Spark UnifiedMemoryManager和StaticMemoryManager
Posted dabokele
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark UnifiedMemoryManager和StaticMemoryManager相关的知识,希望对你有一定的参考价值。
在Spark-1.6.0中,引入了一个新的参数spark.memory.userLegacyMode(默认值为false),表示不使用Spark-1.6.0之前的内存管理机制,而是使用1.6.0中引入的动态内存分配这一概念。
从SparkEnv.scala的源码中可以看到,该参数设置为true或false,主要影响到构造memoryManager的类的不同:
val useLegacyMemoryManager = conf.getBoolean("spark.memory.useLegacyMode" , false)
val memoryManager: MemoryManager =
if (useLegacyMemoryManager) {
new StaticMemoryManager(conf , numUsableCores)
} else {
UnifiedMemoryManager(conf , numUsableCores)
} StaticMemoryManager和UnifiedMemoryManager都是从MemoryManager抽象类继承而来,类继承关系如下图:
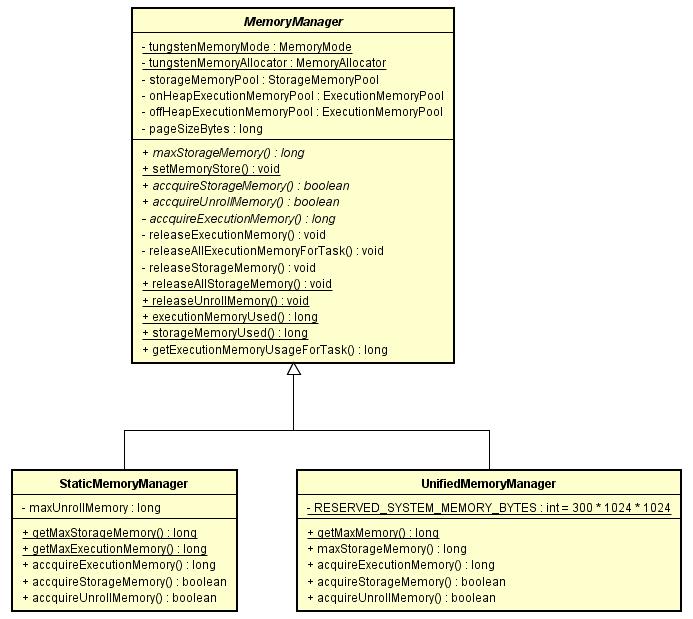
下面根据这三个类的具体实现,基本上就可以了解到这两种MemoryManager的不同之处了。
一、MemoryManager
在抽象类MemoryManager中有一些实现了的变量或者方法,
1. 变量
(1)tungstenMemoryMode
final变量,根据spark.memory.offHeap.enabled参数(默认为false)来决定是ON_HEAP还是OFF_HEAP。
final val tungstenMemoryMode: MemoryMode = {
if (conf.getBoolean("spark.memory.offHeap.enabled", false)) {
require(conf.getSizeAsBytes("spark.memory.offHeap.size", 0) > 0,
"spark.memory.offHeap.size must be > 0 when spark.memory.offHeap.enabled == true")
MemoryMode.OFF_HEAP
} else {
MemoryMode.ON_HEAP
}
} 如果设置为true,则为OFF_HEAP,但同时要求参数spark.memory.offHeap.size(默认为0),设置为大于0的值。设置为默认值false,则为ON_HEAP
(2)tungstenMemoryAllocator
final变量,根据上面变量模式来选择是使用HeapMemoryAllocator,还是使用UnsafeMemoryAllocator。ON_HEAP对应HEAP,OFF_HEAP对应Unsafe。
private[memory] final val tungstenMemoryAllocator: MemoryAllocator = {
tungstenMemoryMode match {
case MemoryMode.ON_HEAP => MemoryAllocator.HEAP
case MemoryMode.OFF_HEAP => MemoryAllocator.UNSAFE
}
}(3)storageMemoryPool
是一个StorageMemoryPool类型的变量,从名字上看是一个storage内存池。
protected val storageMemoryPool = new StorageMemoryPool(this)(4)onHeapExecutionMemoryPool和offHeapExecutionMemoryPool
这两个都是ExecutionMemoryPool类型,只是在名称上有不同的识别,一个是“on-heap execution”,一个是”off-heap execution”。对应execution内存池。
protected val onHeapExecutionMemoryPool = new ExecutionMemoryPool(this, "on-heap execution")
protected val offHeapExecutionMemoryPool = new ExecutionMemoryPool(this, "off-heap execution")(5)pageSizeBytes
大小由参数spark.buffer.pageSize决定,默认值有一个计算逻辑:default值由变量(4)的大小除以核数,再除以safetyFactor(16)得到的最接近的2的幂值,然后限定在1M和64M之间。
