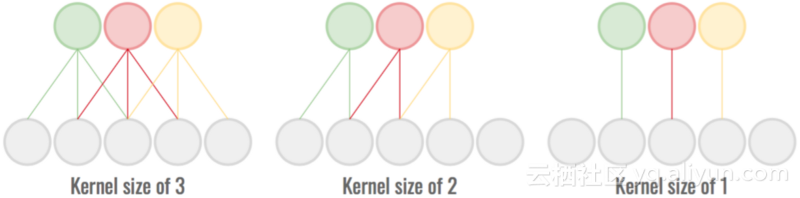
较小的接受区域/内核大小计算起来更便宜,但传达的信息较少。
在这两种情况下,通过查找饱和点来选择地图/内核大小的数量,以便精度不会降低太多。
3.优化缩减采样(Optimizing the downsampling)
对于固定数量的层和固定数量的池操作,神经网络可以表现得非常不同。这来自于一个事实,即表示该数据以及计算量的依赖于在池操作完成:
· 当池化操作提早完成时,数据的维度会降低。越小的维度意味着网络处理速度越快,但意味着信息量越少,准确性越差。
· 当联网操作在网络后期完成时,大部分信息都会保留下来,从而具有很高的准确性。然而,这也意味着计算是在具有许多维度的对象上进行的,并且在计算上更昂贵。
· 在整个神经网络中均匀分布下采样作为一个经验有效的架构,并在准确性和速度之间提供了一个很好的平衡。
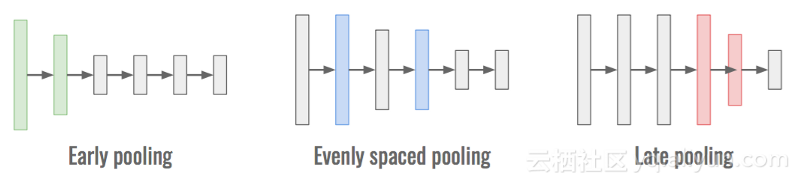
早期的池化速度很快,晚期的池化是准确的,均匀间隔的池化是有点两者。
4.修剪重量(Pruning the weights)
在训练完成的神经网络中,一些权重对神经元的激活起着强烈作用,而另一些权重几乎不影响结果。尽管如此,我们仍然对这些弱权重做一些计算。
修剪是完全去除最小量级连接的过程,以便我们可以跳过计算。这可能会降低了准确性,但使网络更轻、更快。我们需要找到饱和点,以便尽可能多地删除连接,而不会过多地损害准确性。
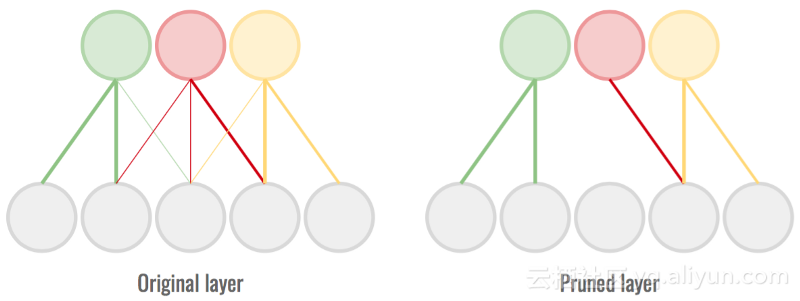
除去最薄弱的连接以节省计算时间和空间。
5.量化权重(Quantizing the weights)
为了将网络保存在磁盘上,我们需要记录网络中每个单一权重的值。这意味着为每个参数保存一个浮点数,这代表了磁盘上占用的大量空间。作为参考,在C中,一个浮点占用4个字节,即32个比特。一个参数在数亿的网络(例如GoogLe-Net或VGG-16)可以轻松达到数百兆,这在移动设备上是不可接受的。
为了保持网络足迹尽可能小,一种方法是通过量化它们来降低权重的分辨率。在这个过程中,我们改变了数字的表示形式,使其不再能够取得任何价值,但相当受限于一部分数值。这使我们只能存储一次量化值,然后参考网络的权重。
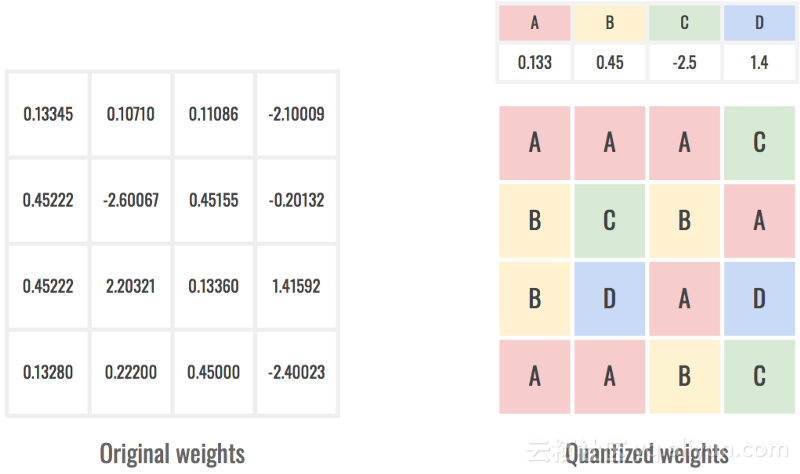
量化权重存储键而不是浮动。
我们将再次通过查找饱和点来确定要使用多少个值。更多的值意味着更高的准确性,但也是更大的储存空间。例如,通过使用256个量化值,每个权重可以仅使用1个字节 即 8个比特来引用。与之前(32位)相比,我们已将大小除以4!
