tarjan 强连通分量
Posted Tswaf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tarjan 强连通分量相关的知识,希望对你有一定的参考价值。
一、强连通分量定义
有向图强连通分量在有向图G中,如果两个顶点vi,vj间(vi>vj)有一条从vi到vj的有向路径,同时还有一条从vj到vi的有向路径,则称两个顶点强连通(strongly connected)。如果有向图G的每两个顶点都强连通,称G是一个强连通图。有向图的极大强连通子图,称为强连通分量(strongly connected components)SCC。
以上是摘自百科的一段对有向图强连通图分量的形式化定义。其实不难理解,举个例子

如上图,{a,b,c,d}为一个强连通分量,{e}为一个强连通分量,{f}为一个强连通分量。
二、SCC求解算法
给定一个有向图,如何求它的强连通分量呢?
一般有两种算法:
1、kosaraju算法:该算法分别对图G和其转置GT做dfs,第一次对G做dfs确定出各个强连通分量之间的拓扑序,第二按照拓扑逆序对G(T)做dfs,这样每次dfs都得到一个强连通分量。算法复杂度为O(V+E)。
2、tarjan算法:tarjan算法也是基于dfs求解SCC,与kosaraju通过拓扑序做dfs使得各个SCC“互不干涉”的思想不同,tarjan算法只对原图做一次dfs,运行各个SCC在dfs过程中“交织在一起”,并且在dfs过程中记录一些节点信息,通过这些信息识别出一个个SCC。算法复杂度为O(V+E)。
相比而言,tarjan算法不需要对图做转置,而且只做一次dfs,所以执行效率更高。
本文主要梳理tarjan 强连通分量算法。
三、dfs相关概念
tarjan算法本身是一个dfs算法,用到了dfs的一些性质,所以具体展开tarjan SCC算法之前,先来梳理一些相关的基础。
1、搜索树(森林):对一个图做dfs搜索,搜索过程形成一颗搜索树。
2、节点访问次序d[i]: dfs过程中,按照节点访问到的顺序个每个节点记录一个值d[i]。另外,也可以对每个节点记录访问完成的次序f[i]。
3、dfs对边的分类:
树边:搜索过程中自然形成的边。如果通过节点i dfs搜索其邻居节点j时,发现j之前还未被访问,在dfs搜索j,这时边<i,j>形成搜索树种一条搜索经过的边,称作树边
反向边:搜索过程中后裔指向祖先的边。如果通过节点i dfs搜索其邻居节点j时,发现j在搜索树中是i的祖先(j已经被dfs搜索到,但是还没递归返回),这时边<i,j>是反向边。
正向边:搜索过程中祖先指向后裔的边。
交叉表:搜索过程中不同子树之间的边。
一条性质:在dfs过程中,通过节点i遍历邻居j时候,如果j已经被之前访问到(不一定递归访问完成)且d[i]>d[j]则边<i,j>是一条反向边或交叉边。这条性质在tarjan算法中会用到。
注:关于dfs及dfs对边的分类等知识,《算法导论》中有详细的描述,这里只列出对本文讲解tarjan算法相关的内容。
下图是对以上概念的一个解释:
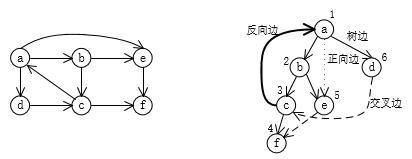
图中左边是原图,右边是一棵dfs搜索树,标注了节点d[i]值和都边的分类。根据dfs访问节点顺序不同,搜索树、d[i]已经边的分类也会不同,但并不影响相关的性质。
四、tarjan SCC算法
理解了一些基础概念,现在还看看tarjan求解强连通分量的算法。水平有限,关于算法的形式化证明不会涉及,只会阐述算法的思想和过程。
算法基本思想
tarjan算法的思想基于以下性质
a)如果节点i和节点j在同一个强连通分类中,那么它们在搜索树中会有共同的祖先
b) 强连通分量在搜索树中形成一棵子树。
先上图直观理解下:
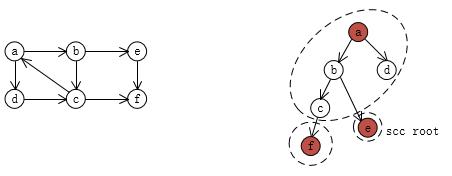
对于性质a)我们可以看到,{a,b,c,d}是一个SCC,在搜索树中,它们之中任意两个节点都是有共同祖先的。
性质b)是性质a)的自然推论,可以看到,三个SCC {a,b,c,d} {e} {f} 都对应搜索树中的一个子树,用虚线框了起来。
