Kafka
Posted holyqueen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka相关的知识,希望对你有一定的参考价值。
一.kafka是什么
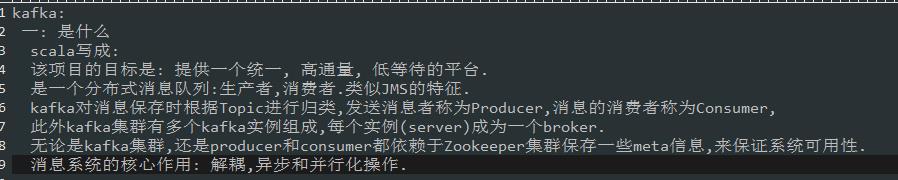
二.它与传统jms不同的地方.
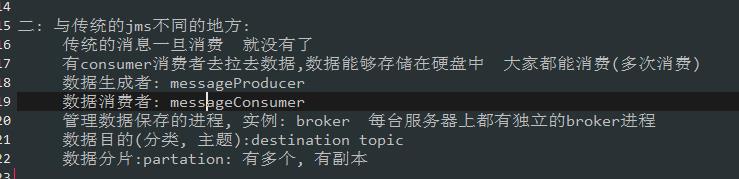
三: 组成部分,主要是有哪些组件组成

四: Consumer和topic的关系.

1.消息队列消费者消费了重复的数据? 怎么去避免.
把kafka消费者的配置enable.auto.commit设为false,禁止kafka自动提交offset,自动提交的时候数据没有完成消费的情况下也能够提交offset

简单概括为(拿大神的词汇用用):
Kafka框架:
producer生产者
consumer消费者
broker篮子
topic给馒头打一个标签,具体给谁吃的馒头
生产者生产的消息可以有多个消费者去拉取进行消费 .可以是一对一 也可以是多对多,也可以一对多和多对一
五、
给每个消息增加全局的ID,类似于订单的ID,消费的时候去对比一下,之前是否消费过。多消费一样的,Kafka是发布订阅的消息队列
上个消费者消费后你标记了,下一个消费者怎么判断,统一的放进redis去比较,还有你刚才说的故障容错,消息会被接管,那两个消息是相同的吗
用redis set消息队列消息丢失了,天然的幂等性
六、
如何保证消息队列的消息不要丢失?
换句话说如何保证消息队列的数据不要丢失
这个问题有这种情况
一种是mq自己弄丢了
另外一种情况是消费者把数据弄丢了消费者消费后给一个返回值 看是否弄丢 弄丢了再给去弄一个?
先说rabbitMq,生产者丢失数据,rabbitmq是提供事物功能的
在生产数据之前开启事物,数据如果没有被ra收到,就会异常的报错,就可以回滚事物
但是,打开事物会影响性能的,还有一个方案,开启confirm模式,你每次写的消息都会分配一个唯一的id
如果写入rabbitmq,就会返回一个ack,告诉你消息OK了
如果rabbitmq没能处理这个消息,就会回调nack接口,告诉你消息接收失败,可以重试
第二mq丢失消息,开启rabbitmq持久化,将消息持久化到磁盘中,就算mq挂了,数据也不会丢失,这是rabbitMq(通常用于核心业务)。
消费端弄丢了数据,Kafka默认的是自动提交offset,应该变成手动提交 ,这样消费端不就弄不丢数据
kafka弄丢了数据,某个broker宕机,其他的顶上
这里面有数据是不是最新的问题,也就是leader和follower数据没有同步,数据还是丢了
这个时候配置参数,给这个topic设置replication.factor参数,这个值必须大于1,要求每个partition必须有至少2个副本,kafka服务端设置min.insync.replicas参数:这个值必须大于1
这个是要求一个leader至少感知到有至少一个follower还跟自己保持联系,没掉队,这样才能确保leader挂了还有一个follower吧
ISR表中,
在producer端设置acks=all:,这个是要求每条数据,必须是写入所有replica之后,才能认为是写成功了
还有一个ISR表
记录着那些follower和自己的数据时差不多一致的
现在就是拉的时候要保证数据已经是一致的时候才能够拉取了
如果在某个时间之内,leader和follower不一致就会从这个isr表中剔除掉,这就是kafka的保障机制
(它这种剔除只是暂时的,没说数据就没法传输了)
七、
操作kafka的一些命令:
创建topic
bin/kafka-topics.sh --create --zookeeper 139.129.21.117:2181 --replication-factor 1 --partitions 1 --topic test
查看topic
bin/kafka-topics.sh --list --zookeeper 139.129.21.117:2181
发送消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
消费消息
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
前台启动
./kafka-server-start.sh /usr/local/kafka_2.10-0.8.1.1/config/server.properties
后台启动
./kafka-server-start.sh -daemon /usr/local/kafka_2.10-0.8.1.1/config/server.properties
八、
分布式和集群区别?

每个节点都有元数据,而且都是一样的,等于说,复制一份,放在另外一个节点上
分布式呢,是=元数据分布在不同的节点上。
eg:
纯天然Elasticsearch分布式的
Solr可以做成集群
RabbitMq不是分布式的
Kafka是分布式的
九、
下次再议:
LEO表示每个partition的log最后一条Message的位置
HW:最高水位线
以上是关于Kafka的主要内容,如果未能解决你的问题,请参考以下文章
大数据技术之KafkaKafka APIKafka监控Flume对接KafkaKafka面试题