复习&正则&re模块
Posted iwss
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了复习&正则&re模块相关的知识,希望对你有一定的参考价值。
正则
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
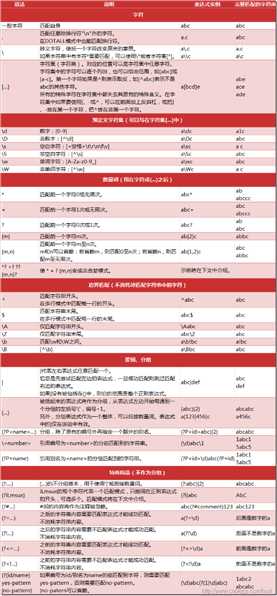
re模块
1.Re模块简介 re模块是python中处理正则表达式的一个模块,通过re模块的方法,把正则表达式pattern编译成正则对象,以便使用正则对象的方法 效率问题: import re import timeit print(timeit.timeit(setup=‘‘‘import re; reg = re.compile(‘<(?P<tagname>\\w*)>.*</(?P=tagname)>‘)‘‘‘, stmt=‘‘‘reg.match(‘<h1>xxx</h1>‘)‘‘‘, number=1000000)) print(timeit.timeit(setup=‘‘‘import re‘‘‘, stmt=‘‘‘re.match(‘<(?P<tagname>\\w*)>.*</(?P=tagname)>‘, ‘<h1>xxx</h1>‘)‘‘‘, number=1000000)) reg = re.compile(‘<(?P<tagname>\\w*)>.*</(?P=tagname)>‘) reg.match(‘<h1>xxx</h1>‘) re.match(‘<(?P<tagname>\\w*)>.*</(?P=tagname)>‘, ‘<h1>xxx</h1>‘) 常用方法:先申明一个正则对象,在通过正则对象去匹配。这样的效率高
1 re.compile(pattern[, flags]) re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同) M(MULTILINE): 多行模式,改变‘^‘和‘$‘的行为 S(DOTALL): 点任意匹配模式,改变‘.‘的行为 L(LOCALE): 使预定字符类 \\w \\W \\b \\B \\s \\S 取决于当前区域设定 U(UNICODE): 使预定字符类 \\w \\W \\b \\B \\s \\S \\d \\D 取决于unicode定义的字符属性 X(VERBOSE): 详细模式。这个模式下正则表达式可以是多行,忽略空白字符,并可以加入注释。以下两个正则表达式是等价的:
Re模块的方法: match search Match从开头开始匹配,匹配不到,返回空 Search从开头开始匹配,然后第第二个开始匹配,只匹配一个结果。 Match的效率是最高的,就要求我们正则表达式要写正确 Split split(string[, maxsplit]) 按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。 import re p = re.compile(r‘\\d+‘) print(p.split(‘one1two2three3four4‘)) 结果: [‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘] findall finditer sub
Re模块的方法: group() group(0) group(1) group(“tagname”) gourps() groupdict()
Re模块的方法: findall import re p = re.compile(r‘\\d+‘) print(findall(‘one1two2three3four4‘)) 结果: [‘1‘, ‘2‘, ‘3‘, ‘4‘] finditer sub Split \\d+ ‘one1two2three3four4’
以上是关于复习&正则&re模块的主要内容,如果未能解决你的问题,请参考以下文章