十五 awk文本处理
Posted 钟桂耀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十五 awk文本处理相关的知识,希望对你有一定的参考价值。
Awk 语法和基础命令
以行为处理单位 对数据进行逐行处理 处理完当前行,把当前行的处理结果输出后自动对下一行进行处理 直到文件中所有行处理完为止
创造者:Aho、Weinberger、Kernighan
基于模式匹配检查输入文本,逐行处理并输出
通常用在Shell脚本中,获得指定的数据
单独用时,可对文本数据做统计
下面是 AWK 的几个变种:
AWK 是最原始的 AWK。 NAWK 是 new AWK GAWK 是 GNU AWK。所有 linux 发行版都默认使用 GAWK,它和 AWK 以及 NAWK完全兼容
本书示例将用到下面三个文件,请先建立它们,然后用它们来运行所有示例。
employee.txt 文件
employee.txt 文件以逗号作为字段分界符,包含 5 个雇员的记录
[root@ceph-node5 ~]# vim employee.txt 101,John Doe,CEO 102,Jason Smith,IT Manager 103,Raj Reddy,Sysadmin 104,Anand Ram,Developer 105,Jane Miller,Sales Manager
tems.txt 文件
items.txt 是一个以逗号作为字段分界符的文本文件,包含 5 条记录
[root@ceph-node5 ~]# vim items.txt 101,HD Camcorder,Video,210,10 102,Refrigerator,Appliance,850,2 103,MP3 Player,Audio,270,15 104,Tennis Racket,Sports,190,20 105,Laser Printer,Office,475,5
items-sold.txt 文件
items-sold.txt 是一个以空格作为字段分界符的文本文件, 包含 5 条记录。每条记录都是特定
商品的编号以及当月的销售量(6 个月)。因此每条记录有 7 个字段。 第一个字段是商品编号,
第二个字段到第七个字段是 6 个月内每月的销售量。
[root@ceph-node5 ~]# vim items-sold.txt 101 2 10 5 8 10 12 102 0 1 4 3 0 2 103 10 6 11 20 5 13 104 2 3 4 0 6 5 105 10 2 5 7 12 6
语法格式
Awk –Fs \'/pattern/{action}\' input-file(或者)Awk –Fs \'{action}\' input-file
上面语法中:
-F 为字段分界符。如果不指定,默认会使用空格作为分界符。 /pattern/和{action}需要用单引号引起来。 /pattern/是可选的。如果不指定, awk 将处理输入文件中的所有记录。如果指定一个模式, awk 则只处理匹配指定的模式的记录。 {action} 为 awk 命令,可以是单个命令,也可以多个命令。整个 action(包括里面的所有命令)都必须放在{ 和 }之间。 Input-file 即为要处理的文件
下面是一个演示 awk 语法的非常简单的例子:
[root@ceph-node5 ~]# awk -F: \'/mail/ {print $1}\' /etc/passwd mail
这个例子中:
-F 指定字段分界符为冒号,即各个字段以冒号分隔。请注意,你也可以把分界符用双引号引住, -F":"也是正确的。 /mail/ 指定模式, awk 只会处理包含关键字 mail 的记录 {print $1} 动作部分,该动作只包含一个 awk 命令,它打印匹配 mail 的每条记录的第 1 个字段 /etc/passwd 即是输入文件
把 awk 命令放入单独的文件中(awk 脚本)
当需要执行很多 awk 命令时, 可以把/pattern/{action}这一部分放到单独的文件中,然后调用它:
awk –Fs –f myscript.awk input-file
myscript.awk 可以使用任意扩展名(或者不用扩展名)。但是加上扩展名.awk 便于维护,也可以在这个文件中设置字段分界符(后面详述),然后调用:
awk –f myscript.awk input-file
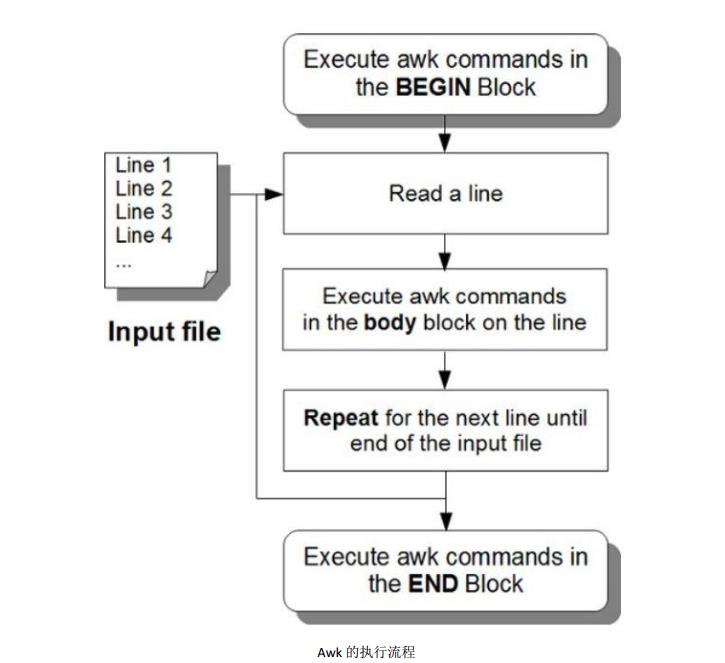
Awk 程序结构(BEGIN,body,END)区域
