第一次作业:深入源码分析进程模型
Posted 柠叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次作业:深入源码分析进程模型相关的知识,希望对你有一定的参考价值。
1. 前言Linux操作系统的简易介绍
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。
(1)内核
内核是操作系统的核心,具有很多最基本功能,如虚拟内存、多任务、共享库、需求加载、可执行程序和TCP/IP网络功能。Linux内核的模块分为以下几个部分:存储管理、CPU和进程管理、文件系统、设备管理和驱动、网络通信、系统的初始化和系统调用等。
(2)shell
shell是系统的用户界面,提供了用户与内核进行交互操作的一种接口。它接收用户输入的命令并把它送入内核去执行,是一个命令解释器。另外,shell编程语言具有普通编程语言的很多特点,用这种编程语言编写的shell程序与其他应用程序具有同样的效果。
(3)文件系统
文件系统是文件存放在磁盘等存储设备上的组织方法。Linux系统能支持多种目前流行的文件系统,如EXT2、EXT3、FAT、FAT32、VFAT和ISO9660。
(4)应用程序
标准的Linux系统一般都有一套都有称为应用程序的程序集,它包括文本编辑器、编程语言、XWindow、办公套件、Internet工具和数据库等。
2.Linux操作系统的进程组织
(1)什么是进程
进程是处于执行期的程序以及它所包含的所有资源的总称,包括虚拟处理器,虚拟空间,寄存器,堆栈,全局数据段等。
在Linux中,每个进程在创建时都会被分配一个数据结构,称为进程控制(Process Control Block,简称PCB)。PCB中包含了很多重要的信息,供系统调度和进程本身执行使用。所有进程的PCB都存放在内核空间中。PCB中最重要的信息就是进程PID,内核通过这个PID来唯一标识一个进程。PID可以循环使用,最大值是32768。init进程的pid为1,其他进程都是init进程的后代。
除了进程控制块(PCB)以外,每个进程都有独立的内核堆栈(8k),一个进程描述符结构,这些数据都作为进程的控制信息储存在内核空间中;而进程的用户空间主要存储代码和数据。
(2)进程创建

1 #代码示例:
2 #include <stdio.h>
3 #include <stdlib.h>
4 #include <unistd.h>
5
6 int main (int argc, char ** argv) {
7 int flag = 0;
8 pid_t pId = fork();
9 if (pId == -1) {
10 perror("fork error");
11 exit(EXIT_FAILURE);
12 } else if (pId == 0) {
13 int myPid = getpid();
14 int parentPid = getppid();
15
16 printf("Child:SelfID=%d ParentID=%d \\n", myPid, parentPid);
17 flag = 123;
18 printf("Child:flag=%d %p \\n", flag, &flag);
19 int count = 0;
20 do {
21 count++;
22 sleep(1);
23 printf("Child count=%d \\n", count);
24 if (count >= 5) {
25 break;
26 }
27 } while (1);
28 return EXIT_SUCCESS;
29 } else {
30 printf("Parent:SelfID=%d MyChildPID=%d \\n", getpid(), pId);
31 flag = 456;
32 printf("Parent:flag=%d %p \\n", flag, &flag); // 连地址都一样,说明是真的完全拷贝,但值已经是不同的了..