val pageSizeBytes: Long = {
val minPageSize = 1L * 1024 * 1024 // 1MB
val maxPageSize = 64L * minPageSize // 64MB
val cores = if (numCores > 0) numCores else Runtime.getRuntime.availableProcessors()
// Because of rounding to next power of 2, we may have safetyFactor as 8 in worst case
val safetyFactor = 16
val maxTungstenMemory: Long = tungstenMemoryMode match {
case MemoryMode.ON_HEAP => onHeapExecutionMemoryPool.poolSize
case MemoryMode.OFF_HEAP => offHeapExecutionMemoryPool.poolSize
}
val size = ByteArrayMethods.nextPowerOf2(maxTungstenMemory / cores / safetyFactor)
val default = math.min(maxPageSize, math.max(minPageSize, size))
conf.getSizeAsBytes("spark.buffer.pageSize", default)
}2. 方法
这里只列举出有实现逻辑的方法,抽象方法会在下面的类中得到具体实现。
(1)setMemoryStore(store: MemoryStore)
设置storage内存池中存储对象
(2)releaseExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode)
根据传入的taskAttemptId 以及numBytes,将对应task的execution部分内存释放出numBytes。
(3)releaseAllExecutionMemoryForTask(taskAttemptId: Long)
根据传入的taskAttemptId ,将对应的onHeap和offHeap的execution内存池内存全部释放。
(4)releaseStorageMemory(numBytes: Long)
根据传入的numBytes,将storage内存池的内存释放出numBytes。
(5)releaseAllStorageMemory()
将所有的storage内存池的内存全部释放。
(6)releaseUnrollMemory(numBytes: Long)
根据传入的numBytes,将unroll内存释放出numBytes。最后也是调用方法(4)。
(7)executionMemoryUsed
计算onHeap和offHeap的Execution内存池的总使用量。
(8)storageMemoryUsed
计算当前storage内存池的使用量
(9)getExecutionMemoryUsageForTask(taskAttemptId: Long)
根据传入的taskAttemptId,计算该task使用的onHeap和offHeap内存。
二、StaticMemoryManager
这个类就是Spark-1.6.0之前版本中主要使用的,对各部分内存静态划分好后便不可变化。
1. 变量
(1)maxUnrollMemory
由maxStorageMemory(该方法在MemoryManager中被定义)乘以spark.storage.unrollFraction(默认值0.2)来确定。
也就是说在storage内存中,有一部分会被用于unroll。由于Spark允许序列化和非序列化两种方式存储数据,对于序列化的数据,必须要先展开后才能使用。unroll部分空间就是用于展开序列化数据的。这部分空间是动态分配的
private val maxUnrollMemory: Long = {
(maxStorageMemory * conf.getDouble("spark.storage.unrollFraction", 0.2)).toLong
}2. 方法
(1)getMaxStorageMemory(conf: SparkConf)
伴生对象中的方法,用于获取storage部分内存大小,计算过程如下:
private def getMaxStorageMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
} systemMaxMemory是当前Executor的内存大小,虽然可以由参数spark.testing.memory来设定,但是这个参数一般用于做测试,在生产上不建议设置。
