正则表达式,re模块
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则表达式,re模块相关的知识,希望对你有一定的参考价值。
正则表达式
在编写处理字符串的程序或网页时,经常会有查找符合某些复杂规则的字符串的需要。正则表达式就是用于描述这些规则的工具。换句话说,正则表达式就是记录文本规则的代码。
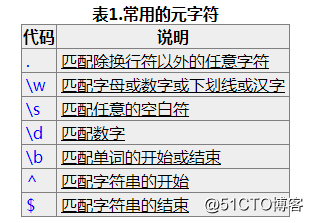
^:开头
$:结尾
比如一个网站如果要求你填写的QQ号必须为5位到12位数字时,可以使用:^\d{5,12}$。
字符转义
想查找deerchao.net ,需要将特殊符号转义 deerchao.net
想查找C:\Windows ,需要将特殊符号转义 C:\Windows
重复

Windows\d+匹配Windows后面跟1个或更多数字
^\w+匹配一行的第一个单词
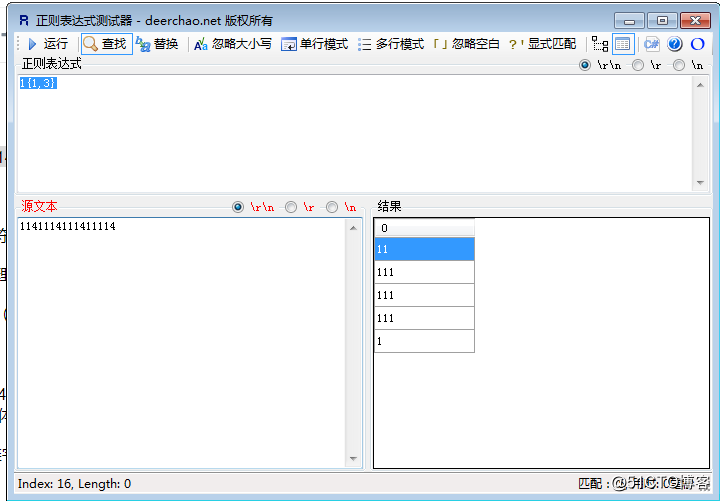
11{1,3}:表示11出现1次至3次(111,1111,11111),比如输入1141114111411114
字符类
[aeiou]就匹配任何一个英文元音字母,[.?!]匹配标点符号(.或?或!)
[0-9]代表的含意与\d就是完全一致的:一位数字;同理[a-z0-9A-Z_]也完全等同于\w
(?0\d{2}[) -]?\d{8} :1、转义字符( 出现0次或者1次(?) 2、跟着0 然后跟着2个数字(\d{2})3、然后是 )或者空格 或者 - 中的一个[) -] ,出现0次或者1次(?)
4、后面跟着8个数字(\d{8})
分枝条件
刚才那个表达式也能匹配010)12345678或(022-87654321这样的“不正确”的格式。要解决这个问题,我们需要用到分枝条件。正则表达式里的分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,具体方法是用|把不同的规则分隔开
0\d{2}-\d{8}|0\d{3}-\d{7}:这个表达式能匹配两种以连字号分隔的电话号码:一种是三位区号,8位本地号(如010-12345678),一种是4位区号,7位本地号(0376-2233445)。
分组
(\d{1,3}.){3}\d{1,3}:1、表示(\d{1,3}.) 是一个分组 数字重复出现1,3次,. 表示转义 2、{3} 表示重复3次 2、\d{1,3}:重复前面的数字1,3次
\d:1到9
反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义:
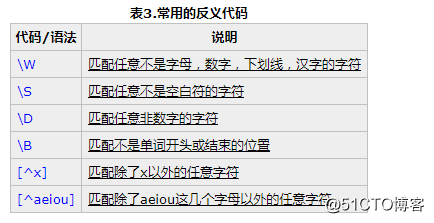
例子:\S+匹配不包含空白符的字符串。
<a[^>]+>匹配用尖括号括起来的以a开头的字符串。
re模块
re.match函数
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none
函数语法:
re.match(pattern, string, flags=0)
例子1:
import re
s = "ab<h1>xxx</h1>dsafasdf<html>sdfads</html>"
reg = re.compile(r"(<(?P<tag>\w+)>(.*)</(?P=tag)>)")
print(reg.findall(s))
结果:
[(‘<h1>xxx</h1>‘, ‘h1‘, ‘xxx‘), (‘<html>sdfads</html>‘, ‘html‘, ‘sdfads‘)]
分析:1、compile方法是将正则编译成一个对象,效率比直接写正则表达式要高
2、r"" :表示双引号内的特殊字符不需要转义,如?,$号,不需要加上\
3、<?P<tag>\w> :表示将数据字母组成一个组名为tag
1、?P<name>命令一个组名为tag,后面调用就是?P=tag
2、\w:数字,字母
4、.*:贪婪模式 ,表示所有
5、findall 是将正则表达式中带有()的匹配,只要()里面的匹配到了就放到列表里
例子2:
s = "ab<h1>xxx</h1>dsafasdf<html>sdfads</html>"
reg = re.compile(r"(<(?P<tag>\w+)>(.*)</(?P=tag)>)")
print(reg.match(s))
结果为:None (没匹配到,因为s 是以ab开头的,正则表达式以<开头)
re.match与re.search的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配就返回。
例子:
s = "ab<h1>xxx</h1>dsafasdf<html>sdfads</html>"
reg = re.compile(r"(<(?P<tag>\w+)>(.*)</(?P=tag)>)")
print(reg.search(s).group(1)) #group(1):表示返回第一个括号的内容,group() 同group(0)就是匹配正则表达式整体结果
没有匹配成功的,re.search()返回None
split
p = re.compile(r‘\d+‘)
print p.split(‘one1two2three3four4‘)
结果: [‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘]
以上是关于正则表达式,re模块的主要内容,如果未能解决你的问题,请参考以下文章