33 int count = 0;
34 do {
35 count++;
36 sleep(1);
37 printf("Parent count=%d \\n", count);
38 if (count >= 2) {
39 break;
40 }
41 } while (1);
42 }
43
44 return EXIT_SUCCESS;
45 }
(3)进程撤销
进程通过调用exit()退出执行,这个函数会终结进程并释放所有的资源。父进程可以通过wait4()查询子进程是否终结。进程退出执行后处于僵死状态,直到它的父进程调用wait()或者waitpid()为止。父进程退出时,内核会指定线程组的其他进程或者init进程作为其子进程的新父进程。当进程接收到一个不能处理或忽视的信号时,或当在内核态产生一个不可恢复的CPU异常而内核此时正代表该进程在运行,内核可以强迫进程终止。
(4)进程管理
内核把进程信息存放在叫做任务队列(task list)的双向循环链表中(内核空间)。链表中的每一项都是类型为task_struct,称为进程描述符结构(process descriptor),包含了一个具体进程的所有信息,包括打开的文件,进程的地址空间,挂起的信号,进程的状态等。
struct task_struct
{
volatile long state;
pid_t pid;
unsigned long timestamp;
unsigned long rt_priority;
struct mm_struct *mm, *active_mm
}
对于向下增长的栈来说,只需要在栈底(对于向上增长的栈则在栈顶)创建一个新的结构struct thread_info,使得在汇编代码中计算其偏移量变得容易。
#在x86上,thread_info结构在文件<asm/thread_info.h>中定义如下:
struct thread_info{ struct task_struct *任务 struct exec_domain *exec_domain; unsigned long flags; unsigned long status; __u32 cpu; __s32 preempt_count; mm_segment_t addr_limit; struct restart_block restart_block; unsigned long previous_esp; _u8 supervisor_stack[0]; };
内核把所有处于TASK_RUNNING状态的进程组织成一个可运行双向循环队列。调度函数通过扫描整个可运行队列,取得最值得执行的进程投入执行。避免扫描所有进程,提高调度效率。
#进程调度使用schedule()函数来完成,下面我们从分析该函数开始,代码如下:
1 asmlinkage __visible void __sched schedule(void)
2 {
3 struct task_struct *tsk = current;
4
5 sched_submit_work(tsk);
6 __schedule();
7 }
8 EXPORT_SYMBOL(schedule);
#在第4段进程调度中将具体讲述功能实现
3.Linux操作系统的进程状态转换
有以下进程状态:
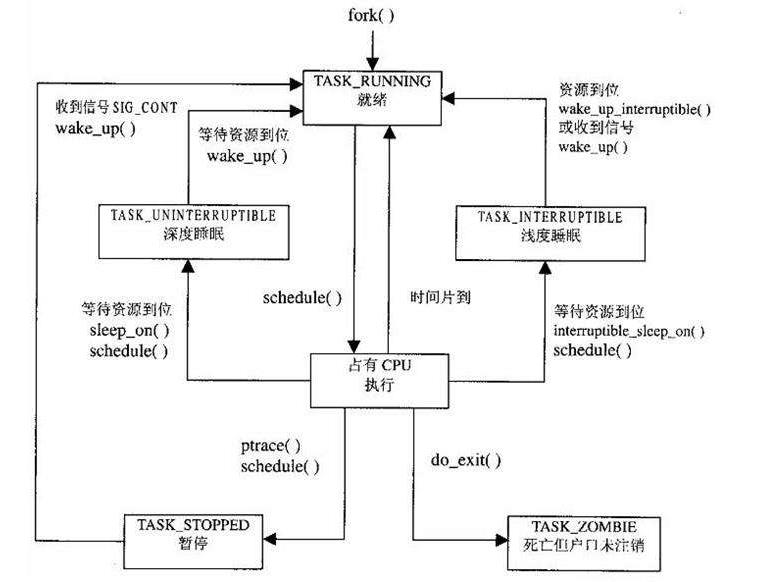
进程状态的转换:

具体转换分析:
(1)进程的初始状态
进程是通过fork系列的系统调用(fork、clone、vfork)来创建的,内核(或内核模块)也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有。)那么既然调用进程处于TASK_RUNNING状态(否则,它若不是正在运行,又怎么进行调用?),则子进程默认也处于TASK_RUNNING状态。另外,在系统调用调用clone和内核函数kernel_thread也接受CLONE_STOPPED选项,从而将子进程的初始状态置为 TASK_STOPPED。
(2)进程状态变迁
进程自创建以后,状态可能发生一系列的变化,直到进程退出。而尽管进程状态有好几种,但是进程状态的变迁却只有两个方向——从TASK_RUNNING状态变为非TASK_RUNNING状态、或者从非TASK_RUNNING状态变为TASK_RUNNING状态。也就是说,如果给一个TASK_INTERRUPTIBLE状态的进程发送SIGKILL信号,这个进程将先被唤醒(进入 TASK_RUNNING状态),然后再响应SIGKILL信号而退出(变为TASK_DEAD状态)。并不会从TASK_INTERRUPTIBLE状态直接退出。进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
而进程从TASK_RUNNING状态变为非TASK_RUNNING状态,则有两种途径:
- 响应信号而进入TASK_STOPED状态、或TASK_DEAD状态;
- 执行系统调用主动进入TASK_INTERRUPTIBLE状态(如nanosleep系统调用)、或TASK_DEAD状态(如exit 系统调用);或由于执行系统调用需要的资源得不到满足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
4.Linux操作系统的进程调度
毋庸置疑,我们使用schedule()函数来完成进程调度,接下来就来看看进程调度的代码以及实现过程吧。
1 asmlinkage __visible void __sched schedule(void)
2 {
3 struct task_struct *tsk = current;
4
5 sched_submit_work(tsk);
6 __schedule();
7 }
8 EXPORT_SYMBOL(schedule);
第3行获取当前进程描述符指针,存放在本地变量tsk中。第6行调用__schedule(),代码如下(kernel/sched/core.c):
 static void __sched __schedule(void)
static void __sched __schedule(void)
第9行禁止内核抢占。第10行获取当前的cpu号。第11行获取当前cpu的进程运行队列。第13行将当前进程的描述符指针保存在prev变量中。第55行将下一个被调度的进程描述符指针存放在next变量中。第56行清除当前进程的内核抢占标记。第60行判断当前进程和下一个调度的是不是同一个进程,如果不是的话,就要进行调度。第65行,对当前进程和下一个进程的上下文进行切换(调度之前要先切换上下文)。下面看看该函数(kernel/sched/core.c):
context_switch(struct rq *rq, struct task_struct *prev, struct task_struct *next)
上下文切换一般分为两个,一个是硬件上下文切换(指的是cpu寄存器,要把当前进程使用的寄存器内容保存下来,再把下一个程序的寄存器内容恢复),另一个是切换进程的地址空间(说白了就是程序代码)。进程的地址空间(程序代码)主要保存在进程描述符中的struct mm_struct结构体中,因此该函数主要是操作这个结构体。第17行如果被调度的下一个进程地址空间mm为空,说明下个进程是个线程,没有独立的地址空间,共用所属进程的地址空间,因此第18行将上个进程所使用的地址空间active_mm指针赋给下一个进程的该域,下一个进程也使用这个地址空间。第22行,如果下个进程地址空间不为空,说明下个进程有自己的地址空间,那么执行switch_mm切换进程页表。第40行切换进程的硬件上下文。 switch_to函数代码如下(arch/x86/include/asm/switch_to.h):
__visible __notrace_funcgraph struct task_struct * __switch_to(struct task_struct *prev_p, struct task_struct *next_p)该函数主要是对刚切换过来的新进程进一步做些初始化工作。比如第34将该进程使用的线程局部存储段(TLS)装入本地cpu的全局描述符表。第84行返回语句会被编译成两条汇编指令,一条是将返回值prev_p保存到eax寄存器,另外一个是ret指令,将内核栈顶的元素弹出eip寄存器,从这个eip指针处开始执行,也就是上个函数第17行所压入的那个指针。一般情况下,被压入的指针是上个函数第20行那个标号1所代表的地址,那么从__switch_to函数返回后,将从标号1处开始运行。
需要注意的是,对于已经被调度过的进程而言,从__switch_to函数返回后,将从标号1处开始运行;但是对于用fork(),clone()等函数刚创建的新进程(未调度过),将进入ret_from_fork()函数,因为do_fork()函数在创建好进程之后,会给进程的thread_info.ip赋予ret_from_fork函数的地址,而不是标号1的地址,因此它会跳入ret_from_fork函数。后边我们在分析fork系统调用的时候,就会看到。
5.对于Linux操作系统进程模型的一些个人看法
就像人类基于理论实践伟大的工程设计智慧经验结晶,Linux操作系统是系统、效率、安全的,而且通过商业公司、庞大的社区群体、操作系统爱好者是在往前改善的,但如果有一天Linux操作系统闭源了,只有国内开放了源代码,还尚未掌握核心技术,卡住脖子怎么办?我们不能拥有完完全全拿来即用的心态,还需扎实掌握基础知识,提高自我创新意识。对于Linux操作系统进程模型,深入理解它,你会发现在Linux操作系统的应用实践上会愈加效率,同时通过它你可以实现更多好玩的操作。
以上是关于第一次作业:深入源码分析进程模型的主要内容,如果未能解决你的问题,请参考以下文章