常见数据库的优化方式
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常见数据库的优化方式相关的知识,希望对你有一定的参考价值。
?
目录
?
?
一、常见数据库的优化方式:
我们之前讲的静态化,memcache主要是少查询数据库,或者不查询数据库的。一个网站,必经要查询数据库,索引也要对数据库进行优化。
1、表的设计要符合三范式。
2、添加适当的索引,索引对查询速度影响很大,必须添加索引。主键索引,唯一索引,普通索引,全文索引
3、添加适当存储过程,触发器,事务等。
4、读写分离(主从数据库)
5、对sql语句的一些优化,(查询执行速度比较慢的sql语句)
6、分表分区
分表:把一张大表分成多张表。分区:把一张表里面的分配到不同的区域存储,
7、对mysql服务器硬件的升级操作。
二、提高效率,反三范式:
第一范式:
原子性:表里面的字段不能再分割,只要是关系型数据库,就天然的自动满足第一范式。
关系型数据库:(有行和列的概念)mysql,sql server,oracle,db2,infomix,sybase,postgresql
在设计时,先有库-》表-》字段-》具体记录(内容):在存储数据时,要设计字段。
非关系型数据库(泛指nosql数据库):memcache/redis/momgodb/等
第二范式:
一个表中没有完全相同的记录,通过一个主键即能解决。
第三范式:
表中不能存储冗余数据,
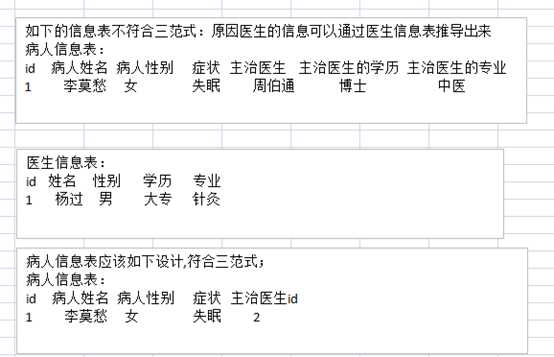
?
反三范式设计:
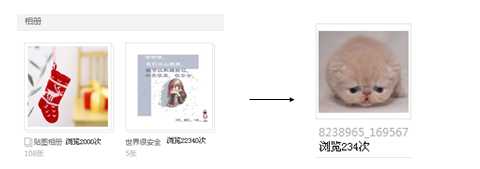
?
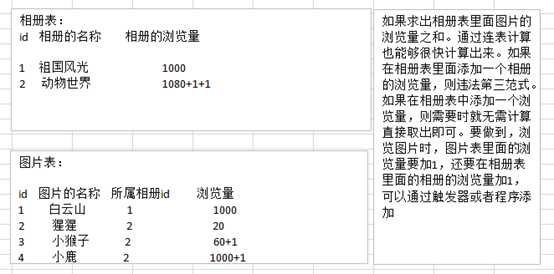
?
三、定位慢查询。
慢查询:找出在一个网站中,查询速度比较慢的语句,可以开启一个日志文件,记录查询速度比较慢的sql语句。在默认情况下,慢查询日志是关闭的,默认记录时间是超过10秒 的sql语句。
1、以记录慢查询的方式来启动mysql,
先关闭mysql,进入到mysql的安装目录。
关闭mysql服务:可以通过计算机-》管理->服务-》mysqld的服务名称,单击停止。
慢查询:mysqld.exe --safe-mode --slow-query-log
{mysql的安装目录}>bin/mysqld.exe --safe-mode --slow-query-log
通过慢查询日志定位执行效率较低的SQL语句。慢查询日志记录了所有执行时间超过long_query_time所设置的SQL语句。
执行:如下已经启动:

?
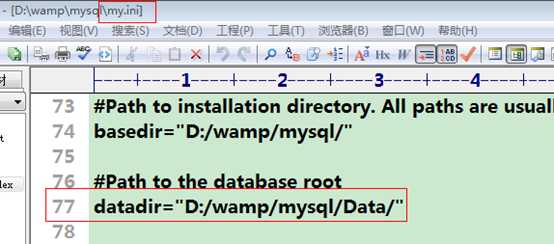
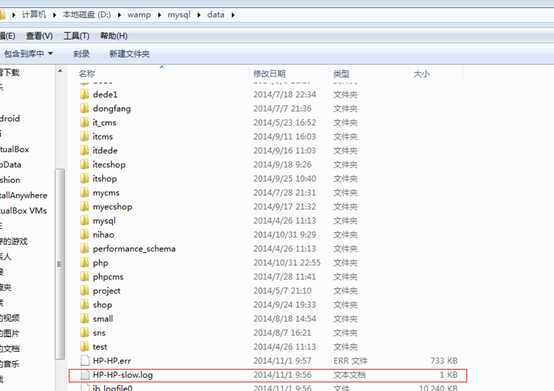
2、查看慢查询日志的存储路径。
开启了慢查询日志后,会建立一个慢查询日志文件。该日志文件保存在数据库的目录下,数据库的目录可以通过配置文件查看。

?


?
3、进程测试:
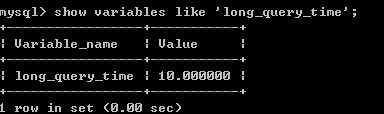
查看当前数据库下慢查询记录时间:
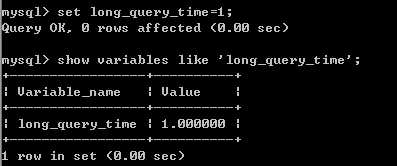
show variables like ‘long_query_time‘;


修改慢查询时间:
set long_query_time=2;
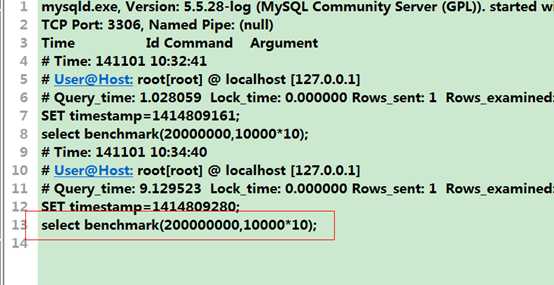
通过如下的一个函数来进行测试:
benchmark(count,expr)函数可以测试执行count次expr操作需要的时间
一般情况下,出现查询比较慢的语句,是没有添加索引导致的。
没有添加索引前:
添加索引之后:

四、索引的讲解:
建立的测试表:
create table user(
id int primary key auto_increment,
name varchar(32) not null default ‘‘,
age tinyint unsigned not null default 0,
email varchar(32) not null default ‘‘,
classid int not null default 1
)engine myisam charset utf8;
insert into user values(null,‘xiaogang‘,12,‘[email protected]‘,4),
(null,‘xiaohong‘,13,‘[email protected]‘,2),
(null,‘xiaolong‘,31,‘[email protected]‘,2),
(null,‘xiaofeng‘,22,‘[email protected]‘,3),
(null,‘xiaogui‘,42,‘[email protected]‘,3);
? ?
创建一个班级表:
create table class(
id int not null default 0,
classname varchar(32) not null default ‘‘
)engine myisam charset utf8;
insert into class values(1,‘java‘),(2,‘.net‘),(3,‘php‘),(4,‘c++‘),(5,‘ios‘);
?
1、主键索引
可以在建立表的添加create table emp(id int primary key)
可以在建立完表之后,添加:alter table tablename add primary key(列1,列2)
主键索引的特点:
(1)一个表中最多只有一个主键索引
(2)一个主键索引可以指向多个列
(3)主键索引的列,不能有重复的值,也不能有null
(4)主键索引的效率高。
?
2、唯一索引
可以在建立表的时候添加:create table emp(name varchar(32) unique)
在建完表之后,添加:
alter table tablename add unique [索引名](列名)


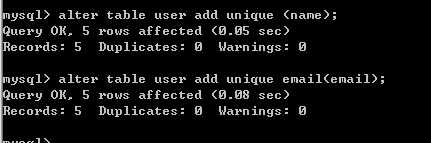
唯一索引的特点:
(1)一个表中可以有多个唯一索引
(2)一个唯一索引可以指向多个列 ,
比如alter table tablename add unique [索引名](列1,列2)
(3)如果在唯一索引上,没有指定not null,则该列可以为空,同时可以有多个null,
(4)唯一索引的效率较高。
?
3、普通索引
使用普通索引主要是提高查询效率
?
添加alter table tablename add index [索引名](列1,列3)