memoryFraction是storage内存占整个systemMaxMemory内存的比例,由参数spark.storage.memoryFraction(默认值0.6)来设定。同时为了避免出现OOM的情况,会设定一个安全系数spark.storage.safetyFraction(默认值0.9)。
(2)getMaxExecutionMemory(conf: SparkConf)
伴生对象中的方法。用于获取execution部分内存大小。计算过程如下:
private def getMaxExecutionMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
} memoryFraction即execution部分占所有能使用内存的百分比,由参数spark.shuffle.memoryFraction(默认值是0.2)来确定。
safetyFraction是execution部分的一个安全阈值,由参数spark.shuffle.safetyFraction(默认值是0.8)来确定。
总结一下,如果不引入safety的话,整个executor内存的60%用于storage,20%用于execution,剩下20%用于其他。在引入safetyFraction后,默认情况下storage占了整个executor内存的54%,execution占了16%,那么最终还剩下30%内存用于其他用途。注意在storage和execution中的safetyFraction是不一样的,execution部分的safety值更低。
内存使用情况如下图:
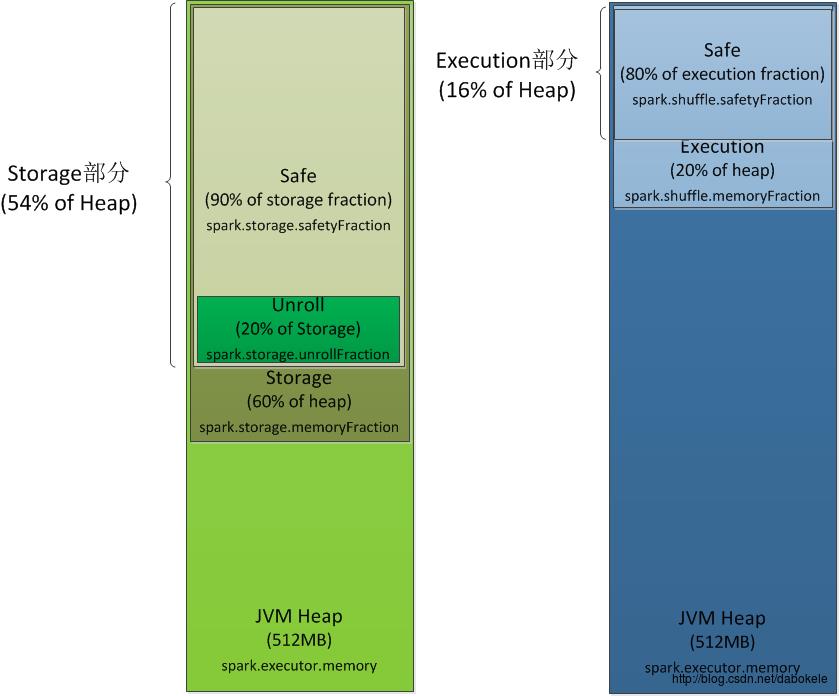
上图中的Unroll部分,并不是静态分配后不变的,它只是表示Unroll部分的内存最多占了整个storage部分的20%,当storage部分对内存需求比较大时,会使用Unroll部分的内存,当有unroll部分内存申请时,storage部分会释放一些内存以满足unroll部分的申请。unroll部分内存的上限是Storage部分的20%。
(3)acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode)
申请execution部分内存。根据传入的taskAttemptId,以及需要的内存数numBytes,和当前的MemoryMode是ON_HEAP还是OFF_HEAP,从对应的execution内存池中申请内存。这里进一步调用ExecutionMemoryPool的acquireMemory方法进行内存的申请。
ExecutionMemoryPool#acquireMemory方法在最后一部分会介绍到。
(4)acquireStorageMemory(blockId: BlockId, numBytes: Long, evictedBlocks: Buffer)
申请storage部分内存。在保证申请的内存数numBytes小于maxStorageMemory后,向storage内存池申请numBytes内存。进一步调用StorageMemoryPool的acquireMemory方法进行内存的申请。
StorageMemoryPool#acquireMemory的执行逻辑在本文最后会有描述。
(5)qcquireUnrollMemory(blockId: BlockId, numBytes: Long, evictedBlocks: Buffer)
根据传入numBytes,申请unroll部分内存。首先获取当前storage内存池中unroll部分使用的内存数currentUnrollMemory,以及当前storage内存池剩余内存数freeMemory。内存足够时,直接从storage内存池分配numBytes内存。如果内存不足,则会从storage内存池先释放出一部分内存。整个unroll部分使用的内存不能超过maxUnrollMemory。
override def acquireUnrollMemory(
blockId: BlockId,
numBytes: Long,
evictedBlocks: mutable.Buffer[(BlockId, BlockStatus)]): Boolean = synchronized {
val currentUnrollMemory = storageMemoryPool.memoryStore.currentUnrollMemory
val freeMemory = storageMemoryPool.memoryFree
// When unrolling, we will use all of the existing free memory, and, if necessary,
// some extra space freed from evicting cached blocks. We must place a cap on the
// amount of memory to be evicted by unrolling, however, otherwise unrolling one
// big block can blow away the entire cache.
