网络爬虫
Posted fight139
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫相关的知识,希望对你有一定的参考价值。
1.爬虫流程图
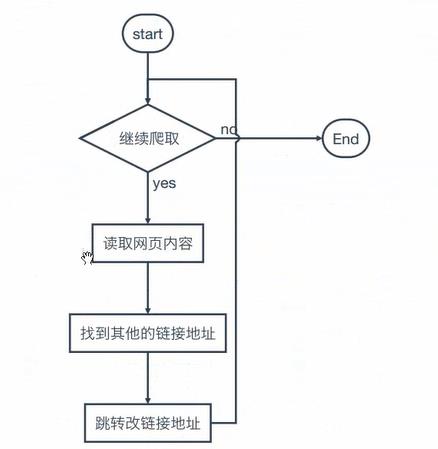
2.requests库
1.1 requests简介
Requests库是网络爬虫的一种主要手段,通过get,post,delete,put,patch和patch向目标服务器发出http请求获取数据或进行某种操作。
安装:
pip install requests
以get方法为例:
|
try:
|
列出几个重要的属性:
理解requests库的异常,网络连接有风险,异常很有可能发生。
下面为requests可能发生的异常类型:
Response的异常,通过调用r.raise_for_status()方法,如果相应状态码为200,则正常执行,否则抛出异常。
参数详解:
l url:请求地址
l **kwargs:请求控制参数,共13个
l params:能够增加到url中的参数
r = requests.get(\'http://www.baidu.com\', params = { \'key1\': \'value1\'}) ->本质是改变url地址。
r.url =\'http://www.baidu.com?key1=value1\'
- data: data={\'key1\':\'value1\'}
- json: {\'key1\':\'value1\'}
- heanders: http头 {\'user-agent\':\'chrome/10\'}
- cookies:
- auth:元组,http认证
- files:文件 file = {\'file1\':open(\'file.txt\',rb)}
- timeout:超时时间
- proxies:字典类型,设定访问代理服务器,可以增加登录认证(伪装自己的ip)
- allow_redirects: True,False,默认为True,允许重定向
- stream:True,False,默认为True,对获取的数据是否下载
- verify:True,False,默认True,热证SSL证书开关
- cert:本地SSL位置
这六种方法的底层都是使用requests.request(method, url, **kwargs)方法实现的,也就是说通过request方法,可以实现上述的六种方法:将method参数设置get,post,put等,其他的参数一样。
--python2
import urllib2 response = urllib2.urlopen("http://www.baidu.com") html = response.read() print(html)
3.中文乱码处理
requests : 设置编码
r.encoding = r.apparent_encoding
# coding:utf-8 import re # import requests import sys import codecs #python2 import urllib2 #设置编码 reload(sys) sys.setdefaultencoding(\'utf-8\') #获得系统编码格式 type = sys.getfilesystemencoding() # response = urllib2.urlopen("http://www.baidu.com") req=urllib2.Request("http://www.baidu.com") response=urllib2.urlopen(req) html = response.read().decode(\'utf-8\').encode(type) print(html)
4. 伪装请求【伪装成浏览器】User-Agent头
# coding:utf-8 import sys import urllib2 # 设置编码 reload(sys) sys.setdefaultencoding(\'utf-8\') # 获得系统编码格式 type = sys.getfilesystemencoding() url = "http://www.baidu.com" user_agent = "Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;" headers={ \'User-Agent\':user_agent } req=urllib2.Request(url,headers=headers) response = urllib2.urlopen(req) html=response.read().decode("utf-8").encode(type) print(html)
5.正则表达式
5.1 re.match(pattern, string, flag=0)
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
flag:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
匹配成功re.match方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
5.2 re.search(parttern, string, flag=0)
re.search 扫描整个字符串并返回第一个成功的匹配。
创建正则表达式对象:pattern = re.comple(\' \\d+\\.\\d+ \', re.S)
默认匹配没一行
re.S 整个文档
import re pattern = re.compile("\\d+\\.\\d+") s1="1.234 dsa frwr 4235.324 432423" rs = pattern.findall(s1) print(rs)
r"dsa\\dsf\\sd" 将转义字符当做普通字符处理
6. DOM解析【bs4】
解析实例:


<!DOCTYPE html> <html xmlns=http://www.w3.org/1999/xhtml> <head> <title>我的标题</title> <meta charset="utf-8" /> </head> <body> <p><b>hello p</b>123</p> <p id="p2">hello p ,666<span>this is a span</span></p> <div> this is div <a class="classA" href="http://www.baidu.com">百度一下</a> <a class="classB" href="http://www.google.com">谷歌</a> </div> </body> </html>
1.2 bs4简介
Beautiful Soup 是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航(navigating),搜索以及修改剖析树的操作。它可以大大节省你的编程时间。 对于Ruby,使用Rubyful Soup。
安装bs4:
pip install beautifulSoup4
BeautifulSoup默认支持Python的标准HTML解析库,但是它也支持一些第三方的解析库:
创建对象:
|
from bs4 import BeautifulSoup import requests url=\'http://www.baidu.com\' resp=requests.get(url) html=resp.read() bs=BeautifulSoup(html) #实例化对象 print bs.prettify() #格式化输出 |
对象种类:
l Tag:相当于HTML的标签。
Tag的常用属性:
name:标签名。
attrs:标签的属性。
l NavigableString:标签的string属性,指的是标签内的字符串,可以跨越多层标签。
soup = BeautifulSoup(open(\'index.html\',\'rb\'), "html.parser") # print(soup.prettify()) print(soup.title) #<title>...</title> print(soup.a) print(soup.a.name) print(soup.a.parent.name) # print(soup.a.parent.parent.parent.parent.parent.name) print(soup.a.attrs) print(soup.a.attrs[\'class\']) print(soup.a.attrs[\'href\']) print(soup.a.string) # NavigableString print(soup.p.string) # 跨越多个标签层次 print(soup.body.contents) print(soup.find(\'p\',id=\'p2\').get_text()) print(soup.find(\'p\',id=\'p2\').string) print(soup.find(\'div\').get_text()) print(len(soup.body.contents)) #body字标签 # find print(soup.findAll(\'a\'))
搜索文档树
find_all( name , attrs , recursive , text , **kwargs )
find ( name , attrs , recursive , text , **kwargs )
- Name:标签名。
- Attrs:属性约束。
- Recursive:是一个布尔参数(默认为True),用于指定Beautiful Soup遍历整个剖析树, 还是只查找当前的子标签或者剖析对象
- Text:是一个用于搜索NavigableString对象的参数。 它的值可以是字符串,一个正则表达式, 一个list或dictionary,True或None。
BeautifulSoup之CSS选择器
BeautifulSoup支持大部分的CSS选择器,其语法为:向tag或soup对象的.select()方法中传入字符串参数,选择的结果以列表形式返回。
Tag.get_text():获取标签的所有字符串,包括字标签内的字符串。
以上是关于网络爬虫的主要内容,如果未能解决你的问题,请参考以下文章