loadrunner--分析图合并
Posted wxinyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了loadrunner--分析图合并相关的知识,希望对你有一定的参考价值。
一、分析图合并原理
选择view->merge graphs,弹出如图1所示对话框
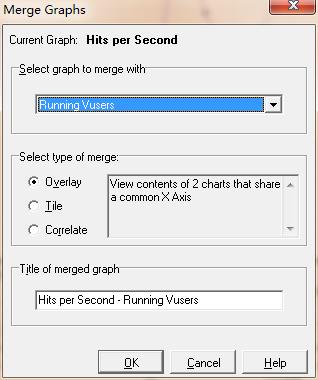
图1(设置合并图)
1、选择要合并的图。选择一个要与当前活动图合并的图,注意这里只能选择X轴度量单位相同的图。
2、选择合并类型。
1)叠加:查看共用同一X轴的两个图的内容。合并图左侧的Y轴显示当前图的Y轴值,右边的Y轴显示合并进来的图的Y轴值,如图2所示
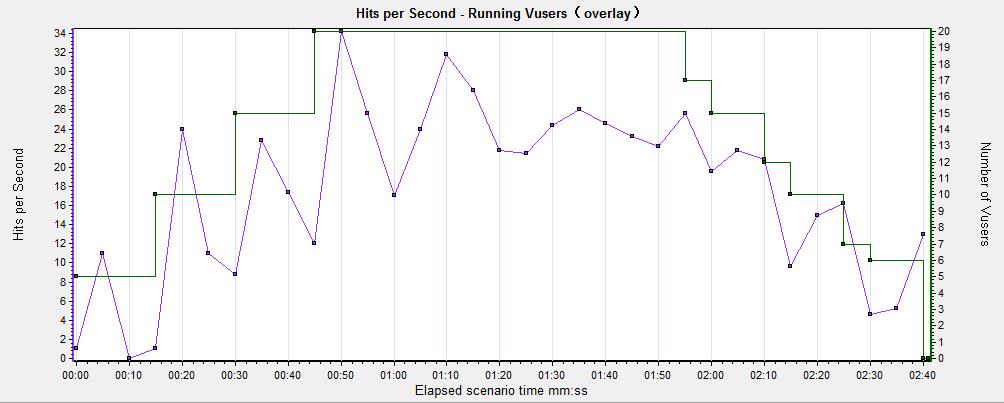
图2(叠加合并分析图)
2)平铺:在平铺布局查看,共用同一个X轴,合并进来的图显示在当前图的上方,如图3所示
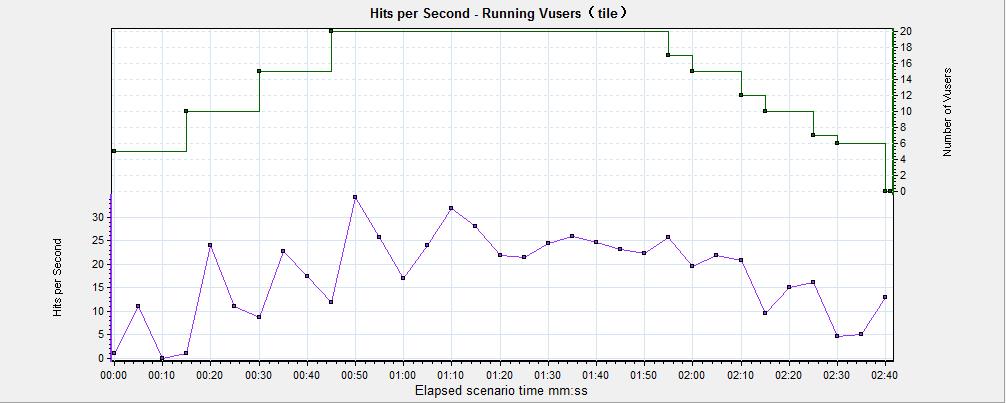
图3(平铺合并分析图)
3)关联:合并后当前活动图的Y轴变为合并图的X轴,被合并图的Y轴作为合并图的Y轴,如图4所示
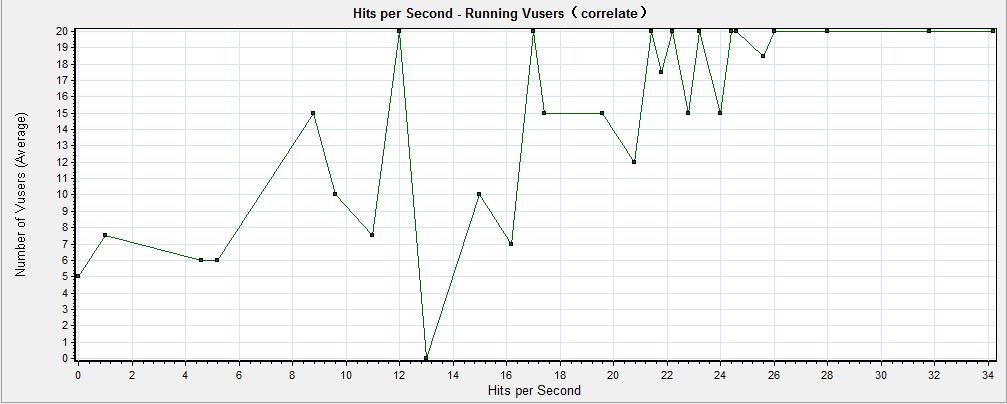
图4(关联合并分析图)
3、合并图标题:设置视图合并后的标题。
二、实例讲解
下面通过一个实例来分析如何对数据图进行合并分析,该图是将 running vusers,hits per second,throughput图,3个图进行叠加合并图分析,如图5所示
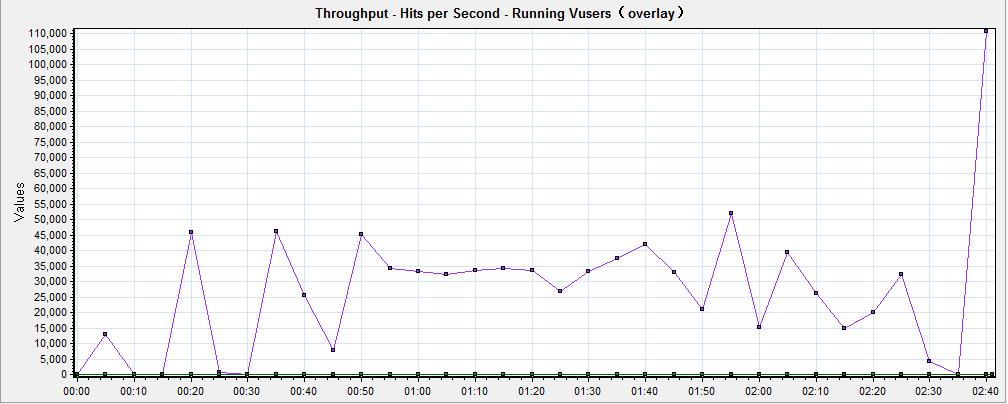
图5(合并后的分析图)
