spark分区
Posted zzhangyuhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark分区相关的知识,希望对你有一定的参考价值。
RDD是弹性分布式数据集,通常RDD很大,会被分成多个分区,保存在不同节点上。
那么分区有什么好处呢?
分区能减少节点之间的通信开销,正确的分区能大大加快程序的执行速度。
我们看个例子
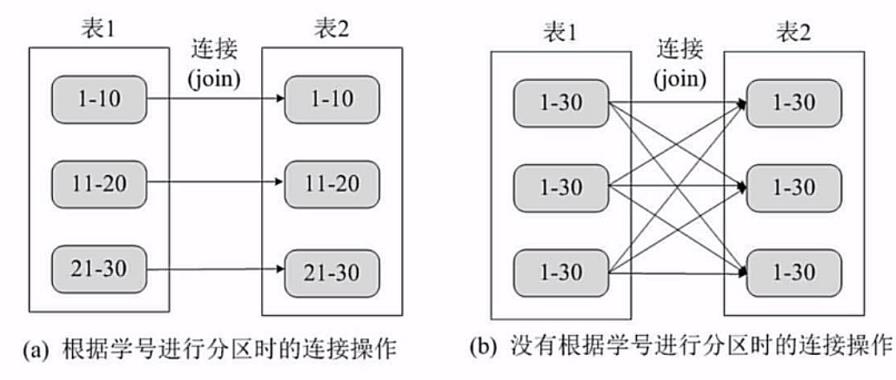
首先我们要了解一个概念,分区并不等同于分块。
分块是我们把全部数据切分成好多块来存储叫做分块。
如上图b,产生的分块,每个分块都可能含有同样范围的数据。
而分区,则是把同样范围的数据分开,如图a
我们通过这个图片可以清楚的看到,我们通过把相同主键的数据连接。
经过有序分区的数据,只需要按照相同的主键分区 join 即可。
未通过分区的分块执行 join ,额外进行多次连接操作,把同样的数据连接到不同节点上,大大增大了通信开销。
在一些操作上,join groupby,filer等等都能从分区上获得很大的收益。
分区原则
RDD分区的一个分区原则是使得分区个数尽量等于集群中的CPU核心(core)数量。分区过多并不会增加执行速度。
例如,我们集群有10个core,我们分5个区,每个core执行一个分区操作,剩下5个core浪费。
如果,我们分20分区,一个core执行一个分区,剩下的10分区将会排队等待。
默认分区数目
对于不同的Spark部署模式而言(本地模式,standalone模式,YARN模式,Mesos模式)
都可以数值spark.default.parallelism这个参数值,来配置默认分区。
当然针对不同的部署模式,默认分区的数目肯定也是不相同的。
本地模式,默认为本地机器的CPU数目,若设置了local[N],则默认为N。一般使用local[*]来使用所有CPU数。
YARN模式,在集群中所有CPU核心数目总和和 2 二者中取较大值作为默认值。
Mesos模式,默认分区为8.
如何手动设置分区
1.创建RDD时:在调用 textFile 和 parallelize 方法的时候手动指定分区个数即可。
语法格式 sc.parallelize(path,partitionNum) sc.textFile(path,partitionNum)
//sc.parallelize(path,partitionNum)
val list = List("Hadoop","Spark","Hive");
val rdd1 = sc.parallelize(list,2);//设置两个分区
val rdd2 = sc.parallelize(list);//未指定分区,默认为spark.default.parallelism
//sc.textFile(path,partitionNum)
val rdd3 = sc.textFile("file://+本地文件地址",2);//设置两个分区
val rdd4 = sc.textFile("file://+本地文件地址");//未指定分区,默认为min(2,spark.default.parallelism)
val rdd5 = sc.textFile("file://+HDFS文件地址");//未指定分区,默认为HDFS文件分片数
2.通过转化操作得到新的RDD时:调用 repartition 方法即可。
语法格式 val newRdd = oldRdd.repartition(1)
val list = List("Hadoop","Spark","Hive");
val rdd1 = sc.parallelize(list,2);//设置两个分区
val newRdd1 = rdd1.repartition(3);//重新分区
println(newRdd1.partitions.size);//查看分区数
分区函数
我们在使用分区的时候要了解两条规则
(1)只有Key-Value类型的RDD才有分区的,非Key-Value类型的RDD分区的值是None
(2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的
spark内部提供了 HashPartitioner 和 RangePartitioner 两种分区策略。
1.HashPartitioner
原理:
对于给定的key,计算其hashCode,并除于分区的个数取余,如果余数小于0,则用余数+分区的个数,最后返回的值就是这个key所属的分区ID。
语法:
rdd.partitionBy(new spark.HashPartitioner(n))
示例:
object Main{
def main(args:Array[String]): Unit ={
val conf = new SparkConf();
val sc = new SparkContext(conf);
val list = List((1,1),(1,2),(2,1),(2,2),(3,1),(3,2))//注意这里必须是(k,v)形式
val rdd = sc.parallelize(list);
rdd.partitionBy(new spark.HashPartitioner(3));//使用HashPartitioner
}
}
我们再看一个例子说明HashPartitioner如何分区的。

注意:实际我们使用的默认分区方式实际是 HashPartitioner 分区方式
2.RangePartitioner
原理:
根据key值范围和分区数确定分区范围,将范围内的键分配给相应的分区。
语法:
rdd.partitionBy(new RangePartitioner(n,rdd));
示例:
object Main{
def main(args:Array[String]): Unit ={
val conf = new SparkConf();
val sc = new SparkContext(conf);
val list = List((1,1),(1,2),(2,1),(2,2),(3,1),(3,2))
val rdd = sc.parallelize(list);
val pairRdd = rdd.partitionBy(new RangePartitioner(3,rdd));//根据key分成三个区
}
}
3.用户自定义分区
如果上面两种分区都满足不了你的要求的时候,我们可以自己定义分区类。
Spark提供了相应的接口,我们只需要扩展Partitioner抽象类。
abstract class Partitioner extends Serializable {
def numPartitions: Int //这个方法需要返回你想要创建分区的个数
def getPartition(key: Any): Int //这个函数需要对输入的key做计算,然后返回该key的分区ID,范围一定是0到 numPartitions-1
}
定义完毕后,通过parttitionBy()方法调用。
示例:

我们看这样一个实例,需要按照最后一位数来分区,我们用普通的分区并不能满足要求,所以这个时候需要自己定义分区类。
class UDPartitioner (numParts:Int) extends Partitioner {
//覆盖分区数
override def numPartitions = numParts;
//覆盖分区获取函数,返回分区所用的key
override def getPartition(key: Any) : Int= {
key.toString.toInt % 10;//通过key除10取余来获取最后一位数并返回。
}
}
object Main{
def main(args:Array[String]): Unit ={
val conf = new SparkConf();
val sc = new SparkContext(conf);
//模拟5个分区的数据
val data1 = sc.parallelize(1 to 10,5);
//注意,RDD一定要是key-value,才能使用用户自定义的分区类,通过key来确定分区
val data2 = data1.map((_,1));//占位符用法,等同于data.map(x => (x,1))
//根据尾号转变为10个分区,分别写到10个文件中
data2.partitionBy(new UDPartitioner(10)).saveAsTextFile("file:///usr/local/output");
}
}
另外,我们也可以通过在函数中额外定义 hashcode()方法 和 equal()方法来保证分区的正确分配。
以上是关于spark分区的主要内容,如果未能解决你的问题,请参考以下文章