数据挖掘_多进程抓取
Posted susmote
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘_多进程抓取相关的知识,希望对你有一定的参考价值。

之前说过Python的多线程只能运行在一个单核上,也就是各线程是以并发的方式异步执行的
这篇文章我们来聊聊Python多进程的方式
多进程依赖于所在机器的处理器个数,在多核机器上进行多进程编程时,各核上运行的进程之间是并行执行的,可以利用进程池,是每一个内核上运行一个进程,当翅中的进程数量大于内核总数时,待运行的进程会等待,直至其他进程运行完毕让出内核
多进程就相当于下面这种卖票的行为
在这里要注意,当系统内只有一个单核CPU是,多进程并不会发生,此时各进程会依次占用CPU运行至完成
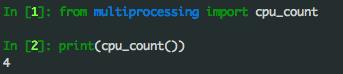
我们可以通过Python的语句会的CPU可用的核数,如下图
为了形成比较,我们还是使用之前的那个例子,当当图书,搜索关键字商品信息的抓取
首先写出多进程主方法
# coding=utf-8
__Author__ = "susmote"
from multi_threading import mining_func
import multiprocessing
import time
def multiple_process_test():
start_time = time.time()
page_range_list = [
(1, 10),
(11, 20),
(21, 32),
]
pool = multiprocessing.Pool(processes=3)
for page_range in page_range_list:
pool.apply_async(mining_func.get_urls_in_pages, (page_range[0], page_range[1]))
pool.close()
pool.join()
end_time = time.time()
print("抓取时间:", end_time - start_time)
return end_time - start_time
在这里面,我简单解释一下有关多进程的操作
pool被定义为可同时并行3个进程的进程池,然后通过循环,使用apply_async方法使进入进程池的进程以异步的方式并行运行
下面是主函数
# coding=utf-8
__Author__ = "susmote"
from process_func import multiple_process_test
if __name__ == "__main__":
pt = multiple_process_test()
print("pt : ", pt)
把代码运行起来,得到如下结果

5.908
再运行一次

3.954
最后一次

4.163
取平均时间

4.341秒
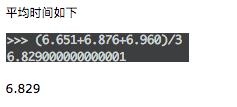
这时我们再回顾上篇文章多线程的情况(同样网络条件下):
多线程
单线程
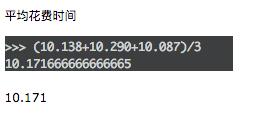
可以看到,差距非常明显,多进程占绝大优势
多进程就是这些,你也可以找一个更大的数据池,去试验这些方法
以上是关于数据挖掘_多进程抓取的主要内容,如果未能解决你的问题,请参考以下文章