其实不难理解性质的正确性,想象一下dfs的过程,一旦dfs访问到SCC中的一个节点,这个SCC中的所有节点后续都会都访问到,应为它们是相互可达的。这样的话,一个SCC中任意两个节点拥有一个共同祖先就是肯定的了,因为最坏的情况下,它们的共同祖先可以是这个SCC中第一个被访问到的节点。以上图为例,c和b有个公共祖先b,c和d用公共祖先a,a作为该SCC中第一个被dfs访问到的节点,可以作为任意两个节点的公共祖先。这样的话性质a)就是正确的,至于性质b),就是性质a)的自然推论了,同一SSC中的节点都有一个共同的祖先(第一个比访问到的节点),不就是一个子树嘛。
上图中红色节点标志了一个子树的根,称为scc root,它是所在的SCC中第一个被dfs遍历到的节点。
理解了上面两条性质,已经基本上可以看出tarjan算法求解SCC的基本思想了:既然每个SCC都是一个搜索树的一个子树,那么找到子树的根,从搜索树中“摘下”一个子树,不就是一个SCC吗?问题是,怎么找到子树根呢?
求解
定义以下变量:
d[i]:节点i的访问顺序,上文已提到;
low[i]: 节点i 通过零或多条树边 之后,再经过至多一条 反向边或交叉边 所能到达的同一个SCC中的最早访问的节点k的访问次序d[k]。
根据low[i]的定义,其计算过程如下:
low[i] = min{low[i],low[j]} : 如果<i,j>是树边,根据定义j能到达那个节点,i通过树边<i,j>之后也可以到达
low[i] = min[low[i],d[j]]: 如果<i,j>是反向边或交叉边,根据定义,i只能到达j值,因为路径上只允许有最多一条反向边或交叉边,而且是以该边结束的。
注:正向边不影响SCC连通性tarjan算法不考虑正向边。
绕口的一B是吧,看个例子:
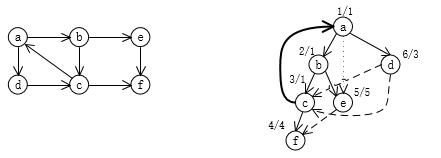
如图: 节点上标注了d[i]/low[i]。{a,b,c,d}是一个SCC,节点b经过一条树边和一条反向边可以到达同一个SCC中的最早访问节点a,节点d[i]值为1,所以low[b]=1; 节点d经过0条树边,一条交叉边后可以到达达同一个SCC中的最早访问节点c,节点c的d[i]值d[c]=3,所以low[d]=3。
有了以上定义之后,tarjan算法有一条关键的定理:
定理: d[i]=low[i] <=> 节点 i 是一个scc root
该定理的严格形式化证明可以参考下论文原文。其实简单理解就是,同一个SCC中的节点只有scc root 满足d[i]=low[i],为什么呢?
考虑同一个SCC中的节点,分两个情况:
1、对于scc root节点,显然满足d[i]=low[i]
2、对于其他节点,一定low[i]<d[i]。再分成两种情况考虑:
2.1、节点i通过反向边(无论是直接一条反向边或通过它的子节点)访问到了自己的祖先k,则low[i]=d[k], k值i的祖先,所以d[i]<low[i]。如上图中的c或d,它们都通过反向边(包含树边)可以到达祖先a;
2.2、节点i通过交叉边到达同一个scc中的节点:通过交叉边到达节点k,有low[i]=d[k],最好的情况下k是scc root,或者一个情况下k值ssc中其他节点,无论哪种情况,由于k之前已经被访问到,所以low[i]=d[k]<d[i]。如上图中的节点d,通过交叉边到达c。
通过以上两点,就可以证明在一个SCC中,只有scc root满足 d[i] = low[i] 。
上文说过了,tarjan算求解SSC已经转换为求解scc root的问题,而这条定理给出了scc root的求解方法,至此,整个流程就通了: dfs遍历原图,递归计算low[i],节点i递归遍历完成后,如果发现d[i]=low[i]则,找到了一个SCC,当然,这其中还涉及到找到scc root之后,如何根据scc root 得到一个scc的问题,其实tarjan算法dfs过程中,用栈来记录访问到的节点,找到scc root之后,从栈顶一次弹出节点,直到遇到scc root节点,便可构成一个scc,下面的算法实现描述了这一过程。
实现
1、首先看一下tarjan论文中的伪代码实现,个人加了相关注释:
原文的 NUMBER对应本文中d[i], LOWLINK对应本文中low
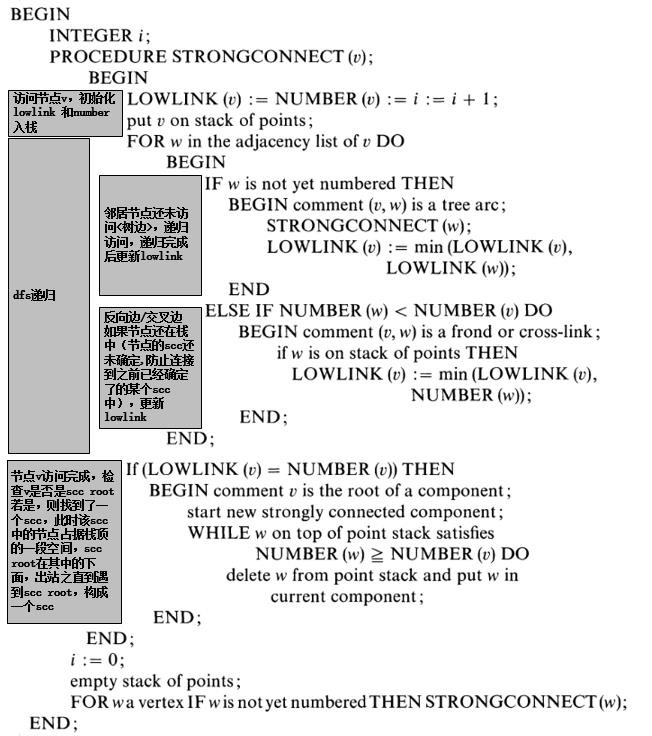
2、java实现:
//dfs过程中节点状态