典型的 awk 程序包含下面三个区域:
1. BEGIN 区域
BEGIN { awk-commands }
BEGIN 区域的命令只最开始、在 awk 执行 body 区域命令之前执行一次。
BEGIN 区域很适合用来打印报文头部信息,以及用来初始化变量。
BEGIN 区域可以有一个或多个 awk 命令
关键字 BEGIN 必须要用大写
BEGIN 区域是可选的
2.body 区域
body 区域的语法:
/pattern/ {action}
body 区域的命令每次从输入文件读取一行就会执行一次
如果输入文件有 10 行,那 body 区域的命令就会执行 10 次(每行执行一次) Body 区域没有用任何关键字表示,只有用正则模式和命令。
3. END block
END 区域的语法:
END { awk-commands }
END 区域在 awk 执行完所有操作后执行,并且只执行一次。
END 区域很适合打印报文结尾信息,以及做一些清理动作
END 区域可以有一个或多个 awk 命令
关键字 END 必须要用大写
END 区域是可选的
如图:
下面的例子包含上上述的三个区域:
[root@ceph-node5 ~]# awk \'BEGIN { FS=":";print "----header----" } \\ > /mail/ {print $1} \\ > END {print "----footer----"}\' /etc/passwd ----header---- mail ----footer----
提示:如果命令很长,即可以放到单行执行,也可以用\\折成多行执行。上面的例子用\\把命令折成了 3 行。
在这个例子中:
BEGIN { FS=”:”;print “----header----“ } 为 BEGIN 区域,它设置了字段分界符变量 FS(下文详述)的值,然后打印报文头部信息。
这个区域仅在 body 区域循环之前执行一次。
/mail/{print $1}是 body 区域,包含一个正则模式和一个动作,即在输入文件中搜索包含关键字 mail 的行,并打印第一个字段。
END {print “----footer----“ }是 END 区域,打印报文尾部信息。
/etc/passwd 是输入文件,每行记录都会执行一次 body 区域里的动作。
上面的例子中,除了可以在命令行上执行外,还可以通过脚本执行。
首先建立下面的文件 myscript.awk,它包含了 begin,body 和 end :
[root@ceph-node5 ~]# vim myscript.awk BEGIN { FS=":" print "---header---" } /mail/ { print $1 } END { print "---footer---" }
然后,如下所示,在/etc/passwd 上执行 myscript.awk 文件:
[root@ceph-node5 ~]# awk -f myscript.awk /etc/passwd ---header--- mail ---footer---
请注意, awk 脚本中,注释以#开头。 如果要编写复杂的 awk 脚本,最后接受下面的建议:
在*awk 文件中写上足够多的注释,这样以后再次使用该脚本时,更易于读懂。
下面是随机列出的一些简单的例子,用例演示 awk 各个区域的不同组合方式:
只有 body 区域:
awk -F: \'{ print $1 }\' /etc/passwd
同时具有 begin,body 和 end 区域:
awk -F: \'BEGIN{printf "username\\n-------\\n"}{ print $1 }END {print "----------" }\' /etc/passwd
只有 begin 和 body 区域:
awk -F: \'BEGIN {print "UID"} {print $3}\' /etc/passwd
关于使用 BEGIN 区域的提示:
只使用 BEGIN 区域在 awk 中是符合语法的。在没有使用 body 区域时,不需要指定输入文件,因为 body 区域只在输入文件上执行。
所以在执行和输入文件无关的工作时,可以只使用BEGIN 区域。 下面的不少例子中,只包含 BEGIN 区域,用来说明 awk 的不同部分是如何执行的。
你可以因地制宜地使用下面的例子。
只包含 BEGIN 的简单示例:
[root@ceph-node5 ~]# awk \'BEGIN { print "Hello,World!" }\' Hello,World!