可以发现running vusers和hits per second图几乎看不到。在实际测试过程中可能经常遇到这样的情况,这是因为Y轴的粒度太小影响分析,有时X轴的粒度太小也会影响分析,这时就要调整X轴的粒度或Y轴的显示比例,这里只需调整Y轴的显示比例即可,将running vusers和hits per second图的Y轴放大10000倍,通过view->configure measuerments设置来更改,如图6所示,更改后,如图7所示
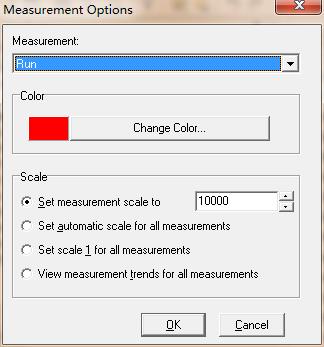
图6(调整Y轴显示比例)
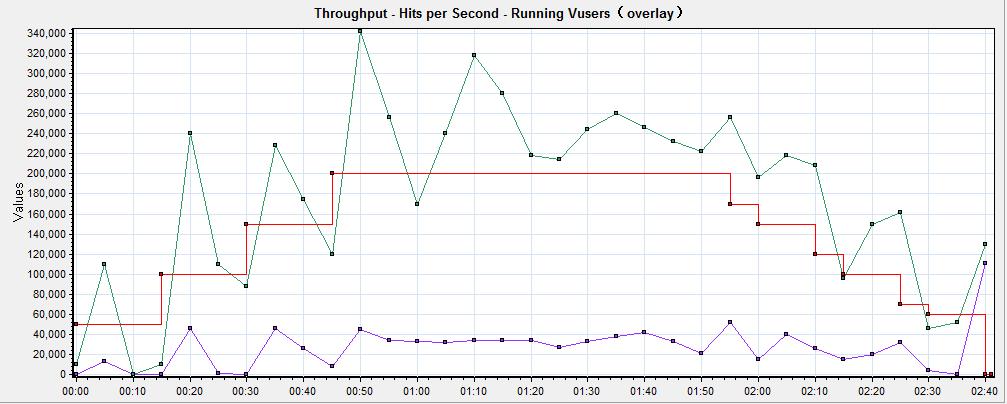
图7(调理Y轴显示比例后的合并分析图)
有时可对分析图进行筛选设置,但在该实例中可不用进行这方面的设置。下面是分析合并图常用的3个步骤,合并完成后要对这个合并图及这3个图的趋势进行分析,主要是分析这3种图的趋势是否正确。
1)找到影响几个图变化趋势的决定因子。在这里先抽出running vusers图来分析,因为其他两个图的变化 是与vuser用户有关;
2)应该了解合并图中其他的图与该决定因子的关系。这里hits per second和throughput与running vusers图是成正比的关系,也就是说,随着vuser用户的增加,每秒点击数和吞吐量都增加;
3)分析决定因子图的变化趋势。running vusers图的变化趋势是先加载vuser用户,当全部加载完成后,所有的vuser用户会运行一段时间,再开始释放vuser用户;
最后,通过各图之间的关系来判断其他的这些图的变化的趋势是否正确。判断hits per second图和throughput图变化趋势,要判断这两个图变化趋势是否与running vusers图变化趋势一致。如果一致,则说明结果分析图是正确的;否则就说明结果是不正确的,如果发现有异常的现象可以再借助其他的分析方法来确定真实的原因。