1 1 public enum Status { 2 2 NOT_VISIT,VISITING,VISITED; 3 3 }
//SCC 数据结构
1 1 public class SccMeta { 2 2 private int sccCount; 3 3 private List<List<Node>> sccList; 4 4 5 5 public SccMeta(){ 6 6 this.sccCount = 0; 7 7 this.sccList = new ArrayList<>(); 8 8 } 9 9 10 10 public int getSccCount(){ 11 11 return sccCount; 12 12 } 13 13 14 14 public List<List<Node>> getSccList(){ 15 15 return sccList; 16 16 } 17 17 18 18 public void addScc(List<Node> scc){ 19 19 this.sccList.add(scc); 20 20 this.sccCount++; 21 21 } 22 22 23 23 @Override 24 24 public String toString(){ 25 25 StringBuilder s = new StringBuilder(); 26 26 s.append("Strongly Connected Componnet:").append("\\n"); 27 27 for(int i=0; i< sccCount; i++){ 28 28 s.append("scc " + i+":"); 29 29 s.append(sccList.get(i).toString()); 30 30 s.append("\\n"); 31 31 } 32 32 return s.toString(); 33 33 } 34 34 }
//tarjan scc 主函数,依次遍历每一个未访问的节点
1 1 public SccMeta scc() { 2 2 initScc(); 3 3 SccMeta sccMeta = new SccMeta(); 4 4 int nodeNum = size(); 5 5 for(int i=0; i<nodeNum;i++){ 6 6 if(status[i] == Status.NOT_VISIT){ 7 7 tarjan(i, sccMeta); 8 8 } 9 9 } 10 10 return sccMeta; 11 11 }
//tarjan 递归过程
1 private void tarjan(int i,SccMeta sccMeta){ 2 low[i] = d[i] = timer++; 3 stack.push(i); 4 status[i] = Status.VISITING; 5 List<Integer> neighbors = adjacencyList.get(i); 6 for(int j : neighbors){ 7 if(status[j] == Status.NOT_VISIT){ // 节点j未访问,边<i,j>是树边 8 tarjan(j, sccMeta); 9 low[i] = Math.min(low[i],low[j]); 10 }else if(d[i] > d[j]){ // 节点j节点j已经被访问过,<i,j>是反向边或交叉边 11 if(stack.contains(j)){ 12 low[i] = Math.min(low[i],d[j]); 13 } 14 }else{ 15 //节点j已经被访问过,而且<i,j>是前向边,忽略 16 } 17 } 18 status[i] = Status.VISITED; 19 20 if(d[i] == low[i]){ // node i is a ssc root 21 List<Node> scc = new LinkedList<>(); 22 int k; 23 do{ 24 k = stack.pop(); 25 scc.add(getNode(k)); 26 }while(k != i); 27 sccMeta.addScc(scc); 28 } 29 }
算法执行过程演示
图中用不同颜色表示节点访问的不同节点,绿色为当前访问节点,灰色为访问中的节点(还未递归返回),黑色为递归访问完成的节点
1、原图