多个输入文件:
注意,可以为 awk 指定多个输入文件。 如果指定了两个文件,那么 body 区域会首先在第一个文件的所有行上执行,然后在第二个文件的所有行上执行。
多个输入文件示例:
[root@ceph-node5 ~]# awk \'BEING { FS=":";print "---header---" } /mail/ {print $1}\\ > END { print "---footer---"}\' /etc/passwd /etc/group mail:x:8:12:mail:/var/spool/mail:/sbin/nologin mail:x:12:postfix ---footer---
注意,即是指定了多个文件, BEGIN 和 END 区域,仍然只会执行一次。
打印命令
默认情况下, awk 的打印命令 print(不带任何参数)会打印整行数据。下面的例子等价于cat employee.txt命令
[root@ceph-node5 ~]# awk \'{print}\' employee.txt 101,John Doe,CEO 102,Jason Smith,IT Manager 103,Raj Reddy,Sysadmin 104,Anand Ram,Developer 105,Jane Miller,Sales Manager
也可以通过传递变量“$字段序号”作为 print 的参数来指定要打印的字段。 我们猜想例子应该只打印雇员名称(第 2 个字段)
[root@ceph-node5 ~]# awk \'{print $2}\' employee.txt Doe,CEO Smith,IT Reddy,Sysadmin Ram,Developer Miller,Sales
等等,这个输出好像和预期不符。 它打印了从姓氏开始直到记录结尾的所有内容。 这是因为awk 默认的字段分隔符是空格, awk 准确地执行了我们要求的动作,它以空格作为分隔符,打印第 2 个字段。当使用默认的空格作为字段分隔符时, 101,Johne 变成了第一条记录的第一个字段, Doe,CEO 变成了第二个字段。因此上面例子中, awk 把 Doe,CEO 作为第二个字段打印出来了
要解决这个文件,应该使用-F 选项为 awk 指定一个逗号,最为字段分隔符。
[root@ceph-node5 ~]# awk -F \',\' \'{print $2}\' employee.txt John Doe Jason Smith Raj Reddy Anand Ram Jane Miller
当字段分隔符是单个字符时,下面的所有写法都是争取的,即可以把它放在单引号或双引号中,或者不使用引号:
awk –F \',\' \'{print $2}\' employee.txt awk –F "," \'{print $2}\' employee.txt awk –F , \'{print $2}\' employee.txt
提示:也可使用 FS 变量来达到同样的目的。后面会介绍这个 awk 内置变量的用法。
一个简单的例子,用来输出雇员姓名,职位,同时附带 header 和 footer 信息:
[root@ceph-node5 ~]# awk \'BEGIN{FS=",";print "---------\\nName Title\\n------------\\n";}{print $2,"\\t",$3}END {print "-------------------"}\' employee.txt --------- Name Title ------------ John Doe CEO Jason Smith IT Manager Raj Reddy Sysadmin Anand Ram Developer Jane Miller Sales Manager -------------------
这个例子中,输出结果各字段并没有很好地对齐,后面章节将会介绍如何处理这个问题。 这
个例子还展示了如何使用 BEGIN 来打印 header 以及如何使用 END 来打印 footer.
请注意, $0 代表整条记录。 下面两个命令是等价的,都打印 employee.txt 的所有行:
awk \'{print}\' employee.txt awk \'{print $0}\' employee.txt
模式匹配
你可以只在匹配特殊模式的行数执行 awk 命令。
下面的例子只打印管理者的姓名和职位:
[root@ceph-node5 ~]# awk -F \',\' \'/Manager/ {print $2,$3}\' employee.txt Jason Smith IT Manager Jane Miller Sales Manager
下面的例子只打印雇员 id 为 102 的雇员的信息:
[root@ceph-node5 ~]# awk -F \',\' \'/^102/{print "Emp id 102 is",$2}\' employee.txt Emp id 102 is Jason Smith
awk内置变量
直接含义,可直接使用
调用变量的时候不用$符号标示,直接调用就可以
变量 用途 FILENAME 当前处理文件的文件名 $0 当前读入的整行文本内容 NR 记录当前已读入行的数量(行数) FNR 保存当前处理行在原文本内的序号(行号) NF 记录当前处理行的字段个数(列数) $n 指定分隔的第n个字段,如$1、$3分别表示第1、第3列 FS 保存或设置字段分隔符,例如FS=":" ENVIRON 调用Shell环境变量,格式为:ENVIRON["变量名"]
FS –输入字段分隔符
wk 默认的字段分隔符是空格,如果你的输入文件中不是一个空格作为字段分隔符, 你已经知道可以在 awk 命令行上使用-F 选项来指定它:
[root@ceph-node5 ~]# awk -F \',\' \'{print $2,$3}\' employee.txt John Doe CEO Jason Smith IT Manager Raj Reddy Sysadmin Anand Ram Developer Jane Miller Sales Manager
同样的事情,也可以使用 awk 内置变量 FS 来完成。 FS 只能在 BEGIN 区域中使用。