?
4、全文索引
mysql自带的全文索引mysql5.5不支持中文,支持英文,同时要求表的存储引擎是myisam。如果希望支持中文,有两个方案,
(1)使用aphinx中文版coreseek (来替代全文索引)
(2)插件mysqlcft。
5、查看索引
(1)show index from 表名
(2)show indexes from 表名
(3)show keys from 表名
(4)desc 表名
6、删除索引
(1)主键索引的删除:
alter table tablename drop primary key;要注意:在删除主键索引时,要首先去掉auto_increment属性。

?
(2)唯一索引的删除
alter table tablename drop index 唯一索引的名字

(3)普通索引的删除:
alter table tablename drop index 普通索引的名字

?
7、添加索引主要的问题:
(1)较频繁的作为查询条件字段应该创建索引
????select * from emp where empno = 1
????唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
????select * from emp where sex = ‘男‘
????更新非常频繁的字段不适合创建索引
????select * from emp where logincount = 1
(2)不会出现在WHERE子句中字段不该创建索
索引是由代价的,虽然是查询速度提高了,但是,会影响增该删的效率。而且索引文件会占用空间。



?
?
五、explain工具的讲解
?
该工具能够分析sql执行效率,但是并不执行sql语句。主要是查看sql语句是否用到索引。
语法:explain sql语句\\G 或 desc sql语句\\G
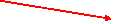
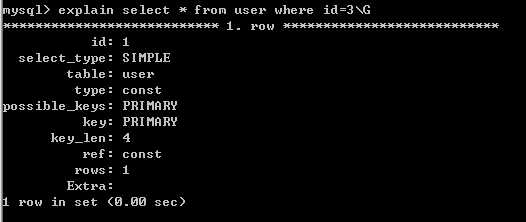
使用索引时:







?
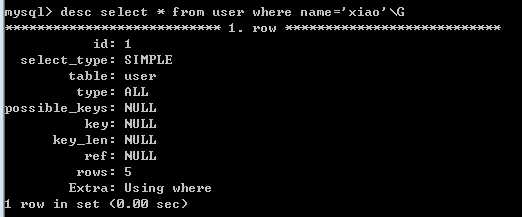
没有使用索引时:


?
explain工具的参数说明:
会产生如下信息:
select_type:表示查询的类型。
table:输出结果集的表
type:表示表的连接类型
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明
?
六、索引应用讲解:
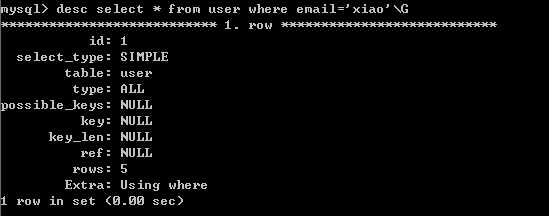
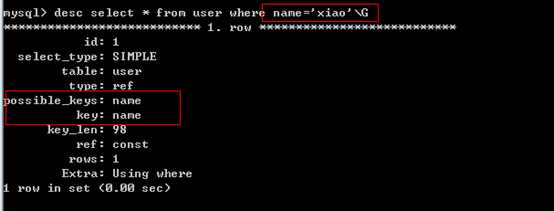
1、对于创建的多列(复合)索引,只要查询条件使用了最左边的列,索引一般就会被使用。
 mysql> alter table user add index (name,email);
mysql> alter table user add index (name,email);
Query OK, 5 rows affected (0.08 sec)
 Records: 5 Duplicates: 0 Warnings: 0
Records: 5 Duplicates: 0 Warnings: 0
?