val maxNumBytesToFree = math.max(0, maxUnrollMemory - currentUnrollMemory - freeMemory)
// Keep it within the range 0 <= X <= maxNumBytesToFree
val numBytesToFree = math.max(0, math.min(maxNumBytesToFree, numBytes - freeMemory))
storageMemoryPool.acquireMemory(blockId, numBytes, numBytesToFree, evictedBlocks)
}三、UnifiedMemoryManager
接下来分析Spark-1.6中引入的动态内存分配概念。
在UnifiedMemoryManager类注释中写道:
该memoryManager主要是使得execution部分和storage部分的内存不像之前由比例参数限定住,而是两者可以互相借用内存。execution和storage总的内存上限由参数`
spark.memory.fraction(默认0.75)来设定的,这个比例是相对于整个JVM heap来说的。
Storage部分可以申请Execution部分的所有空闲内存,直到Execution内存不足时向Storage发出信号为止。当Execution需要更多内存时,Storage部分会向磁盘spill数据,直到把借用的内存都还上为止。
同样的Execution部分也能向Storage部分借用内存,当Storage需要内存时,Execution中的数据不会马上spill到磁盘,因为Execution使用的内存发生在计算过程中,如果数据丢失就会到账task计算失败。Storage部分只能等待Execution部分主动释放占用的内存。
1. 变量
(1)RESERVED_SYSTEM_MEMORY_BYTES
伴生对象的一个属性,值为300MB,是Execution和Storage之外的一部分内存,为系统保留。
private val RESERVED_SYSTEM_MEMORY_BYTES = 300 * 1024 * 10242. 方法
(1)getMaxMemory(conf: SparkConf)
伴生对象的方法。获取execution和storage部分能够使用的总内存大小。计算过程如下:
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val minSystemMemory = reservedMemory * 1.5
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please use a larger heap size.")
}
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.75)
(usableMemory * memoryFraction).toLong
} systemMemory即Executor的内存大小。systemMemory要求最小为reservedMemory的1.5倍,否则直接抛出异常信息。
reservedMemory是为系统保留的内存大小,可以由参数spark.testing.reservedMemory确定,默认值为上面的300MB。如果为默认值的话,那么对应的会要求systemMemory最小为450MB。
memoryFraction是整个execution和storage共用的最大内存比例,由参数spark.memory.fraction(默认值0.75)来决定。那么还剩下0.25的内存作为User Memory部分使用。
那么对一个1GB内存的Executor来说,在默认情况下,可使用的内存大小为(1024 - 300) * 0.75 = 543MB
(2)maxStorageMemory
storage部分最大内存数。由最大内存数减去ON_HEAP的execution使用的内存大小即可得到。
override def maxStorageMemory: Long = synchronized {
maxMemory - onHeapExecutionMemoryPool.memoryUsed
}(3)acquireExecutionMemory(numBytes: Long, taskAttemptId: Long, memoryMode: MemoryMode)
为当前的taskAttemptId申请最多numBytes的内存,如果内存不足则返回0。
由于这里涉及到的都是Executor JVM Heap中的内存,所以如果是OFF_HEAP模式,直接从offHeapExecution内存池分配。对memoryMode为ON_HEAP的进行如下处理。
ExecutionMemoryPool#acquireMemory
onHeapExecutionMemoryPool.acquireMemory(numBytes, taskAttemptId, maybeGrowExecutionPool, computeMaxExecutionPoolSize)maybeGrowExecutionPool方法会去释放Storage中保存的数据所占用的内存,收缩Storage部分内存大小,从而增大Execution部分。当Execution部分剩余内存小于numBytes时,执行如下逻辑
