中间件——canal小记
Posted ZepheryWen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中间件——canal小记相关的知识,希望对你有一定的参考价值。
接到个小需求,将mysql的部分数据增量同步到es,但是不仅仅是使用canal而已,整体的流程是mysql>>canal>>flume>>kafka>>es,说难倒也不难,只是做起来碰到的坑实在太多,特别是中间套了那么多中间件,出了故障找起来真的特别麻烦。
先来了解一下MySQL的主从备份:
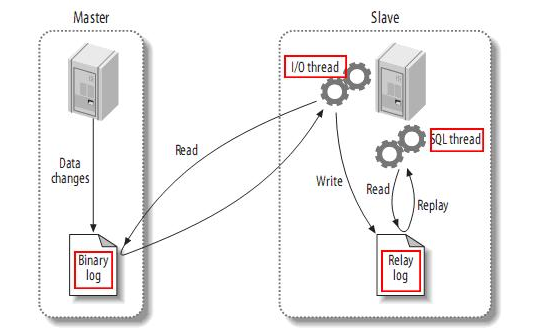
从上层来看,复制分成三步:
master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);
slave将master的binary log events拷贝到它的中继日志(relay log);
slave重做中继日志中的事件,将改变反映它自己的数据。
问题一:测试环境一切正常,但是正式环境中,这几个字段全为0,不知道为什么
最后发现是沟通问题。。。
排查过程:
- 起初,怀疑是es的问题,会不会是string转为long中出现了问题,PUT了个,无异常,这种情况排除。
- 再然后以为是代码有问题,可是想了下,rowData.getAfterColumnsList().forEach(column -> data.put(column.getName(), column.getValue()))这句不可能有什么其他的问题啊,而且测试环境中一切都是好好的。
- canal安装出错,重新查看了一次canal.properties和instance.properties,并没有发现配置错了啥,如果错了,那为什么只有那几个字段出现异常,其他的都是好好的,郁闷。而且,用测试环境的canal配置生产中的数据库,然后本地调试,结果依旧一样。可能问题出在mysql。
最后发现,居然是沟通问题。。。。测试环境中是从正式环境导入的,用的insert,可是在正式环境里,用的确实insert后update字段,之后发现居然还用delete,,,,晕。。。。之前明确问过了只更新insert的,人与人之间的信任在哪里。。。。
问题二:canal.properties中四种模式的差别
简单的说,canal维护一份增量订阅和消费关系是依靠解析位点和消费位点的,目前提供了一下四种配置,一开始我也是懵的。
#canal.instance.global.spring.xml = classpath:spring/local-instance.xml
#canal.instance.global.spring.xml = classpath:spring/memory-instance.xml
canal.instance.global.spring.xml = classpath:spring/file-instance.xml
#canal.instance.global.spring.xml = classpath:spring/default-instance.xmllocal-instance
我也不知道啥。。
memory-instance
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境。
个人建议是调试的时候使用该模式,即新增数据的时候,客户端能马上捕获到改日志,但是由于位点一直都是canal启动的时候最新的,不适用与生产环境。
file-instance
所有的组件(parser , sink , store)都选择了基于file持久化模式,注意,不支持HA机制.
特点:支持单机持久化
场景:生产环境,无HA需求,简单可用.
采用该模式的时候,如果关闭了canal,会在destination中生成一个meta.dat,用来记录关键信息。如果想要启动canal之后马上订阅最新的位点,需要把该文件删掉。
{"clientDatas":[{"clientIdentity":{"clientId":1001,"destination":"example","filter":".\.."},"cursor":{"identity":{"slaveId":-1,"sourceAddress":{"address":"192.168.6.71","port":3306}},"postion":{"included":false,"journalName":"binlog.008335","position":221691106,"serverId":88888,"timestamp":1524294834000}}}],"destination":"example"}
default-instance
所有的组件(parser , sink , store)都选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享。
特点:支持HA
场景:生产环境,集群化部署.
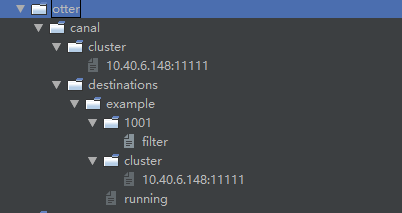
该模式会记录集群中所有运行的节点,主要用与HA主备模式,节点中的数据如下,可以关闭某一个canal服务来查看running的变化信息。
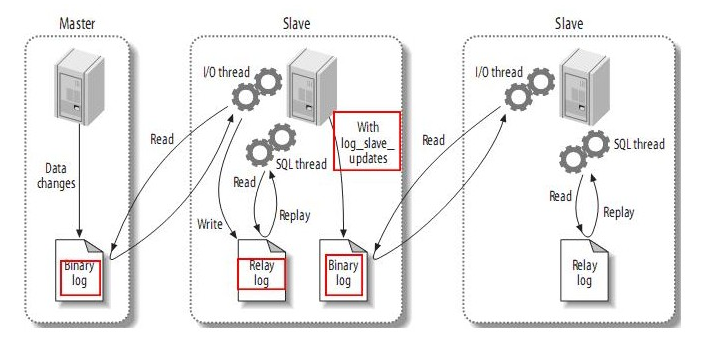
问题三:如果要订阅的是mysql的从库改怎么做?