分析图关联
一、分析图关联原理
在当前的分析图中右击选择auto correlate弹出对话框,如图8所示
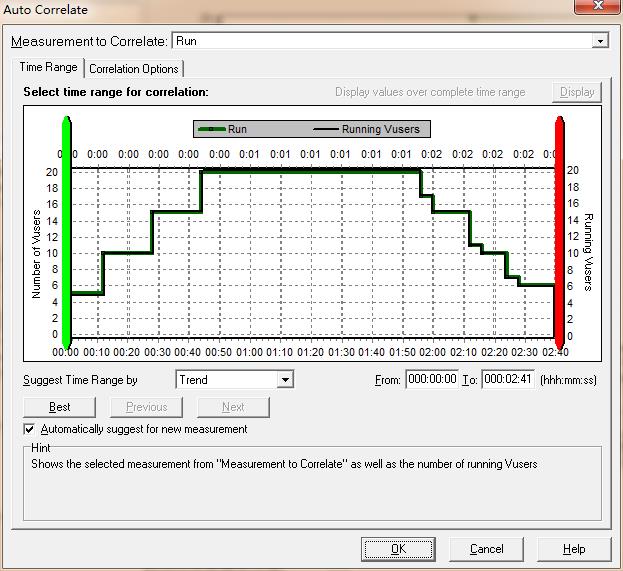
图8(关联图时间范围,这里以running vusers图为例)
1、time range(时间范围)选项卡用来设置分析关联图度量的时间范围
suggest time rang by 有两种时间范围方式:
1)trend(趋势):选择关联度量值变化趋势相对稳定的一段为时间范围
2)feature(功能):在关联度量值变化相对稳定的时间内,选择一段大体与整个趋势相似的时间范围
3)best(最佳):选择关联度量值发生明显变化趋势的一段时间范围
也可以手动调整时间范围,具体有两种方式,一种是手动填写 具体的开始和结束时间;另一种是拖动绿色和红色线来指定起止时间,其中绿色线表示起始时间,红色线表示终止时间
2、correlation optins(自动关联)选项卡可以设置要关联的图、数据间隔和输出选项
在select graphs for correlation 中选择需要关联的图。在data interval组合框中选择计算关联度量轮询之间的时间间隔,可以设置为自动,也可以自定义。在output组合框中选择显示输出的级别。如图9所示
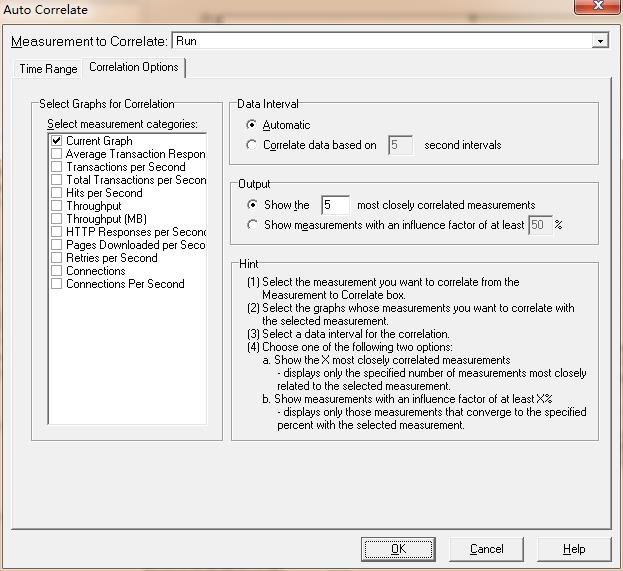
图9(自动关联选项卡)
二、实例讲解
分析图关联是通过复杂的统计学方法,精确定位哪些因素对交易响应时间的影响最大,关联并不关注具体的数据,而是关注于参数样本在特定时间范围内的状态、趋势。只有拆线图可以使用auto correlation(除web page diagnostic拆线图外)。