6.编码模型的表示
我们已经处理了关于权重的一些事情,但是我们可以进一步改进网络!这个技巧依赖于权重不均匀分布的事实。一旦量化,我们就没有相同数量的权值来承载每个量化值。这意味着在我们的模型表示中,一些引用会比其他引用更频繁地出现,我们可以利用它!
霍夫曼编码是这个问题的完美解决方案。它通过将最小占用空间的密钥归属到最常用的值以及最小占用空间的值来实现。这有助于减小设备上模型的误差,最好的结果是精度没有损失。
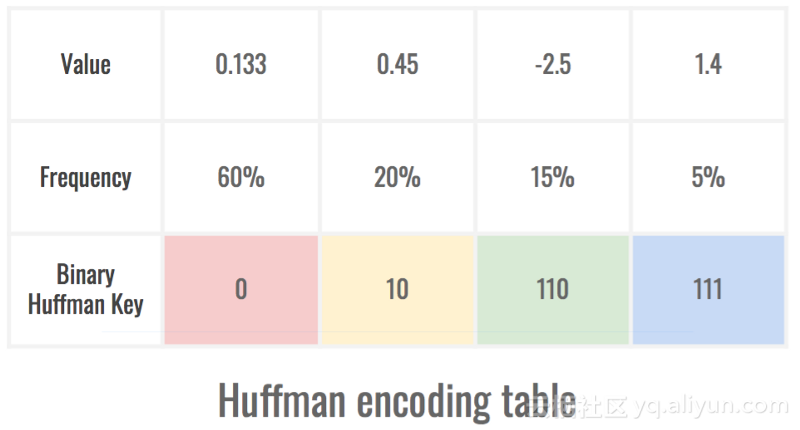
最频繁的符号仅使用1 位的空间,而最不频繁的使用3 位。这是由后者很少出现在表示中的事实所平衡的。
这个简单的技巧使我们能够进一步缩小神经网络占用的空间,通常约为30%。
注意:量化和编码对于网络中的每一层都是不同的,从而提供更大的灵活性
7.纠正准确度损失(Correctiong the accuracy loss)
使用我们的技巧,我们的神经网络已经变得非常粗糙了。我们删除了弱连接(修剪),甚至改变了一些权重(量化)。虽然这使得网络超级轻巧,而且速度非常快,但其准确度并非如此。
为了解决这个问题,我们需要在每一步迭代地重新训练网络。这只是意味着在修剪或量化权重后,我们需要再次训练网络,以便它能够适应变化并重复这个过程,直到权重停止变化太多。
结论
虽然智能手机不具备老式桌面计算机的磁盘空间、计算能力或电池寿命,但它们仍然是深度学习应用程序非常好的目标。借助少数技巧,并以几个百分点的精度为代价,现在可以在这些多功能手持设备上运行强大的神经网络。这为数以千计的激动人心的应用打开了大门。
如果你仍然好奇,请查看一些最好的面向移动的神经网络,如SqueezeNet或MobileNets。
以上是关于智能手机跑大规模神经网络的主要策略的主要内容,如果未能解决你的问题,请参考以下文章