跨平台渲染框架尝试 - constant buffer的管理
Posted IndignantAngel
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跨平台渲染框架尝试 - constant buffer的管理相关的知识,希望对你有一定的参考价值。
1. Preface
Constant buffer是我们在编写shader的时候,打交道最多的一种buffer resource了。constant表明了constant buffer中的数据,在一次draw call的执行过程中都是不变的;而在不同的draw call之间,我们可以修改其中的数据。它是我们把数据从CPU传递到GPU最常见的方法。constant buffer的概念和定义就不在这里赘述了,鄙文主要讨论如何优雅的管理constant buffer.
2. How to create and manipulate constant buffer gracefully.
Constant buffer在各种api中都有很好的支持,如在DX11中,以cbuffer为类型的闭包,可以定义一个constant buffer.
1 cbuffer Transforms 2 { 3 matrix world; 4 matrix view_project; 5 matrix skin[32]; 6 }; 7 8 cbuffer change_every_frame 9 { 10 float3 light_positoin; 11 float4 light_color; 12 }; 13 14 float4 dummy_vec4_variable;
cbuffer可以根据你自己对它的功能或者buffer数据改变的策略来定义。在DX11中,我通过shader reflection的接口发现,没有在cbuffer闭包中的变量,都会被放到一个名叫@Globals的constant buffer中。当然这也取决你的fxc.exe的版本。其实让我们苦恼的并不是如何使用DX或者GL等这些api创建一个constant buffer对象,而是我们为了使用constant buffer,通常情况下需要在我们的引擎或者客户端的程序代码中,创建一个内存布局和大小与GPU端统一的数据结构。例如,我们要使用 transforms和change_every_frame这两个cbuffer,我们还要写这些C++的代码。
struct transform
{
your_matrix_type world_matrix;
your_matrix_type view_project_matrix;
your_skin_matrices skin_matrices[32];
};
struct change_every_frame
{
your_float3_type light_positoin;
your_float_type pack;
yourefloat4_type light_color;
};
这是一件很让人困扰的事情。首先,如果你开发了一个新的shader并使用了一个新的cbuffer的定义,那么你不得不修改你的引擎或者客户端代码。添加新的数据结构,还有使用和更新的代码。如果是这样,我们的程序或者引擎的扩展性就太差了!其次,你得非常小心的处理constant buffer内存布局的规则,否则你的数据不会正确的传递。例如,light_position后面要更一个float作为补位。我们应该把这些交给程序自己,而不是自己来做重复的工作。在C++中,我们必须要把这些与类型相关,也就是受限于编译期的,改成到运行期当中来计算。管理的基本方法如图所示:
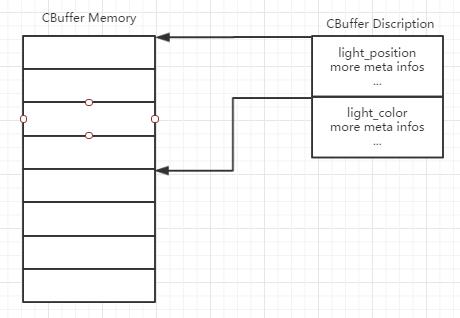
我将一个cbuffer分成的两个部分,一个大小跟GPU中cbuffer大小一致的memory block,和一个对cbuffer各个成员的描述meta data. 如何来实现呢?在最开始,我们需要一个枚举来描述所有的基本类型,例如float,float3,float4x4,这是从编译期转向运行期的第一步。
1 enum class data_format
2 {
3 float_, float2, float3, float4,
4 float2x2, float2x3, float2x4,
5 float3x2, float3x3, float3x4,
6 float4x2, float4x3, float4x4,
7 int_, int2, int3, int4,
8 uint, uint2, uint3, uint4,
9 structured,
10 };
然后,我们需要一个结构体来描述整个constant buffer,例如change_every_frame这个cbuffer,我们要描述整个buffer的大小,light_color的data format,还有相对于cbuffer头地址的偏移量等。并且还要支持在cbuffer中使用结构体和数组。所以这个结构体应该是自递归的。如下面的代码
