爬虫大作业
Posted Fanchuguang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫大作业相关的知识,希望对你有一定的参考价值。
本人选取的主题是电影。
本次爬取的网址是电影票房网:http://58921.com/alltime?page=0
一、查看网页结构,我们需要先爬取排行榜中电影的链接
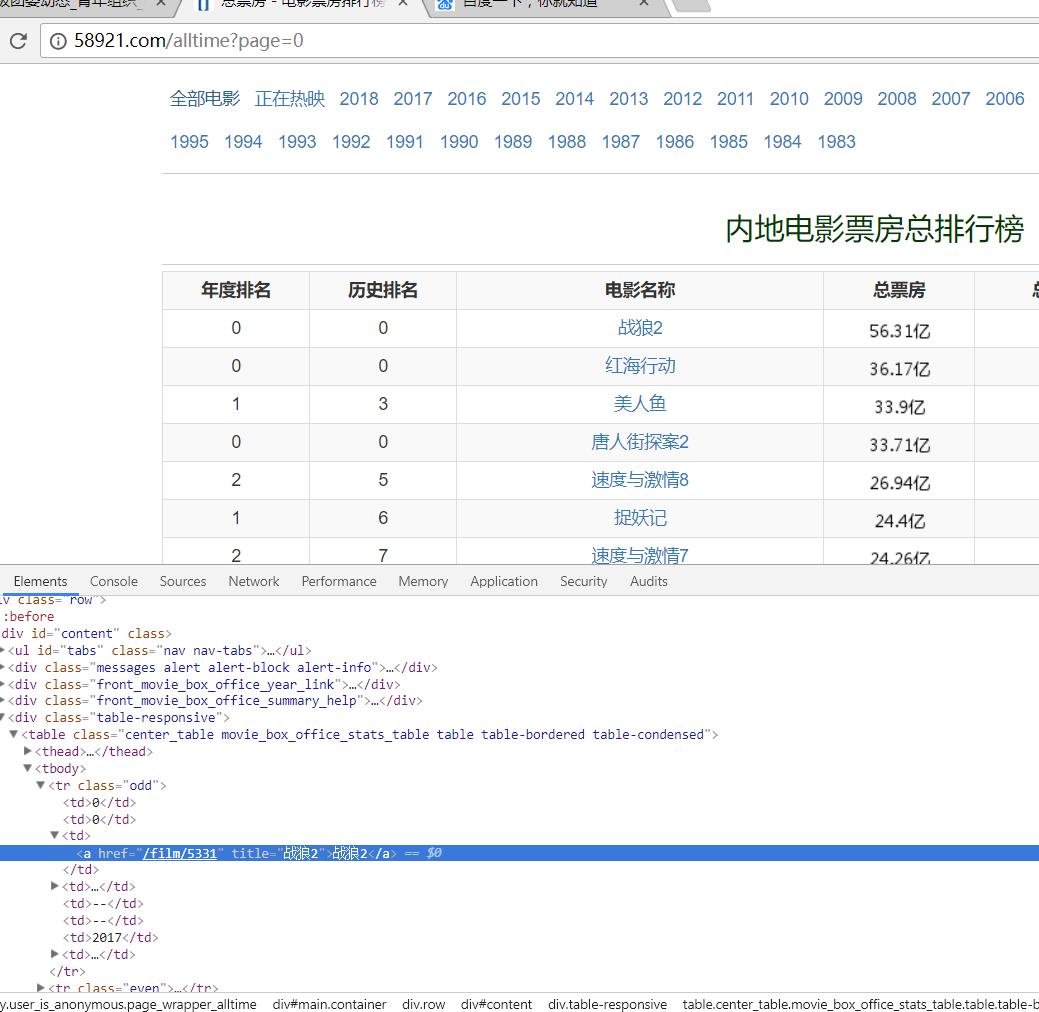
可以看到每一电影由\'.media-body\'装着,所以可以获取其标题连接:
def getListPage(pageUrl):
res=requests.get(pageUrl)
res.encoding=\'utf-8\'
soup = BeautifulSoup(res.text,\'html.parser\')
movieDirList = []
for movies in soup.select(\'tr\'):
hrefTop = "http://58921.com"
if len(movies.select(\'td\'))>0:
movieUrl = (hrefTop + movies.select(\'a\')[0].attrs[\'href\'])#链接
movieDirList.append(getMovieType(movieUrl))
print(movieDirList)
return (movieDirList);
进入电影详情界面,查看页面结构
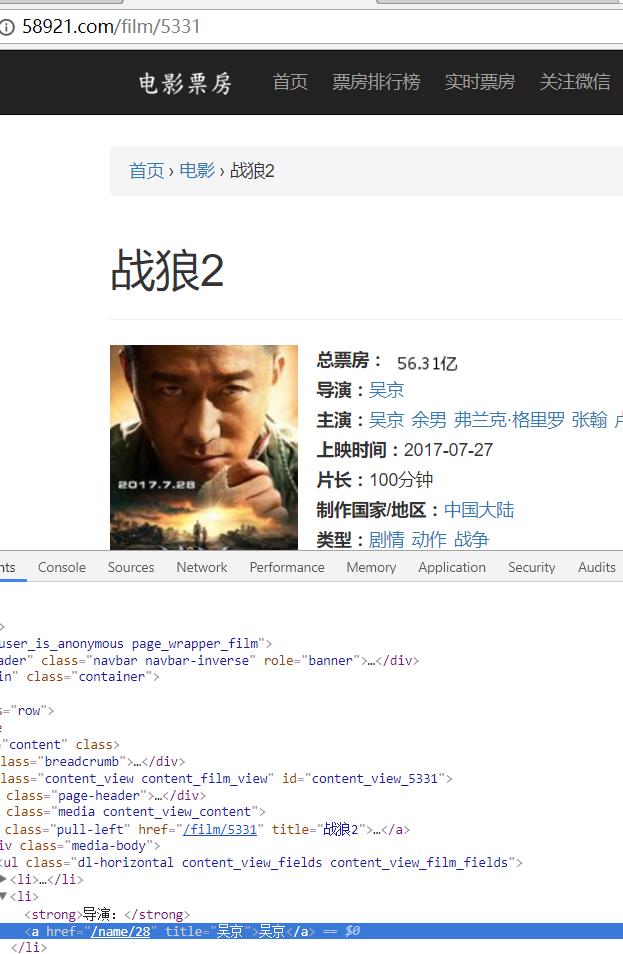
可以看出导演是在第二个li之中
def getMovieType(movieUrl):#查找每个电影详情里的导演名字
resd = requests.get(movieUrl)
resd.encoding = \'utf-8\'
soupd = BeautifulSoup(resd.text,\'html.parser\')
types = soupd.select(\'.media-body\')[0].select(\'li\')[1].select(\'strong\')[0].text
dirs = " "