2、dfs访问到c,遇到反向边


4、访问节点f完成,得到一个SCC {f}

5、节点c递归访问完成,递归回退到b
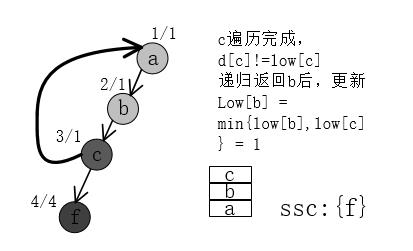
6、访问e遇到交叉边;e访问完成后得到第二个SCC {e}

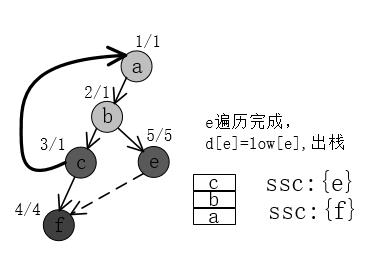
7、节点b递归访问完成
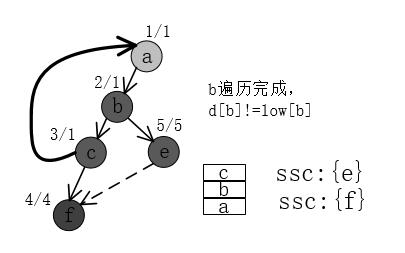
8、访问d遇到交叉边;d访问完成
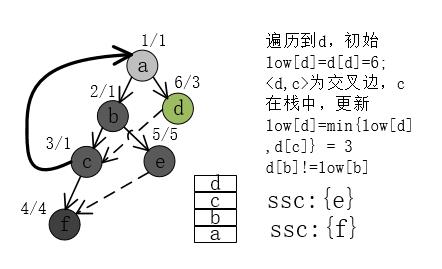

9、a递归访问完成,得到第三个SCC {a,b,c,d}

五、总结
本文介绍从定义、算法思想、实现和演示介绍了tarjan求解强连通分量算法。对算法的整体思想和流程算是有比较清晰的描述了,但是算法的严格形式化证明,水平有限就涉及了,感兴趣的可以参考下tarjan原论文。
附录:
1、tarjan算法论文:DEPTH-FIRST SEARCH AND LINEAR GRAPH ALGORITHMS
2、本文中算法的java实现放在github:https://github.com/Tswaf/algorithm/tree/master/src/graph
以上是关于tarjan 强连通分量的主要内容,如果未能解决你的问题,请参考以下文章