?
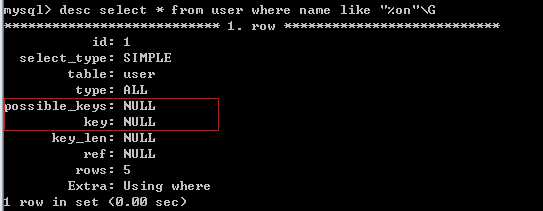
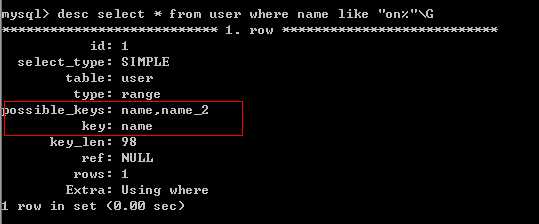
2、对于使用like的查询,查询如果是"%XXX",不会使用到索引,‘XXX%‘会使用到索引。
?
?
?
要注意:在有些情况下,还是会用到like查询,比如通过歌词搜索歌名,通过剧情搜索电影名称。借助于工具,sphinx里面的coreseek软件。
?
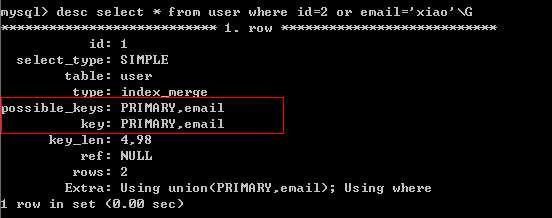
3、如果条件中有or,则要求or的索引字段都必须有索引,否则不能用到索引。