1 // numeric layout 2 class numeric_layout 3 { 4 using sub_var_container = std::vector<numeric_layout>; 5 static constexpr size_t sub_count = 8; 6 7 public: 8 // construct 9 numeric_layout(data_format format, uint16_t count, uint16_t size, uint16_t offset) 10 : format_(format) 11 , count_(count) 12 , size_(size) 13 , offset_(offset) 14 { 15 sub_variables_.reserve(sub_count); 16 } 17 18 template <typename T> 19 numeric_layout(large_class_wrapper<T> t) 20 : numeric_layout( 21 data_format::structured, 1, 22 structure_size<T>::value, 0) 23 { 24 detail::init_variable_layout_from_tuple(*this, t); 25 } 26 27 // attribute access 28 data_format format() const noexcept 29 { 30 return format_; 31 } 32 33 uint16_t count() const noexcept 34 { 35 return count_; 36 } 37 38 uint16_t size() const noexcept 39 { 40 return size_; 41 } 42 43 uint16_t offset() const noexcept 44 { 45 return offset_; 46 } 47 48 // sub variables 49 void add_sub(data_format format, uint16_t count, uint16_t size, uint16_t offset) 50 { 51 //assert(data_format::structured != format_); 52 assert(offset + size <= size_); 53 54 sub_variables_.emplace_back(format, count, size, offset); 55 } 56 57 numeric_layout& operator[] (size_t index) 58 { 59 return sub_variables_[index]; 60 } 61 62 numeric_layout const& operator[] (size_t index) const 63 { 64 return sub_variables_[index]; 65 } 66 67 private: 68 data_format format_; 69 uint16_t count_; 70 uint16_t size_; 71 uint16_t offset_; 72 sub_var_container sub_variables_; 73 };
在我们编译自己的shader之前,还需要多做一件事情,就是解析shader code中的cbuffer,把这些meta data都获取出来,创建好我们的numeric_layout对象。自己写的constant_buffer类如下:
1 template<>
2 struct buffer_traits<constant_buffer>
3 {
4 static constexpr object_type type() noexcept
5 {
6 return object_type::constant_buffer;
7 }
8 };
9
10 class constant_buffer : public buffer<constant_buffer>
11 {
12 using base_type = buffer<constant_buffer>;
13
14 public:
15 constant_buffer(string&& name, numeric_layout&& layout)
16 : base_type(std::move(name), layout.size(), 1, device_access::write, device_access::read)
17 , layout_(std::move(layout))
18 {
19 allocate();
20 }
21
22 constant_buffer(string&& name, numeric_layout const& layout)
23 : base_type(std::move(name), layout.size(), 1, device_access::write, device_access::read)
24 , layout_(layout)
25 {
26 allocate();
27 }
28
29 void resize(numeric_layout&& layout)
30 {
31 auto elem_size = layout.size();
32 base_type::resize(elem_size, 1);
33 layout_ = std::move(layout);
34 }
35
36 numeric_variable operator[](size_t index)
37 {
38 return{ layout_[index], data() };
39 }
40
41 private:
42 numeric_layout layout_;
43 };
这个是基于之前的buffer和resource之上写的,对resource和buffer还有texture的管理和设计可以参阅之前的随笔,还有这个很low的仓库。
当然,都已经解析了cbuffer,讲道理应该把整个shader codes都解析一遍,创建一个完整的effect框架。这部分的功能,我正在研究和开发中,希望能顺利完成并同大家分享。然后在渲染框架的与平台无关的代码部分,抽象一个constant buffer类型,并使用这个numeric_layout创建与平台无关的constant buffer对象。有了这个constant buffer对象,平台相关的代码就有足够多的信息正确创建设备上的cbuffer的对象了,无论是dx还是gl. 那么总体的流程如图:
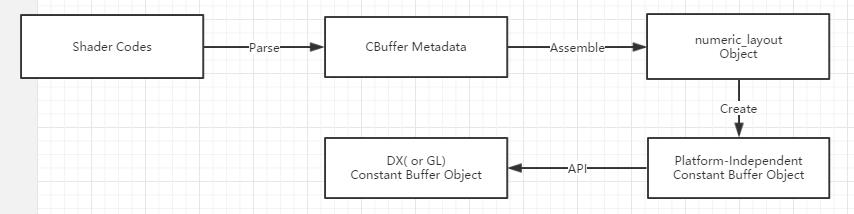
在很多图形api中,对cbuffer的部分更新做的并不是很好,如只更新change_every_frame中的light_color分量。DX的UpdateSubresource无法实现,gl3.1之后有了ubo,才可以使用glSetBufferSubData来实现。在我们管理的cbuffer下,我们可以部分更新cpu中的cbuffer的memory,在一起update到gpu上来模拟这种部分更新的实现。
3. Use the powerful compile time computation of C++ to manipulate constant buffer
接下来聊聊如何利用C++新标准强大的编译期计算来方便我们创建cbuffer. 上述将编译期迁移到运行期的方法,很适合在渲染框架中使用。运行期化的代码,虽然能解决问题,但是创建的过程还是比较复杂。在我们写实验和测试的代码这类很小的程序,上图的流程就显的笨重了。所以,我在实现numeric_layout的时候,提供了使用用户自定义类型来创建cbuffer的metadata的方法,以便小型程序使用。使用起来非常简单,代码如下:
1 // test constant buffer
2 struct global_cbuffer
3 {
4 float3 light_position;
5 float4 ambient_color;
6 float4 diffuse_color;
7 float4x4 model_view;
8 float3 light_direction;
9 };
10
11 BOOST_FUSION_ADAPT_STRUCT(
12 global_cbuffer,
13 (float3, light_position)
14 (float4, ambient_color)
15 (float4, diffuse_color)
16 (float4x4, model_view)
17 (float3, light_direction)
18 );
19
20 void test_constant_buffer()
21 {
22 numeric_layout_t layout = wrap_large_class<global_cbuffer>();
23 constant_buffer_t cbuffer{ "global cbuffer", std::move(layout) };
24 }
首先定义自定义的cbuffer的结构体,跟shader code中的一模一样的结构体;然后使用boost::fusion做编译期的反射;最后使用numeric_layout的另外一个构造函数创建cbuffer的metadata,共cbuffer创建使用。这里用了几个技巧。
1. 使用large_class_wrapper<T>来避免不必要的栈内存分配。由于定义我们的constant buffer的数据结构往往是一个结构体,而我们创建numeric_layout对象并不需要这个结构体的实例或者实例的引用,只需要编译期的反射信息。我们没有必要去创建一个无用的对象,而是把类型传递给large_class_wrapper<T>类模板,让它带上类型信息,但是这个类模板本身是一个空类,大小为1,甚至会被编译期优化掉。所以这里使用large_class_wrapper<T>可以避免不比较的内存开销。
2. 使用编译期计算C++的结构体在gpu中的大小。具体算法就是按照微软constant buffer内存对齐的规则文档来构建的。在实现中使用了index_sequence展开参数,编译期整形向16对齐,递归模板和模板特化等技巧,详细代码如下:
1 namespace detail
2 {
3 template <size_t Reg, size_t Offset>
4 struct structure_size_helper
5 {
6 static constexpr size_t reg = Reg;
7 static constexpr size_t offset = Offset;
8 };
9
10 template <typename Helper, typename ... Args>
11 struct structure_size_impl_expand_impl;
12
13 template <typename Helper, typename T>
14 struct export_calculate_result
15 {
16 using traits_t = array_traits<T>;
17 using numeric_traits_t = typename traits_t::numeric_traits_t;
18 using helper_t = Helper;
19
20 static constexpr size_t count = traits_t::count;
21 static constexpr size_t numeric_size = numeric_traits_t::size();
22 static constexpr size_t numeric_reg = numeric_traits_t::reg();
23
24 static constexpr bool new_four_component =
25 (count > 1) || (helper_t::reg + numeric_reg >= 4);
26
27 static constexpr size_t new_reg = new_four_component ?
28 0 : (helper_t::reg + numeric_reg) % 4;
29 static constexpr size_t new_size = new_four_component ?