[root@ceph-node5 ~]# awk \'BEGIN {FS=","} {print $2,$3}\' employee.txt John Doe CEO Jason Smith IT Manager Raj Reddy Sysadmin Anand Ram Developer Jane Miller Sales Manager
BEGIN区域可以包含多个命令,下面的例子中, BEGIN区域包含一个FS和一个print命令.BEGIN
区域的多个命令之间,要用分号分隔。
awk \'BEGIN { FS=","; print "---------------------------\\nName\\tTitle\\n------------------------"}\\ {print $2,"\\t",$3;}\\ END {print "-----------------------------------------"}\' employee.txt
结果:
[root@ceph-node5 ~]# awk \'BEGIN { FS=","; > print "---------------------------\\nName\\tTitle\\n------------------------"}\\ > {print $2,"\\t",$3;}\\ > END {print "-----------------------------------------"}\' employee.txt --------------------------- Name Title ------------------------ John Doe CEO Jason Smith IT Manager Raj Reddy Sysadmin Anand Ram Developer Jane Miller Sales Manager -----------------------------------------
注意:默认的字段分隔符不仅仅是单个空格字符,它实际上是一个或多个空白字符。
下面的 employee-multiple-fs.txt 文件,每行记录都包含 3 个不同的字段分隔符:
, 雇员 id 后面的分隔符是逗号
: 雇员姓名后面的分隔符是分号
% 雇员职位后面的分隔符是百分号
创建文件:
[root@ceph-node5 ~]# vim employee-multiple-fs.txt 101,John Doe:CEO%10000 102,Jason Smith:IT Manager%5000 103,Raj Reddy:Sysadmin%4500 104,Anand Ram:Developer%4500 105,Jane Miller:Sales Manager%3000
当遇到一个包含多个字段分隔符的文件时,不必担心, FS 可以搞定。 你可以使用正则表达
式来指定多个字段分隔符,如 FS = “[,:%]” 指定字段分隔符可以是逗号 ,或者分号 : 或者百分号 %。
因此,下面的例子将打印 employee-multiple-fs.txt 文件中雇员名称和职位
[root@ceph-node5 ~]# awk \'BEGIN {FS="[,:%]"}{print $2,$3}\' employee-multiple-fs.txt John Doe CEO Jason Smith IT Manager Raj Reddy Sysadmin Anand Ram Developer Jane Miller Sales Manager
OFS – 输出字段分隔符
FS 是输入字段分隔符, OFS 是输出字段分隔符。 OFS 会被打印在输出行的连续的字段之间。
默认情况下, awk 在输出字段中间以空格分开。
请注意,我们没有指定 IFS 作为输入字段分隔符,我们从简地使用 FS。
下面的例子打印雇员姓名和薪水,并以空格分开。当你使用单个 print 语句打印多个以逗号
分开(如下面的例子所示)的变量是,每个变量之间会以空格分开。
[root@ceph-node5 ~]# awk -F \',\' \'{print $2,$3}\' employee.txt John Doe CEO Jason Smith IT Manager Raj Reddy Sysadmin Anand Ram Developer Jane Miller Sales Manager
如果你尝试认为地在输出字段之间加上冒号,会有如下输出。请注意在冒号前后均有一个多余的空格,这是因为 awk 仍然以空格作为输出字段分隔符。
下面的 print 语句实际上会打印 3 个值(以逗号分割)——$2,:和$4.因为如你所知,当使用单个print 语句打印多个变量时,输出内容会包含多余的空格。
[root@ceph-node5 ~]# awk -F \',\' \'{print $2,":",$3}\' employee.txt John Doe : CEO Jason Smith : IT Manager Raj Reddy : Sysadmin Anand Ram : Developer Jane Miller : Sales Manager
正确的方法是使用 awk 内置变量 OFS(输出字段分隔符),如下面了示例。 请注意这个例子中分号前后没有多余的空格,因为 OFS 使用冒号取代了 awk 默认的分隔符。
下面的 print 语句打印两个变量($2 和$4),使用都会分隔,然而输出结果却是以分号分隔(而不是空格),因为 OFS 被设置成了分号.
[root@ceph-node5 ~]# awk -F \',\' \'BEGIN {OFS=":"} {print $2,$3}\' employee.txt John Doe:CEO Jason Smith:IT Manager Raj Reddy:Sysadmin Anand Ram:Developer Jane Miller:Sales Manager
同时请注意在 print 语句中使用和不使用逗号的细微差别(打印多个变量时).当在 print 语句中指定了逗号, awk 会使用 OFS。如下面的例子所示,默认的 OFS 会被使用,所以你会看到输出值之间的空格。
[root@ceph-node5 ~]# awk \'BEGIN { print "test1","test2"}\' test1 test2
以上是关于十五 awk文本处理的主要内容,如果未能解决你的问题,请参考以下文章
不使用逗号是, awk 将不会使用 OFS,其输出变量之间没有任何空格。