生产环境中的主库是不能随便重启的,所以订阅的话必须订阅mysql主从的从库,而从库中是默认下只将主库的操作写进中继日志,并写到自己的二进制日志的,所以需要让其成为canal的主库,必须让其将日志也写到自己的二进制日志里面。处理方法:修改/etc/my.cnf,增加一行log_slave_updates=1,重启数据库后就可以了。
问题四:部分字段没有更新
最终版本是以mysql的id为es的主键,用canal同步到flume,再由flume到kafka,然后再由一个中间件写到es里面去,结果发现,一天之中,会有那么一段时间得出的结果少一丢丢,甚至是骤降,如图。不得不从头开始排查情况,canal到flume,加了canal的重试,以及发送到flume的重试机制,没有报错,所有数据正常发送。flume到kafka不敢怀疑,毕竟公司一直在用,怎么可能有问题。kafka到es的中间件?组长写的,而且一直在用,不可能==最后确认的是flume到kafka,kafka的parition处理速度不同,

check一下flume的文档,可以知道
| Property Name | Description |
|---|---|
| defaultPartitionId | Specifies a Kafka partition ID (integer) for all events in this channel to be sent to, unless overriden by partitionIdHeader. By default, if this property is not set, events will be distributed by the Kafka Producer’s partitioner - including by key if specified (or by a partitioner specified by kafka.partitioner.class). |
| partitionIdHeader | When set, the producer will take the value of the field named using the value of this property from the event header and send the message to the specified partition of the topic. If the value represents an invalid partition the event will not be accepted into the channel. If the header value is present then this setting overrides defaultPartitionId. |
大概意思是flume如果不自定义partitionIdHeader,那么消息将会被分布式kafka的partion处理,kafka本身的设置就是高吞吐量的消息系统,同一partion的消息是可以按照顺序发送的,但是多个partion就不确定了,如果需要将消息按照顺序发送,那么就必须要指定一个parition,即在flume的配置文件中添加:a1.channels.channel1.partitionIdHeader=1,指定parition即可。全部修改完之后,在kibana查看一下曲线:
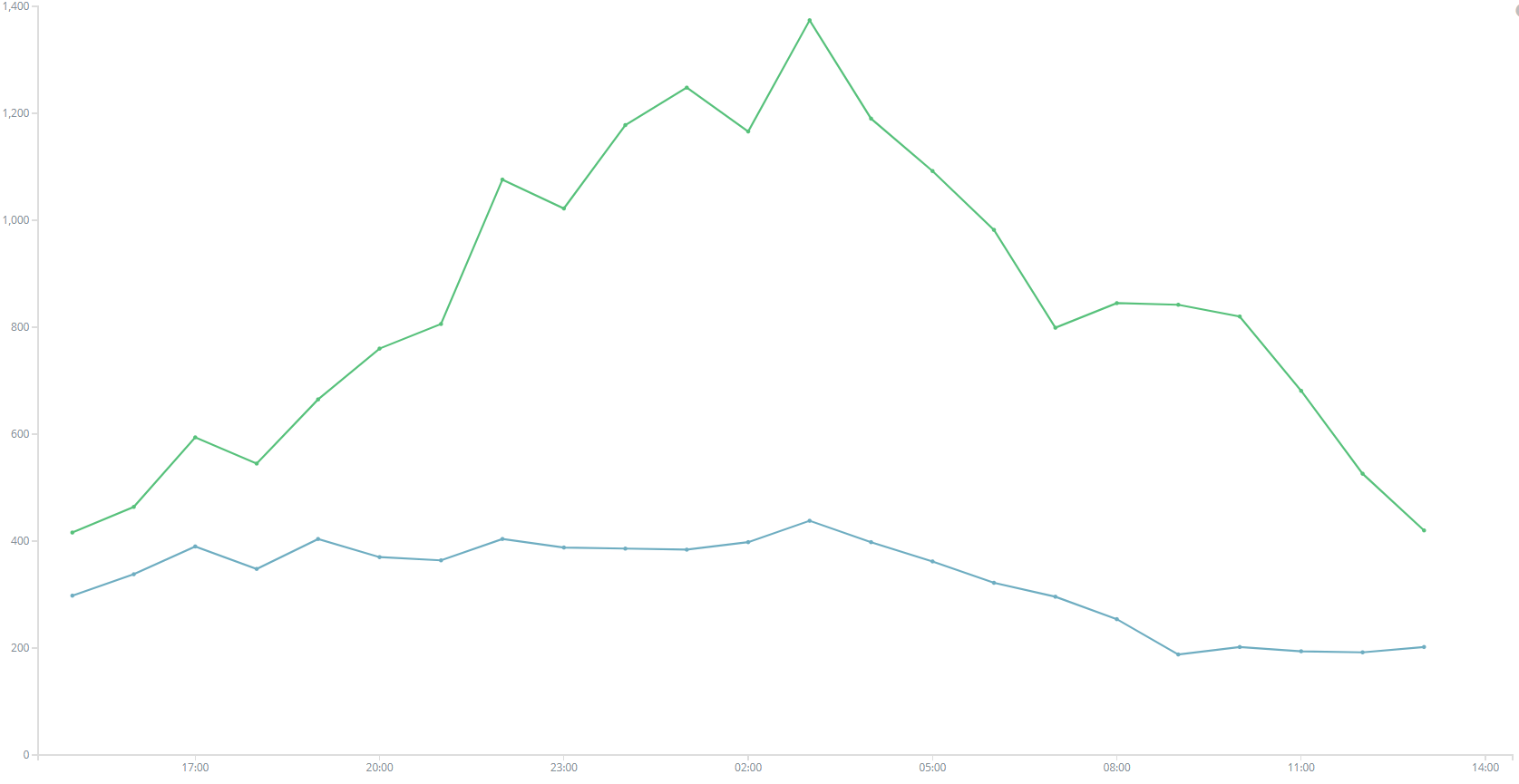
用sql在数据库确认了下,终于一致了,不容易。。。
以上是关于中间件——canal小记的主要内容,如果未能解决你的问题,请参考以下文章