val memoryReclaimableFromStorage = math.max(storageMemoryPool.memoryFree, storageMemoryPool.poolSize - storageRegionSize)
if (memoryReclaimableFromStorage > 0) {
// Only reclaim as much space as is necessary and available:
val spaceReclaimed = storageMemoryPool.shrinkPoolToFreeSpace(
math.min(extraMemoryNeeded, memoryReclaimableFromStorage))
onHeapExecutionMemoryPool.incrementPoolSize(spaceReclaimed)
} 如果memoryReclaimableFromStorage大于0,表示storage部分能够分配一些内存给Execution部分,这个值最多不能超过此刻storage内存池的剩余空闲内存。然后取出spaceReclaimed的内存给Execution部分,实时调整Storage和Execution内存池的大小。
在内存区域调整后,会重新计算当前Execution内存池大小computeMaxExecutionPoolSize。然后调用ExecutionMemoryPool#acquireMemory方法向Execution内存池申请内存。该方法在本文最后会有描述。
(4)acquireStorageMemory(blockId: BlockId, numBytes: Long, evictedBlocks: Buffer)
首先申请的storage内存numBytes不能超过storage部分内存的最大值maxStorageMemory。
然后当storage部分内存不足以满足此次申请时,尝试向execution内存池借用内存,借到的内存大小为min(execution内存池剩余内存,numBytes),并且实时调整execution和storage内存池的大小,如下面的代码所描述的。
if (numBytes > storageMemoryPool.memoryFree) {
// There is not enough free memory in the storage pool, so try to borrow free memory from
// the execution pool.
val memoryBorrowedFromExecution = Math.min(onHeapExecutionMemoryPool.memoryFree, numBytes)
onHeapExecutionMemoryPool.decrementPoolSize(memoryBorrowedFromExecution)
storageMemoryPool.incrementPoolSize(memoryBorrowedFromExecution)
} 最后,向storageMemoryPool申请numBytes的内存。这一部分逻辑在本文最后StorageMemoryPool#acquireMemory中会有详细描述。
(5)acquireUnrollMemory
直接调用方法(4)从storage部分申请内存。
UnifiedMemoryManager的内存分配情况如下图所示:
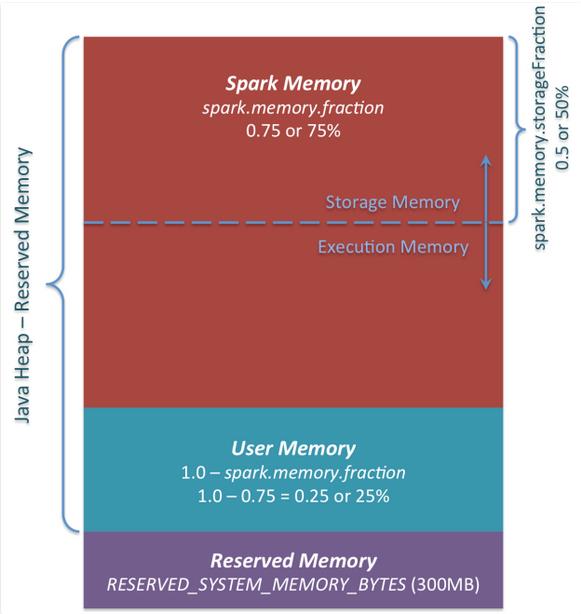
该图片参考自:https://0x0fff.com/spark-memory-management/#comment-1188
四、ExecutionMemoryPool和StorageMemoryPool
1、ExecutionMemoryPool
(1)memoryForTask变量
这个变量的定义如下,是一个HashMap结构,用于存储每个Task所使用的Execution内存情况,key为taskAttemptId, value为使用的内存数。
private val memoryForTask = new mutable.HashMap[Long, Long]()(1)acquireMemory(numBytes: Long, taskAttemptId: Long, maybeGrowPool: Long, computeMaxPoolSize: Long)方法
在该方法中主要有一个循环:
while (true) {
val numActiveTasks = memoryForTask.keys.size
val curMem = memoryForTask(taskAttemptId)
maybeGrowPool(numBytes - memoryFree)
val maxPoolSize = computeMaxPoolSize()