if len(types) < 4:#如果导演标题超出4个字符
dirs = soupd.select(\'.media-body\')[0].select(\'li\')[1].text.strip().lstrip(\'导演:\').lstrip(\'主演:\')
return (dirs)
主程序:并将数据写入文档中
PageUrl=\'http://58921.com/alltime\'
dirTotal=[]
for i in range(0,1):
listPageUrl=\'http://58921.com/alltime?page={}\'.format(i)
dirTotal.extend(getListPage(listPageUrl))
for dirs in dirTotal:
print(dirs)
yundirs = []
f = open(\'movieDir.txt\',\'a\',encoding="utf-8")
for dirs in dirTotal:
f.write(dirs+"\\n")
yundirs = dirs
f.close()
词云代码:
from PIL import Image, ImageSequence
import numpy as np
import matplotlib.pyplot as plt
from wordcloud import WordCloud, ImageColorGenerator
font=r\'C:\\Windows\\Fonts\\simhei.TTF\'
image = Image.open(\'./dianying.jpg\')
graph = np.array(image)
wc = WordCloud(font_path=font,background_color=\'White\',max_words=50, mask=graph)
wc.generate_from_frequencies(yundirs)
image_color = ImageColorGenerator(graph)
plt.imshow(wc)
plt.axis("off")
plt.show()
词云实现:

以上是关于爬虫大作业的主要内容,如果未能解决你的问题,请参考以下文章