golang的goroutine调度机制
Posted 诛仙物语
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了golang的goroutine调度机制相关的知识,希望对你有一定的参考价值。
golang的goroutine调度机制
一直对goroutine的调度机制很好奇,最近在看雨痕的golang源码分析,(基于go1.4)
感觉豁然开朗,受益匪浅;
去繁就简,再加上自己的一些理解,整理了一下
~~
调度器
主要基于三个基本对象上,G,M,P(定义在源码的src/runtime/runtime.h文件中)
1. G代表一个goroutine对象,每次go调用的时候,都会创建一个G对象
2. M代表一个线程,每次创建一个M的时候,都会有一个底层线程创建;所有的G任务,最终还是在M上执行
3. P代表一个处理器,每一个运行的M都必须绑定一个P,就像线程必须在么一个CPU核上执行一样
P的个数就是GOMAXPROCS(最大256),启动时固定的,一般不修改; M的个数和P的个数不一定一样多(会有休眠的M或者不需要太多的M)(最大10000);每一个P保存着本地G任务队列,也有一个全局G任务队列;
如下图所示
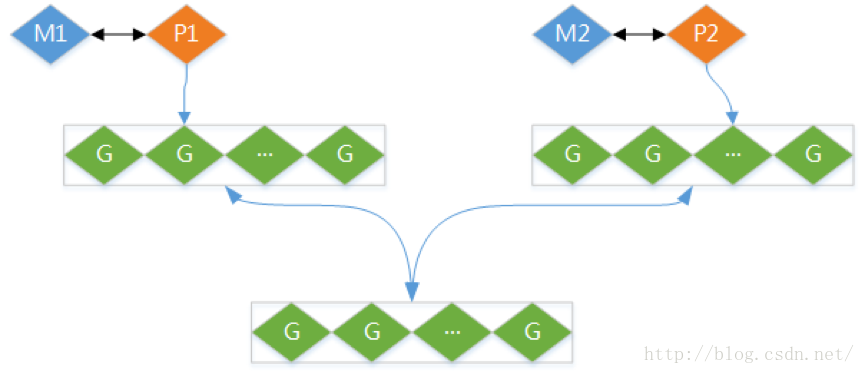
全局G任务队列会和各个本地G任务队列按照一定的策略互相交换(满了,则把本地队列的一半送给全局队列)
P是用一个全局数组(255)来保存的,并且维护着一个全局的P空闲链表
每次go调用的时候,都会:
1. 创建一个G对象,加入到本地队列或者全局队列
2. 如果还有空闲的P,则创建一个M
3. M会启动一个底层线程,循环执行能找到的G任务
4. G任务的执行顺序是,先从本地队列找,本地没有则从全局队列找(一次性转移(全局G个数/P个数)个,再去其它P中找(一次性转移一半),
5. 以上的G任务执行是按照队列顺序(也就是go调用的顺序)执行的。(这个地方是不是觉得很奇怪??)
对于上面的第2-3步,创建一个M,其过程:
1. 先找到一个空闲的P,如果没有则直接返回,(哈哈,这个地方就保证了进程不会占用超过自己设定的cpu个数)
2. 调用系统api创建线程,不同的操作系统,调用不一样,其实就是和c语言创建过程是一致的,(windows用的是CreateThread,linux用的是clone系统调用),(*^__^*)嘻嘻……
3. 然后创建的这个线程里面才是真正做事的,循环执行G任务
那就会有个问题,如果一个系统调用或者G任务执行太长,他就会一直占用这个线程,由于本地队列的G任务是顺序执行的,其它G任务就会阻塞了,怎样中止长任务的呢?(这个地方我找了好久~o(╯□╰)o)
这样滴,启动的时候,会专门创建一个线程sysmon,用来监控和管理,在内部是一个循环:
1. 记录所有P的G任务计数schedtick,(schedtick会在每执行一个G任务后递增)
2. 如果检查到 schedtick一直没有递增,说明这个P一直在执行同一个G任务,如果超过一定的时间(10ms),就在这个G任务的栈信息里面加一个标记
3. 然后这个G任务在执行的时候,如果遇到非内联函数调用,就会检查一次这个标记,然后中断自己,把自己加到队列末尾,执行下一个G
4. O(∩_∩)O哈哈~,如果没有遇到非内联函数(有时候正常的小函数会被优化成内联函数)调用的话,那就惨了,会一直执行这个G任务,直到它自己结束;如果是个死循环,并且GOMAXPROCS=1的话,恭喜你,夯住了!亲测,的确如此
对于一个G任务,中断后的恢复过程:
1. 中断的时候将寄存器里的栈信息,保存到自己的G对象里面
2. 当再次轮到自己执行时,将自己保存的栈信息复制到寄存器里面,这样就接着上次之后运行了。 ~\(≧▽≦)/~
但是还有一个问题,就是系统启动的过程,雨痕没有说的太明白,我一直有很多问题都狠疑惑(第一个M怎么来的?,G怎么找到对应的P?等等),这个让我蛋疼了好久~
不过我自己意淫了一下,补充在下面,欢迎大家指正
1. 系统启动的时候,首先跑的是主线程,那第一个M应该就是主线程吧(按照C语言的理解,嘿嘿),这里叫M1,可以看前面的图
2. 然后这个主线程会绑定第一个P1
3. 咱们写的main函数,其实是作为一个goroutine来执行的(雨痕说的)
4. 也就是第一个P1就有了一个G1任务,然后第一个M1就执行这个G1任务(也就是main函数),创建这个G1的时候不用创建M了,因为已经有了M1
5. 这个main函数里面所有的goroutine,都绑定到当前的M1所对应的P1上,O(∩_∩)O哈哈~
6. 然后创建main里的goroutine的时候(比如G2),就会创建新的M2,新的M2里的初始P2的本地任务队列是空的,会从P1里面取一些过来,哈哈
7. 这样两个M1,M2各自执行自己的G任务,再依次往复,这下就圆满了~~~
综上:
所以goroutine是按照抢占式调度的,一个goroutine最多执行10ms就会换作下一个
这个和目前主流系统的的cpu调度类似(按照时间分片)
windows:20ms
linux:5ms-800ms
到这里都差不多了,这些在雨痕的笔记里面都有更详细的描述,不过很多地方比较凌乱,比较复杂,这里筛检了很多,方便读者理解
注意:
1. 在Golang中编译器也会尝试进行内联,将小函数直接复制并编译,为了内联,尽量消除编译器无法侦测的dead code,利用gobuild -gcflags=-m编译命令可以查看程序内联状态,不得不说golang的编译工具链还是很强大的,十分有利于程序的优化。
如果有任何疑问,欢迎提出,
随时更新
以上是关于golang的goroutine调度机制的主要内容,如果未能解决你的问题,请参考以下文章