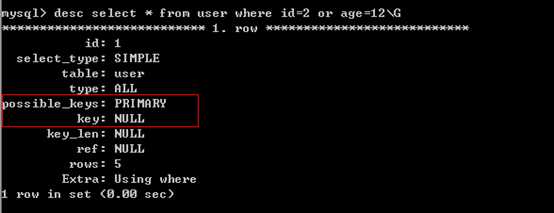
该email添加索引后,在测试,会用到索引
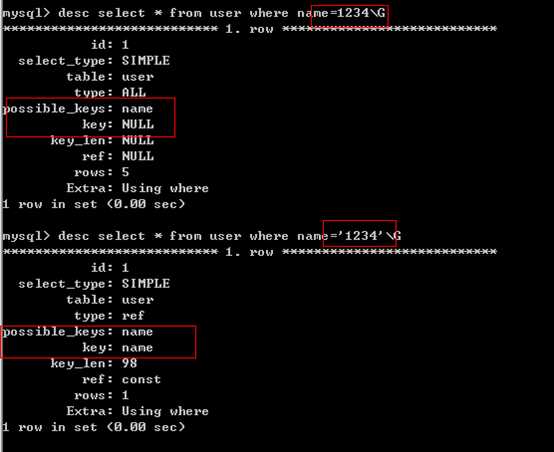
4、如果列类型是字符串,一定要在条件中将数据使用引号引用起来,否则不使用索引。
?
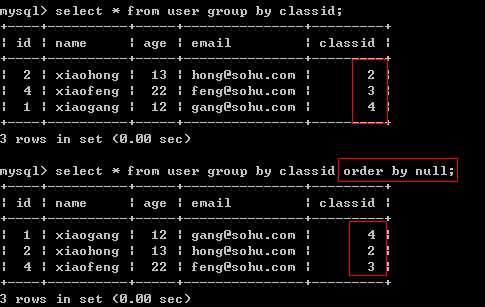
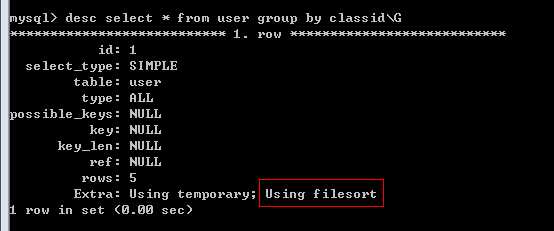
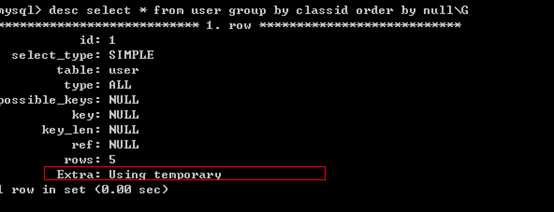
5、优化group by语句
默认情况下, mysql对所有的group by col1,col2进行排序。这与在查询中指定order by col1,col2类型,如果查询中包括group by 但用户想要避免排序结果的消耗,则可以使用order by null禁止排序。
?
?
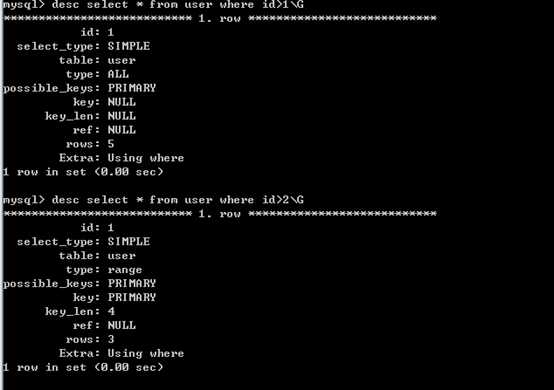
6、当取出的数据量超过表中数据的20%,优化器就不会使用索引,而是全表扫描。
扫描的行数太多了,优化器认为全表扫描比索引来的块。
?
7、查看索引的使用情况
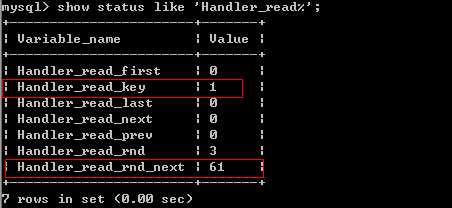
大家可以注意:
handler_read_key:这个值越高越好,越高表示使用索引查询到的次数。
handler_read_rnd_next:这个值越高,说明查询低效。
8、对应大批量插入数据,需要注意的:
大批量插入数据(MySql管理员) 了解
对于MyISAM:
先禁用索引:
alter table table_name disable keys;
loading data//insert语句; 执行插入语句
执行完成插入语句后,开启索引,统一添加索引。
alter table table_name enable keys;
?
对于Innodb:
1,将要导入的数据按照主键排序
2,set unique_checks=0,关闭唯一性校验。
3,set autocommit=0,关闭自动提交。
七、并发处理的锁机制:
比如执行如下操作:
(1)从数据库中取出id值,
(2)进行加1操作。
(3)修改完成后,再保存到数据库中。
比如原来 id的值为100,==》101
以上步骤执行100次,最后变成200
?
有两个用户同时执行的话。
a用户:
100
101
?
b用户:
100
101
?
通过锁机制来进行解决,
锁机制:在执行时,只有一个用户获得锁,其他用户处于阻塞状态,需要等待解锁。
mysql?的锁有以下几种形式:
表级锁:开销小,加锁快,发生锁冲突的概率最高,并发度最低。myisam引擎属于这种类型。
行级锁:开销大,加锁慢,发生锁冲突的概率最低,并发度也最高。innodb属于这种类型。
1、表锁的演示;
对myisam表的读操作(加读锁),不会阻塞其他进程对同一表的读请求,但会阻塞对同一表的写请求。只有当读锁释放后,才会执行其他进程的操作。