实例:分析‘平均事务响应时间’与‘正在运行的vuser’图关联的情况。
1)平均事务响应时间图为当前活动图,被关联图为‘正在运行的vuser’图,如图10所示
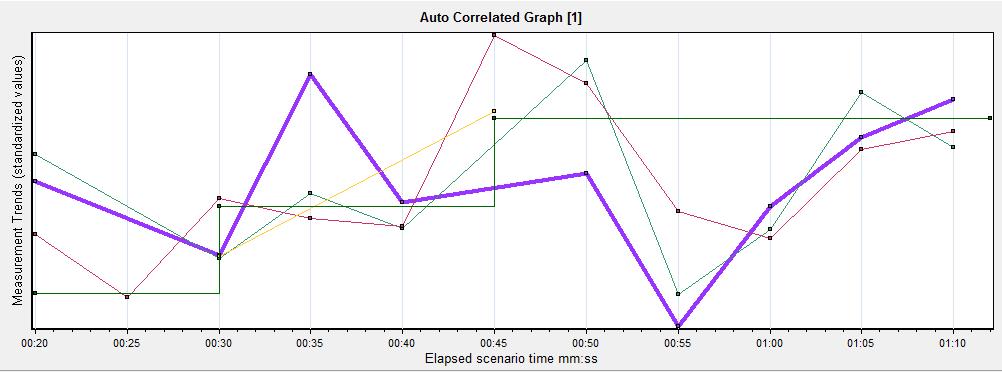
图10(初始关联图)
2)设置过滤条件。自动关联后,会发现很多并不需要的事务也被关联进来了,这时就需要对其进行过滤处理。set filter/group by,如图11所示,这里选择登录事务进行分析。
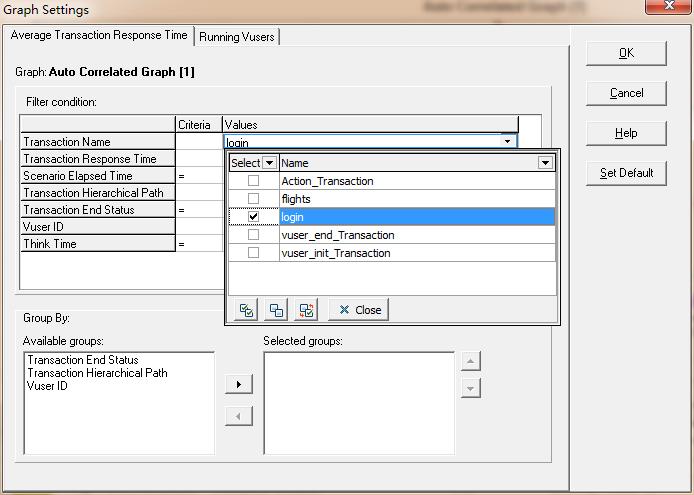
图11(设置过滤条件)
3)设置分析关联的时间范围。在过滤后的关联图中右击,选择auto correlation,如图12所示,可以手动设置关联分析的时间范围,但需要注意的是, 在这里要选择波折的地方进行分析,并且不能只选择只有一个波折的时间范围,至少要选择一段有两个以上波折的曲线。如果只选择一个波折,在自动关联后,会发现很多项的关联度都为100。这个分析就没有意义,因为只选择一个波折的时间范围太小。
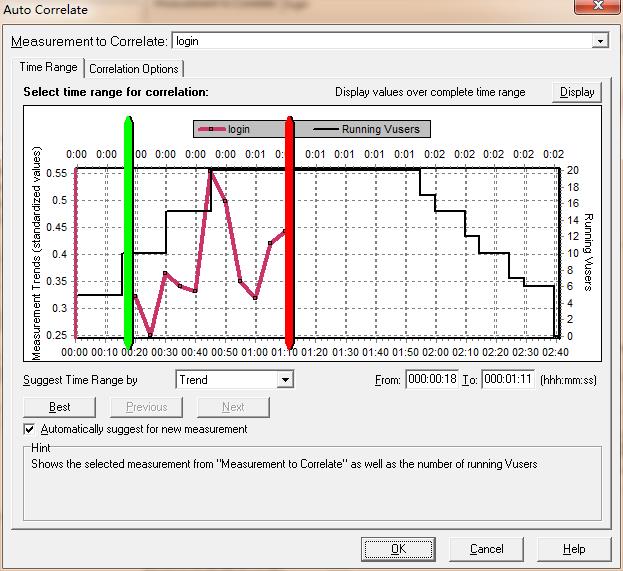
图12(设置时间范围)
4)分析关联度。自动关联后会看到下面列出所有关联度的信息,选择关联度最高的来分析。如图13所示

图13(分析关联度)
到这里整个关联分析就结束了,可以看出auto correlation和merge存在一些共同点,但同时也存在一些区别,具体区别如下:
a.merge不能选择特定的时间进行切片,所以只有先用merge看整体趋势、分析全局。找到恰当的位置后,再使用auto correlation切片,进一步分析;
b.merge的输出没有correlation match这个值,即使使用merge的correlate选项也没有correlation match这个值,也就不能衡量两个参数之间的关系。
