ServiceLoader
Posted lnlvinso
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ServiceLoader相关的知识,希望对你有一定的参考价值。
先从业务场景分析,要完成数据的分析处理功能。根据数据的不同种类,先调用groovy或者python脚本等中的一种处理数据,处理完数据的后需要流程相同。
要支持处理能力的动态扩展,也就是框架完成后,可以再增加新的处理能力,而不改变原有的代码。如要增加el处理数据的能力。
这时ServiceLoader可以方便的完成需求。
先看所需的模块。groovy,python模块是具体的处理模块。plat模块使用ServiceLoader调用groovy或者python模块,再完成后续处理。pon模块是一个业务测试模块
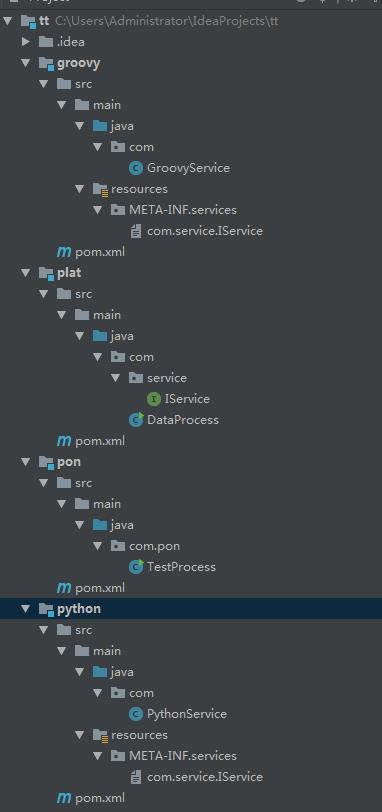
先看plat模块中的接口类IService:
package com.service; public interface IService { String getService(); String handle(); }
DataProcess类,ServiceLoader调用groovy或者python模块:
package com; import com.service.IService; import java.util.ServiceLoader; public class DataProcess {public IService getService(String name) { IService properService = null; ServiceLoader<IService> serviceLoader = ServiceLoader.load(IService.class); for (IService service : serviceLoader) { if (service.getService().equalsIgnoreCase(name)) { properService= service; } } return properService; } }
GroovyService,使用groovy处理数据的示例代码:
package com; import com.service.IService; public class GroovyService implements IService { public String getService() { return "groovy"; } public String handle() { return "groovy handle data"; } }
groovy模块下的resources下,要有META-INF\\services\\com.service.IService文件,内容如下:
com.GroovyService
再看业务测试模块pon下的测试类:
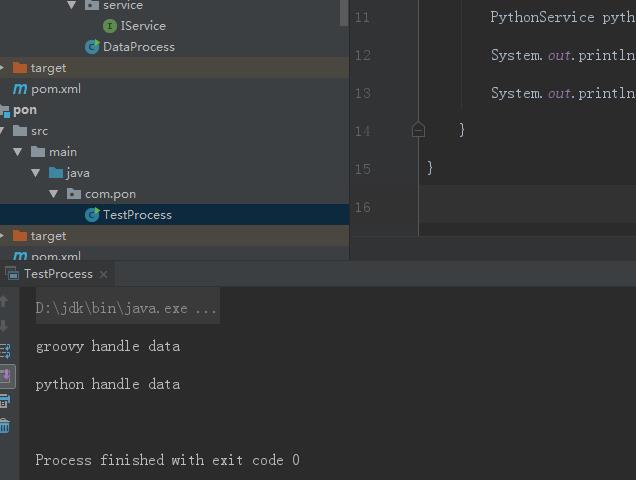
package com.pon; import com.GroovyService; import com.PythonService; import com.DataProcess; public class TestProcess { public static void main(String[] args) { DataProcess process = new DataProcess(); GroovyService groovyService = (GroovyService) process.getService("groovy"); PythonService pythonservice = (PythonService) process.getService("python"); System.out.println(groovyService.handle()); System.out.println(pythonservice.handle()); } }
测试的结果为:
需要增加el处理能力时,新增el模块,plat模块的处理不需要改变。
ServiceLoader会classpath下的jar包,分析META-INF/services中放置提供者配置文件来标识服务提供者。看看pon模块的依赖。

Hadoop FileSystem就是通过这个机制来根据不同文件的scheme来返回不同的FileSystem。
private static void loadFileSystems() { synchronized(FileSystem.class){ if(!FILE_SYSTEMS_LOADED) { ServiceLoader<FileSystem> serviceLoader = ServiceLoader.load(FileSystem.class); for(FileSystem fs : serviceLoader) { SERVICE_FILE_SYSTEMS.put(fs.getScheme(),fs.getClass()); } FILE_SYSTEMS_LOADED= true; } } }
对应的配置文件:
org.apache.hadoop.fs.LocalFileSystem
org.apache.hadoop.fs.viewfs.ViewFileSystem
org.apache.hadoop.fs.s3.S3FileSystem
org.apache.hadoop.fs.s3native.NativeS3FileSystem
org.apache.hadoop.fs.kfs.KosmosFileSystem
org.apache.hadoop.fs.ftp.FTPFileSystem
org.apache.hadoop.fs.HarFileSystem
可以看到FileSystem会把所有的FileSystem的实现都以scheme和class来cache,之后就从这个cache中取相应的值。因此,以后可以通过ServiceLoader来实现一些类似的功能,而不用依赖像Spring这样的第三方框架。
以上是关于ServiceLoader的主要内容,如果未能解决你的问题,请参考以下文章