表添加读锁后,其他进程对该表只能查询操作,修改时会被阻塞。
当前进程,能够执行查询操作,不能执行修改操作。不能对没有锁定的表进行操作。
锁表的语法:
lock table 表名 read|write
也可以锁定多个表,语法是:lock table 表1 read|wirte,表2 read|wirte
对myisam表的写操作(加写锁),会阻塞其他进程对锁定表的任何操作,不能读写,
表加写锁后,则只有当前进程对锁定的表,可以执行任何操作。其他进程的操作会被阻塞。
?
2、行锁的演示
innodb存储引擎是通过给索引上的索引项加锁来实现的,这就意味着:只有通过索引条件检索数据,innodb才会使用行级锁,否则,innodb使用表锁。
行锁的语法:
begin
sql语句
commit
开启行锁后,当前进程在针对某条记录执行操作时,其他进程不能操作和当前进程相同id的记录。
php里面有文件锁,在实际的项目中多数使用文件锁,因为表锁,会阻塞,当对一些表添加写锁后,其他进程就不能操作了。这样会阻塞整个网站,会拖慢网站的速度。
?
类似的面试题:
一件商品,库存量还有一件,这时有两个用户同时请求下订单,如何防止都下订单成功,却没有货发。
八、分表技术
分表:把一个大表分成几个小表:
垂直分割:
在dedecms里面,垂直分割:
在一个数据库中想要存储各种数据,比如说文章数据,电影,音乐,商品数据,
内容主表+附加表:
内容主表:存储各种数据的一些公共信息,比如数据的名称,添加时间等,
可以使用多个附加表,附加表存储一些数据的独特的信息。
主要原因:是内容主表里面的数据访问比较频繁。
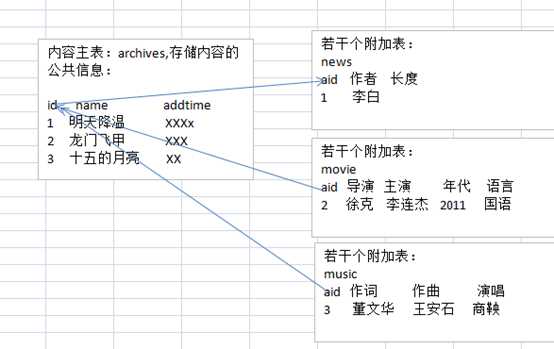
?
水平分割:
通过id取模
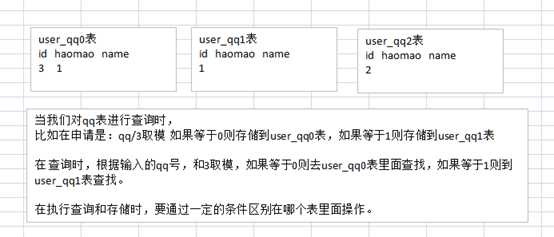
?
九、分区技术
就是把一个表存储到磁盘不同区域,仍然是一张表。
1、基本的概念:
mysql5.1后有4种分区类型:
(1)Range(范围)–这种模式允许将数据划分不同范围。例如可以将一个表通过年份划分成若干个分区。
(2)List(预定义列表)–这种模式允许系统通过预定义的列表的值来对数据进行分割
(3)Hash(哈希)–这中模式允许通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区。例如可以建立一个对表主键进行分区的表。
(4)Key(键值)-上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
2 range分区:
假如你创建了一个如下的表,该表保存有20家超市的职员记录,这20家超市的编号从1到20.如果你想将其分成4个小分区,可以采用range分区,创建的数据表如下。
创建range分区语法:
create table emp(
id int not null,
name varchar(32) not null default ‘‘ comment ‘职员的名称‘,
store_id int not null comment ‘超市的编号范围是1-20‘
)engine myisam charset utf8
partition by range(store_id)(
partition p0 values less than(6), //是store_id的值小于6的存储区域。
partition p1 values less than(11), //是store_id的值大于等于6小于11的存储区域。
partition p2 values less than(16),
partition p3 values less than(21)
)
insert into emp values(1,‘杨过‘,1)--à数据是存储到p0区
insert into emp values(23,‘小龙女‘,15)--à数据是存储到p2区
?
insert into emp values(100,‘李莫愁‘,11)=à数据是存储到p2区。
?
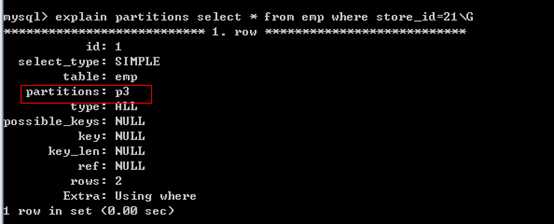
测试使用取出数据时是否用到分区:
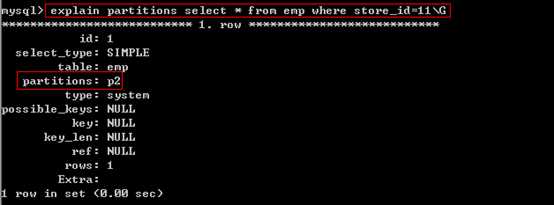
?
?