页面细分
一、页面细分原理
在平均事务图中右击,在弹出的快捷菜单中选择show transaction breakdown tree,生成web page diagnostics图。通过分解页面可以发现,页面中哪些组件响应时间较长?平均事务响应时间过长是由服务器还是由网络环境引起的?页面细分的具体内容如图14所示
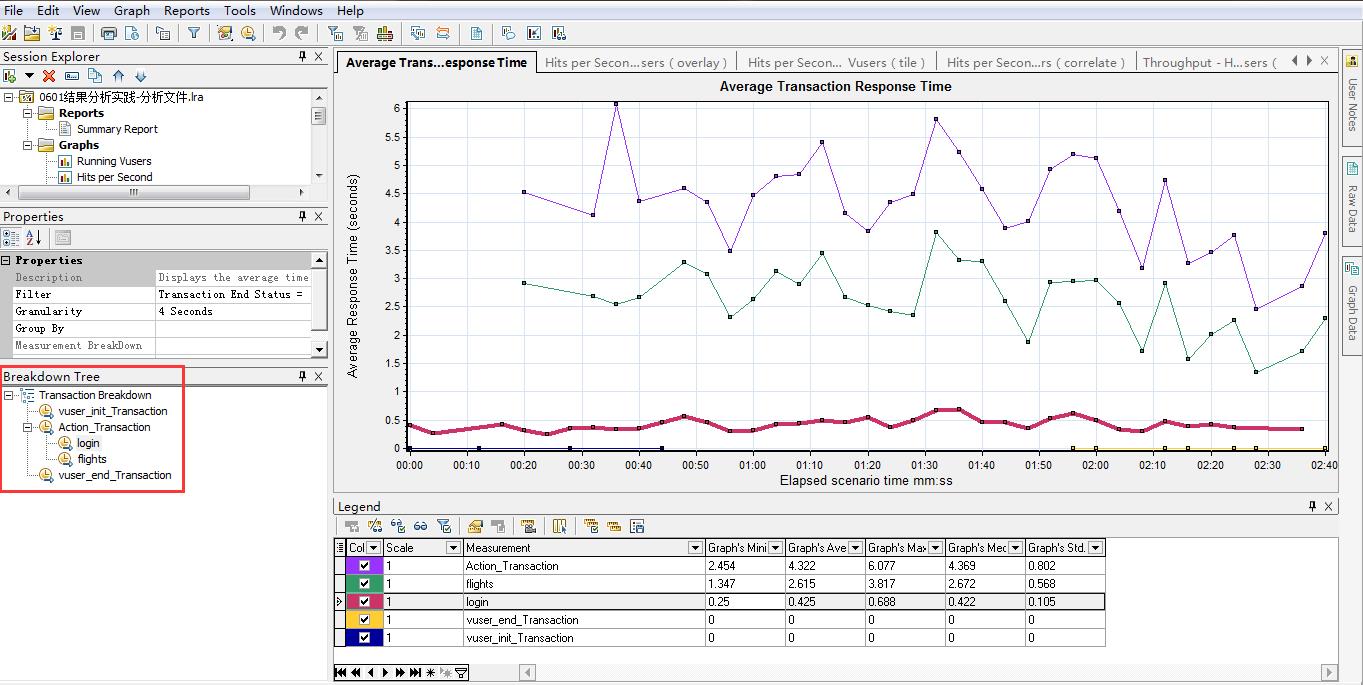
图14(事务包含页面图)
正常的从浏览器发送一个请求到最后显示,整个过程由图15所示的时间片组成:

图15(网络时间解析图)
1)浏览器向服务器发送一个请求,一般情况下,客户端的请求首先被发送到DNS服务器上,通过域名解析,将DNS名解析为IP地址。其中域名解析的时间就是DNS解析的时间(DNS Resolution)。通过这个时间可以确定DNS服务器或DNS服务器的配置是否有问题。如果DNS服务器运行情况良好,这个时间会比较小。
2)DNS解析完成后,请求被送到web服务器,之后浏览器与web服务器之间需要建立一个初始化连接。建立连接的过程就是连接时间(Connection)。 这样通过这个时间就只可以判断网络的情况,也可以判断web服务器是否能够响应这个请求。如果正常,这个时间会比较小。
3)建立连接后,web服务器发出第一个数据包,经过网络传输到客户端,浏览器成功接收到第一个字节的时间就是first buffer的时间。这个度量时间不仅可以表示web服务器的延迟时间,还可以表示网络反应时间。