30 align<16>(helper_t::offset) + numeric_size : helper_t::offset + numeric_size;
31 };
32
33 template <typename Helper, typename First, typename ... Rests>
34 struct structure_size_impl_expand_impl<Helper, First, Rests...> : export_calculate_result<Helper, First>
35 {
36 using next_helper = structure_size_helper<new_reg, new_size>;
37 using next_type = structure_size_impl_expand_impl<next_helper, Rests...>;
38 static constexpr size_t value = next_type::value;
39 };
40
41 template <typename Helper, typename Last>
42 struct structure_size_impl_expand_impl<Helper, Last>
43 : export_calculate_result<Helper, Last>
44 {
45 static constexpr size_t value = align<16>(new_size);
46 };
47
48 template <typename T, typename Indices>
49 struct structure_size_impl;
50
51 template <typename ... Args>
52 struct structure_size_impl_expand
53 {
54 static constexpr size_t value = structure_size_impl_expand_impl
55 <structure_size_helper<0,0>, Args...>::value;
56 };
57
58 template <typename T, size_t ... Is>
59 struct structure_size_impl<T, std::index_sequence<Is...>>
60 {
61 static constexpr size_t value = structure_size_impl_expand<
62 type_at<T, Is>...>::value;
63 };
64 }
65
66 template <typename T>
67 struct structure_size
68 {
69 static_assert(is_sequence<T>::value, "!!!");
70 static constexpr size_t size = sequence_size<T>::value;
71
72 static constexpr size_t value = detail::structure_size_impl<
73 T, std::make_index_sequence<size>>::value;
74 };
3. 最后从struct初始化的时候,使用了bool[]数组配合index_sequence展开struct中的每一个分量,分别计算meta信息,调用numeric_layout::add_sub逐一创建。计算的方法同编译期类似,代码如下:
1 namespace detail
2 {
3 struct offset_register
4 {
5 uint16_t offset;
6 uint16_t reg;
7 };
8
9 template <typename T>
10 void bind_numeric(numeric_layout& layout, offset_register& helper)
11 {
12 using traits_t = array_traits<T>;
13 using traits_type = typename traits_t::numeric_traits_t;
14
15 // get the current register position
16 auto reg = detail::reg_size(traits_type::format());
17
18 // if we need to begin a new four component ?
19 auto begin_new_four_component = traits_t::count > 1 || reg + helper.reg >= 4;
20 if (begin_new_four_component)
21 {
22 helper.reg = 0;
23 helper.offset = detail::align<16>(helper.offset);
24 }
25
26 // calculate the size of current variable
27 auto size = detail::size_of(traits_type::format(), traits_t::count);
28
29 // add the container
30 layout.add_sub(traits_type::format(), traits_t::count, size, helper.offset);
31
32 // update helper object, which acts like a context of this calculation process
33 helper.offset += size;
34 helper.reg += reg & 0x03; // helper.reg = (helper.reg + reg) % 4
35 }
36
37 template <typename T, size_t ... Is>
38 void init_variable_layout_from_tuple(numeric_layout& layout, large_class_wrapper<T> tuple, std::index_sequence<Is...> seq)
39 {
40 offset_register helper = { 0, 0 };
41 using swallow_t = bool[];
42
43 swallow_t s = { (bind_numeric<type_at<T, Is>>(layout, helper), true)... };
44 }
45
46 template <typename T>
47 void init_variable_layout_from_tuple(numeric_layout& layout, large_class_wrapper<T> tuple)
48 {
49 init_variable_layout_from_tuple(layout, tuple, std::make_index_sequence<sequence_size<T>::value>{});
50 }
51 }
目前还不支持struct中嵌套struct,我想不久的将来应该会支持的。
4. Tail
constant buffer曾经是我引擎开发工作当中一个比较痛苦的环节,每写一个shader,每多一个effect就得在C++代码中添加相应的数据结构和逻辑显得很DRY。而后错误的更新cbuffer招致的痛苦的调试过程也是历历在目。还有当我看到maya的cgfx如此灵活和强大功能更让我觉得cbuffer是得好好管理一下了。Powered by modern cpp and modern graphics api,希望我自己实现的渲染框架,可以在不添加一行C++代码的同时,还能高效的正确渲染新加入的effect,杜绝DRY的设计和实现。
以上是关于跨平台渲染框架尝试 - constant buffer的管理的主要内容,如果未能解决你的问题,请参考以下文章