利用selenium爬取淘宝美食内容
Posted 积土成山,风雨兴焉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用selenium爬取淘宝美食内容相关的知识,希望对你有一定的参考价值。
1、启动pycharm
首先咱们新建一个项目名字大家可以自己设定
接着新建一个spider.p文件
#author: "xian"
#date: 2018/5/4
import re #导入re库
from selenium import webdriver #导入selenium库
from selenium.common.exceptions import TimeoutException #导入超时异常处理模块
from selenium.webdriver.common.by import By #查找元素
from selenium.webdriver.support.ui import WebDriverWait #等待页面加载
from selenium.webdriver.support import expected_conditions as EC #预定义条件供WebDriverWait调用
from pyquery import PyQuery as pq #导入pyquery解析网页源代码
import pymongo #导入pymongo库用于操作mongddb数据库
MONGO_URL = \'localhost\' #指定本机的mongodb数据库
MONGO_DB = \'taobao\' #指定数据库名称为taobao
MONGO_TABLE = \'meishi\' #指定存储表名称为meishi
client = pymongo.MongoClient(MONGO_URL) #创建一个连接
db = client[MONGO_DB] #访问一个名为taobao的数据库并赋值给本地变量db
browser = webdriver.Chrome() #驱动Chrome浏览器
wait = WebDriverWait(browser,10)#设置等待时间为10s并赋值给wait变量
#定义一个搜索函数search
def search():
#异常处理模块 try ... except...
try:
browser.get(\'https://www.taobao.com\') #请求淘宝首页
#显示选择具体见官网:http://selenium-python-zh.readthedocs.io/en/latest/waits.html#id2
# 以下用CSS选择器设定等待条件
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, \'#q\')) #EC.*** ,***为加载条件 具体小伙伴们参见官方文档即可
)
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,\'#J_TSearchForm > div.search-button > button\')))
#用CSS选择器(打开chrome找到输入框右键审查元素右击copy css selector 复制即可 )
#设定Action Chains即动作链
input.send_keys(\'美食\') #相当于输入关键字:美食
submit.click() #相当于模拟点击动作
total = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'#mainsrp-pager > div > div > div > div.total\'))) #加载全部页面
get_products() #执行具体商品解析函数
return total.text #获取文本内容
except TimeoutException: #引入timeout异常
return search() #如果超时将再请求一次
#执行翻页操作函数
def next_page(page_number):
try:
input = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, \'#mainsrp-pager > div > div > div > div.form > input\')))
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, \'#mainsrp-pager > div > div > div > div.form > span.btn.J_Submit\')))
input.clear() #清空框中内容,方便重新填入 (比如你先填了2 就翻到第二页,现在我当然先清空内容,再填入3才能进入第3页)
input.send_keys(page_number)
submit.click()
wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR,\'#mainsrp-pager > div > div > div > ul > li.item.active > span\'),str(page_number)))
get_products()
except TimeoutException:
next_page(page_number)
#商品详情解析函数
def get_products():
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,\'#mainsrp-itemlist .items .item\')))
html = browser.page_source
doc = pq(html)
items = doc(\'#mainsrp-itemlist .items .item\').items() #参见官网http://pyquery.readthedocs.io/en/latest/api.html
for item in items:
#以下使用pyquery选择器选择元素
product = {
\'image\':item.find(\'.pic .img\').attr(\'src\'),
\'price\':item.find(\'.price\').text().replace(\'\\n\',\'\'),
\'deal\':item.find(\'.deal-cnt\').text()[:-3],
\'title\':item.find(\'.title\').text().replace(\'\\n\',\'\'),
\'shop\':item.find(\'.shop\').text(),
\'location\':item.find(\'.location\').text(),
}
print(product)
save_to_mongo(product)
#存储到mongodb数据库
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print(\'存储到mongodb成功!\',result)
except Exception:
print(\'存储到mongodb失败!\',result)
#主函数
def main():
total = search() #打印结果为:共100页
total = int(re.compile(\'(\\d+)\').search(total).group(1)) #使用正则表达式抽取其中的数字100 int()将字符串转为整数
for i in range(2,total + 1):
next_page(i)
browser.close()
#该函数的作为为只在当前py执行,方便调试
if __name__ == \'__main__\':
main()
运行结果:

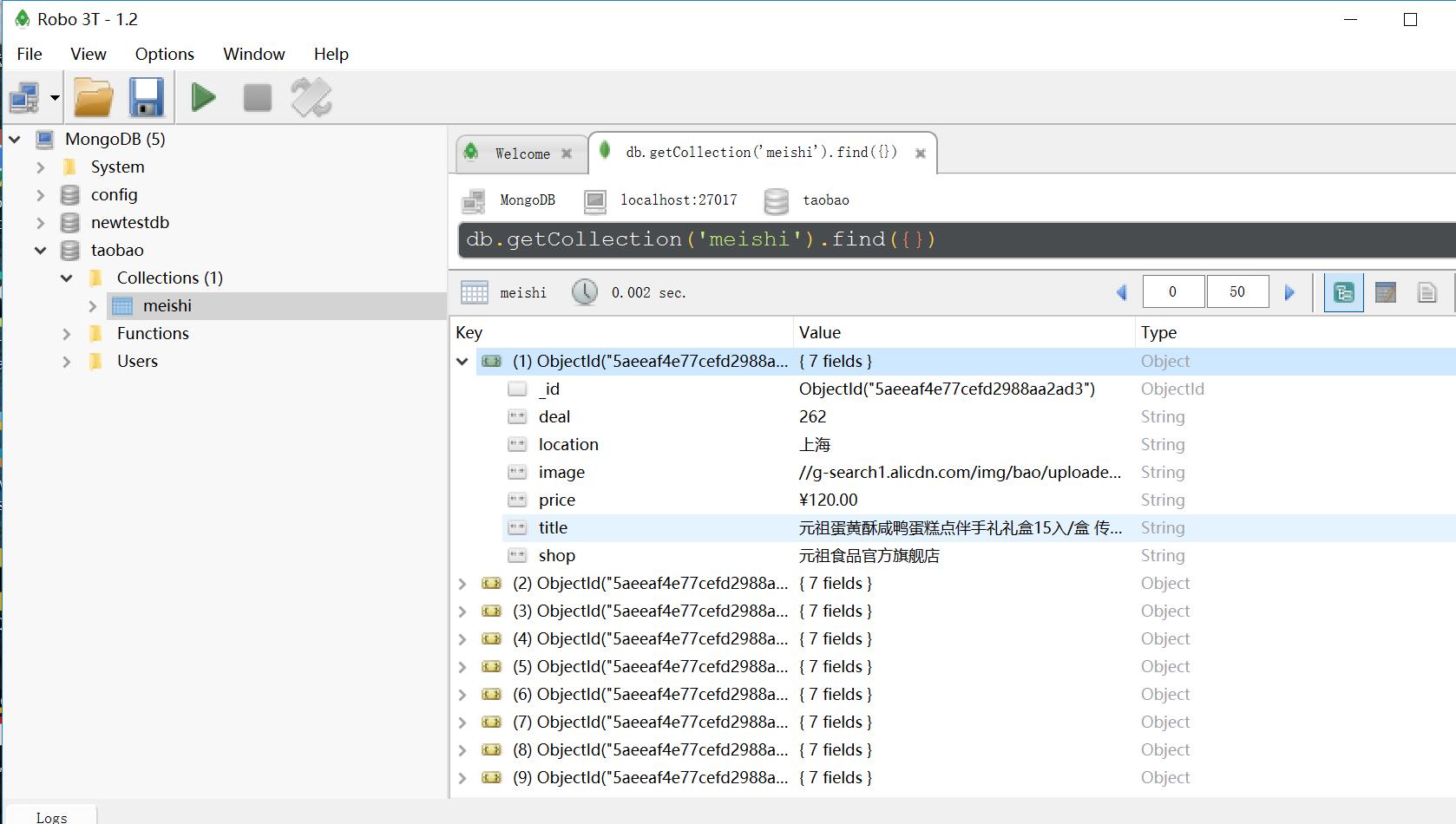
小伙伴们可是将其中的美食字样该为其他想要获取的淘宝商品数据尝试运行下,是不是挺有意思的,哈哈!

以上是关于利用selenium爬取淘宝美食内容的主要内容,如果未能解决你的问题,请参考以下文章