4)从浏览器接收到第一个字节起,直到所有的字节都成功接收为止。这个度量可以判断网络的质量(可以用size/time比来计算接收速率),其他的时间还有SSL Handshaking(SSL握手协议,用到该协议的页面比较少)、client time(请求在客户端浏览器延迟时间,可能是由于客户端浏览器的think time 或者客户端其他方面引起的延迟)、error time (从发送一个HTTP请求,到web服务器发送回一个HTTP错误信息所需要的时间)。
在legend区域中,可以选择需要的页面进行分析,如选中login事务->右键web page diagnostics,在web page diagnostics中显示了该页面运行时的响应时间,diagnostics options中显示了该页面包含的所有组件,以及组件的大小和组件下载的时间,如图16所示
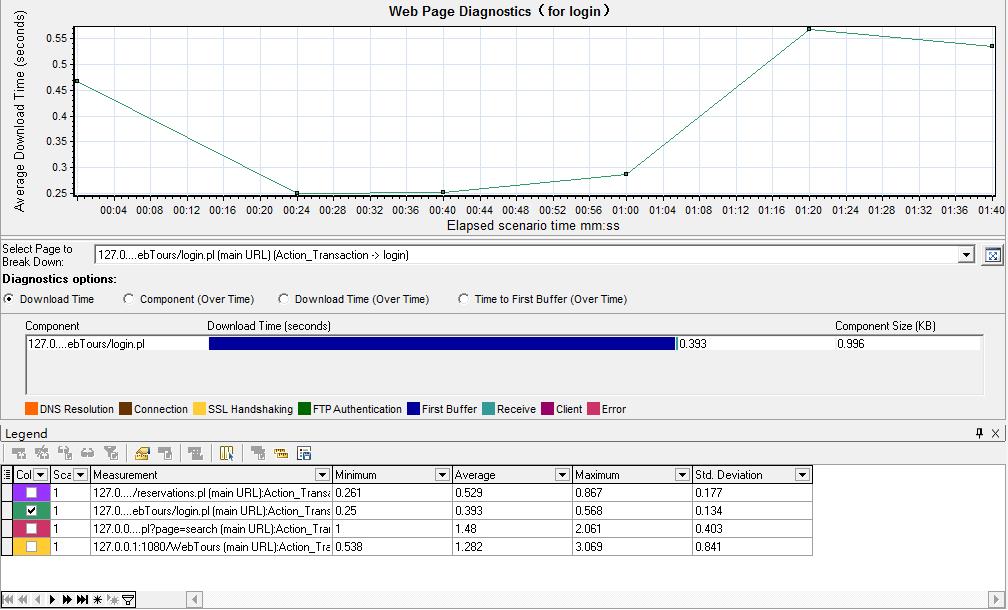
图16(download time时间图)
component(over time)显示了各组件在场景运行过程中下载的时间,如图17所示,可以通过 按钮来切换是只显示选中组件的下载时间还是显示所有组件的下载时间。
按钮来切换是只显示选中组件的下载时间还是显示所有组件的下载时间。

图17(各组件下载时间图)
download time(over time)可以看到在场景运行时,组件在网络传输过程中的各部分时间,如图18所示

图18(各组件运行时间图)
为了确定问题是由服务器还是由网络引起的,time to first buffer(over time)图显示了在网络传输过程中和服务器两部分分别使用的时间。

图19(first buffer时间图)
二、实例讲解
页面分析技术主要是用来分析失败事务是由哪些组件引起的,步骤如下:
1)打开需要分析的图,对过滤条件进行设置,如图20所示
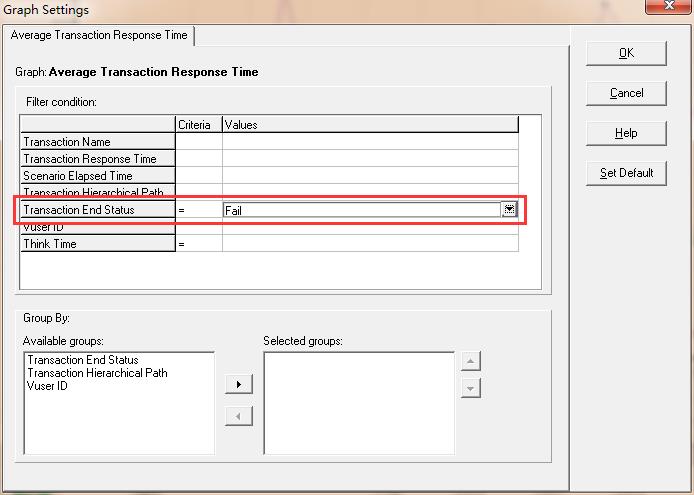
图20(设置过滤条件)