val maxMemoryPerTask = maxPoolSize / numActiveTasks
val minMemoryPerTask = poolSize / (2 * numActiveTasks)
val maxToGrant = math.min(numBytes, math.max(0, maxMemoryPerTask - curMem))
val toGrant = math.min(maxToGrant, memoryFree)
if (toGrant < numBytes && curMem + toGrant < minMemoryPerTask) {
logInfo(s"TID $taskAttemptId waiting for at least 1/2N of $poolName pool to be free")
lock.wait()
} else {
memoryForTask(taskAttemptId) += toGrant
return toGrant
}
} 程序一直处理该task的请求,直到系统判定无法满足该请求或者已经为该请求分配到足够的内存为止。如果当前execution内存池剩余内存不足以满足此次请求时,会向storage部分请求释放出被借走的内存以满足此次请求。
根据此刻execution内存池的总大小maxPoolSize,以及从memoryForTask中统计出的处于active状态的task的个数计算出每个task能够得到的最大内存数maxMemoryPerTask = maxPoolSize / numActiveTasks。每个task能够得到的最少内存数minMemoryPerTask = poolSize / (2 * numActiveTasks)。
根据申请内存的task当前使用的execution内存大小决定分配给该task多少内存,总的内存不能超过maxMemoryPerTask。但是如果execution内存池能够分配的最大内存小于numBytes并且如果把能够分配的内存分配给当前task,但是该task最终得到的execution内存还是小于minMemoryPerTask时,该task进入等待状态,等其他task申请内存时将其唤醒。如果满足内存分配统计,就会返回能够分配的内存数,并且更新memoryForTask,将该task使用的内存调整为分配后的值。一个Task最少需要minMemoryPerTask才能开始执行。
2、StorageMemoryPool
(1)acquireMemory(blockId: BlockId, numBytesToAcquire: Long, numBytesToFree: Long, evictedBlocks: Buffer)
numBytesToAcquire是申请内存的task传入的numBytes参数。
val numBytesToFree = math.max(0, numBytes - memoryFree)numBytesToFree表示storage空闲内存与申请内存的差值,需要storage释放numBytesToFree的内存才能满足numBytes的申请。
该方法的主要逻辑在下面这段代码中:
if (numBytesToFree > 0) {
memoryStore.evictBlocksToFreeSpace(Some(blockId), numBytesToFree, evictedBlocks)
// Register evicted blocks, if any, with the active task metrics
Option(TaskContext.get()).foreach { tc =>
val metrics = tc.taskMetrics()
val lastUpdatedBlocks = metrics.updatedBlocks.getOrElse(Seq[(BlockId, BlockStatus)]())
metrics.updatedBlocks = Some(lastUpdatedBlocks ++ evictedBlocks.toSeq)
}
} 在申请内存时,如果numBytes大于此刻storage内存池的剩余内存,则需要storage内存池释放一部分内存以满足申请需求。释放内存后如果memoryFree >= numBytes,就会把这部分内存分配给申请内存的task,并且更新storage内存池的使用情况。
释放内存部分的逻辑,调用MemoryStore#evictBlockToFreeSpace,在MemoryStore中有一个entries对象,它是一个LinkedHashMap结构,key为BlociId,value为记录了内存使用情况的一个对象。循环从最开始计算entries中每个Bokc使用的storage内存大小,取出一个就累加一下,直到累加内存大小达到前面的请求值numBytes,然后把这些BlockId对应的数据通过BlockManager充内存中直接清除,调用BlockManager#dropFromMemory把数据spill到磁盘上。
以上是关于Spark UnifiedMemoryManager和StaticMemoryManager的主要内容,如果未能解决你的问题,请参考以下文章