在取出数据时,条件中必须partition by range(store_id),range里面的字段。
3、list分区与range分区有类似的地方,
例子:假如你创建一个如下的一个表,该表保存有20家超市的职员记录,这20家超市的编号从1到20.而这20家超市分布在4个有经销权的地区,如下表所示:
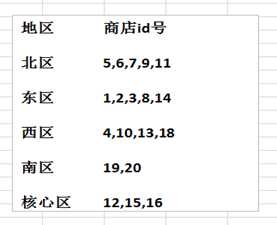
create table emp(
id int not null,
name varchar(32) not null default ‘‘,
store_id int not null
)
partition by list(store_id)(
partition p0 values in(5,6,7,8),
partition p1 values in(11,3,12,11),
partition p2 values in(16),
partition p3 values in(21)
)
注意:在使用分区时,where后面的字段必须是分区字段,才能使用到分区。
?
4、分区表的限制;
(1)只能对数据表的整型列进行分区,或者数据列可以通过分区函数转化成整型列
(2)最大分区数目不能超过1024
(3)如果含有唯一索引或者主键,则分区列必须包含在所有的唯一索引或者主键在内
(4)按日期进行分区很非常适合,因为很多日期函数可以用。但是对于字符串来说合适的分区函数不太多 。
10、其他调优:
1、选择合适的存储引擎 (myisam innodb)
- MyISAM:默认的MySQL存储引擎。如果应用是以读操作和插入操作为主,只有很少的更新和删除操作,并且对事务的完整性要求不是很高。其优势是访问的速度快。(尤其适合论坛的帖子表)
- InnoDB:提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM,写的处理效率差一些并且会占用更多的磁盘空间(如果对安全要求高,则使用innodb)。[账户,积分]
- Memory/heap [一些访问频繁,变化频繁,又没有必要入库的数据 :比如用户在线状态]
- 说明: memory表的数据都在内存中,因此操作速度快,但是缺少是当mysql重启后,数据丢失,但表的结构在.
- 注:从mysql5.5.x开始,默认的存储引擎变更为innodb,innodb是为处理巨大数据量时拥有最大性能而设计的。它的 cpu效率可能是任何其他基于磁盘的关系数据库引擎所不能匹敌的。
2、数据类型的选择
(1)在精度要求高的应用中,建议使用定点数来存储数值,以保证结果的准确性。decimal 不要用float
(2)要用于存储手机号,哪个类型比较合适。假如我们要用char(11),如果字符集是utf8 则占用多少个字节。11*3==33,如果是gbk字符集则占用11*2=22个字节,
如果用bigint型存储,则占用8个字节,
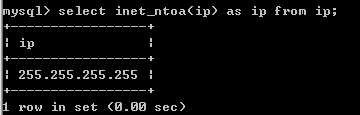
(3)如果要存储ip地址。假如用char(15)è占用很多字节,能否用整型来存储呢?
可以通过一个函数,把ip地址转换成整数。可以使用int来存储
inet_aton():把ip地址转换成整数。
inet_ntoa():把整数转换成ip地址。
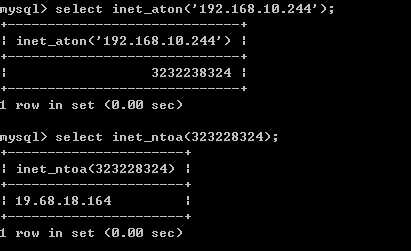
取出时:
(4)根据需求选择最小整数类型。比如用户在线状态:离线,在线,离开,忙碌,隐式等,可以采用0,1,2,3,5来表示,没有必要用char()或varchar()型来存储字符串。
3、myisam表的定时维护
对于myisam 存储引擎而言,需要定时执行optimize table 表名,通过optimize table语句可以消除删除和更新造成的磁盘碎片,从而减少空间的浪费。
create table temp2( id int) engine=MyISAM;
insert into temp2 values(1);
在之前数据的容量:
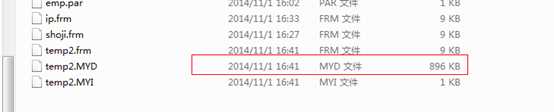
语法格式:optimize table 表名:
清理完成碎片之后。

以上是关于常见数据库的优化方式的主要内容,如果未能解决你的问题,请参考以下文章