2)显示事务细分树,即在图中右击选择show transaction breakdown tree,选择后会显示出所有失败事务图。
3)显示页面细分图,即选择需要分析的事务,右击选择web page diagnostics后,analysis分析器生成web page diagnostics图。
4)查看download time 图,即选择download time查看各组件所花费的时间。
5)手动查看该组件响应时间,即选中该组件右击选择copy the full path to the clipboard,将路径复制到IE浏览器中进行预览。或选择view page browser直接打开该页面进行预览。手动预览能判断该页面响应的真实时间。如果手动预览该页面和测试的结果一致,则说明事务失败确实是由于该页面响应时间引起。如果不是手动预览响应很快,那么要进一步判断是由测试环境引起还是由网络引起。
6)查看download time (over time)图,图中详细地记录了请求在各阶段所花费的时间。
7)查看time to first buffer(over time)图,通过该图观察问题到底是由服务器引起还是由网络引起。
以上就是整个分析过程。
钻取技术
钻取技术特点:
1)在一个活动图中,选择一个需要的组进行显示,这时钻取技术可以帮助进行特定的测量;
2)组信息由当前活动图所决定,对于不同的图,组信息有所不同;
3)可以钻取每个vuser的平均事务响应时间,并可以按vuserid进行排序;
4)钻取后的信息会按组中不同的元素与不同的曲线显示出来,如不同的vuserid显示不同的曲线图。
钻取技术实例步骤:钻取测试结果中哪些vuserid执行事务失败
1)对平均事务响应时间图进行过滤,过滤出失败的事务图,有一些图不需要过滤,直接用即可,如每秒点击率图。
2)过滤后右击选择drill down,弹出如图21对话框,选择要钻取的事务和组信息
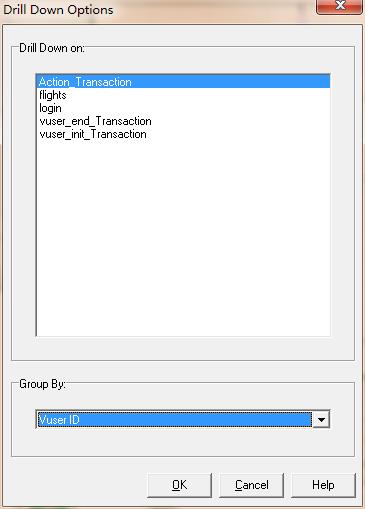
图21(钻取属性设置)
3)钻取后,如图22所示,会显示所有vuserid对应的信息
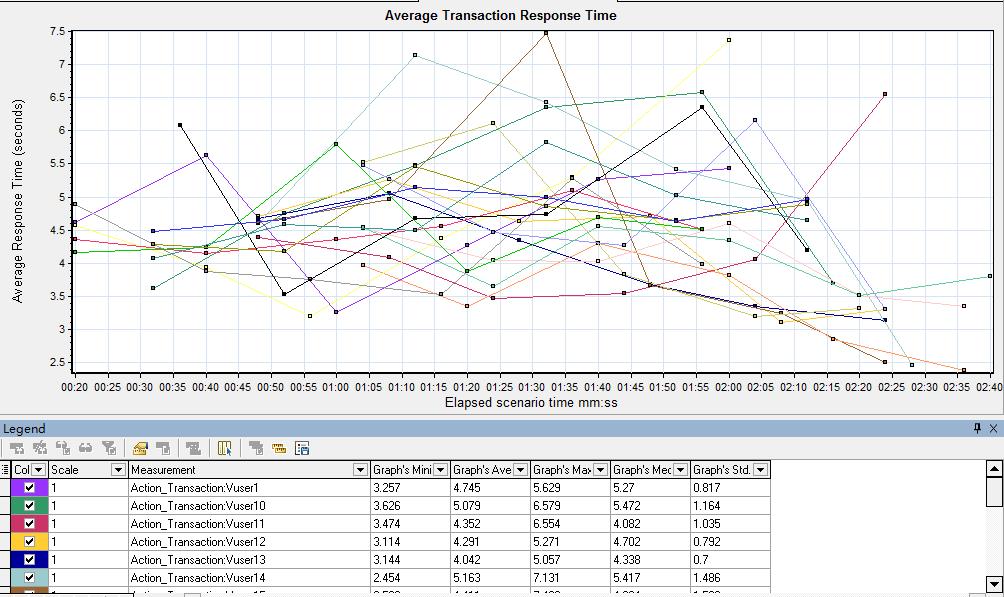
图22(vuserid信息)
4)钻取后,可以选择不同的组,对当前钻取的结果再次进行钻取,得到更多的信息,或者在properties中的group by中设置group by 条件。
以上就是整个钻取过程,钻取后应该借助其他的手段来帮助进行更深层次的分析,才能找到系统真正的瓶颈。
导入外部数据
通过lr analysis导入数据,可以将非mercury interactive数据导入并集成到lr analysis会话中,完成导入操作后,可以使用analysis工具的所有功能以图的形式查看会话中的数据文件。
假如一个NT性能监视器在服务器上运行,并对其行为进行度量。在服务器上执行LR方案后,可以检索性能监视器的结果,并将数据集成到LR的结果中,这样能够将两数据集的趋势和关系相关联。
1、导入数据工具
LR自带的导入工具,tools->external monitors->import data,如图23所示
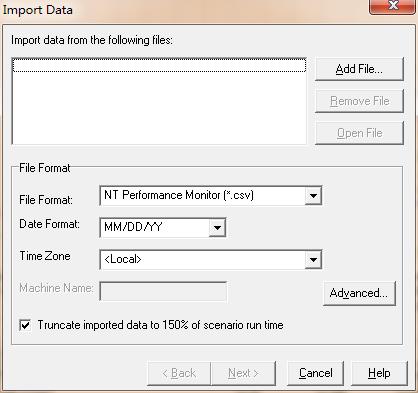
图23(导入数据)
详细的操作就不说了,以后有需要用到的时候,再来细说。
备注:文字讲解来自《深入性能测试--LoadRunner性能测试、流程、监控、调优全程实战剖析》(黄文高、何月顺编著)一书,我是新手,参照此教程做了下实践,顺便将学到的东西写下来。
以上是关于loadrunner--分析图合并的主要内容,如果未能解决你的问题,请参考以下文章