JVM学习--数字存储,内存模型,指令重排
Posted NoYone
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JVM学习--数字存储,内存模型,指令重排相关的知识,希望对你有一定的参考价值。
一、数字在计算机中的存储
整数:以补码形式存储。
补码:正数的补码是自身,负数的补码是取反码加1(取反码时符号位还是1)
浮点型:以float类型表示

注意一下,这八位指数实际上是(127+次数)的结果,因为要考虑到负数指数的情况,例如如下118.5在计算机中的存储:
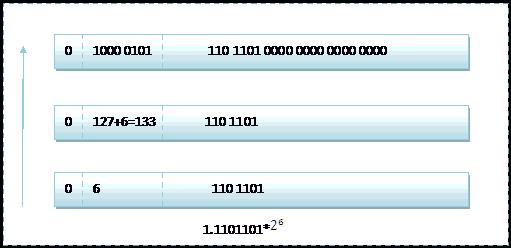
而因为科学计数法第一位总是1开头,可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了24bit。那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点,24bit就能使float能精确到小数点后6位。那从这里可以看到,如果小数位数过多,是不能被精确存储的,还有另一种情况不能被精确存储,例如小数0.2,在取二进制的过程中,“乘2取整,顺序排列”,那最终也乘不到一个整数,所以也是不能被精确存储的。
二、JVM基础结构--内存模型
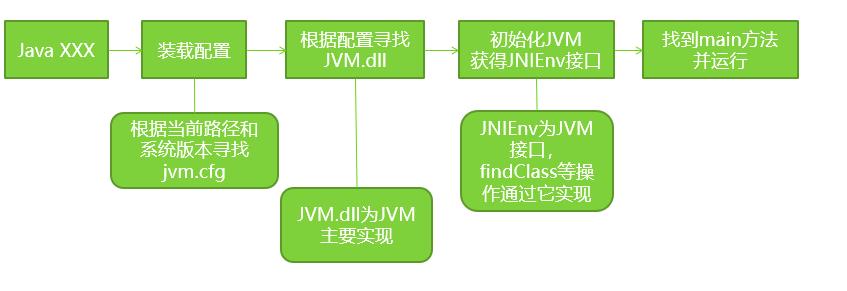
1. JVM启动流程
2. JVM具体的模型--堆栈方法区(Metaspace)等
请看这篇博客:https://blog.csdn.net/bruce128/article/details/79357870 写的非常棒,我这里只做这篇博客的补充。
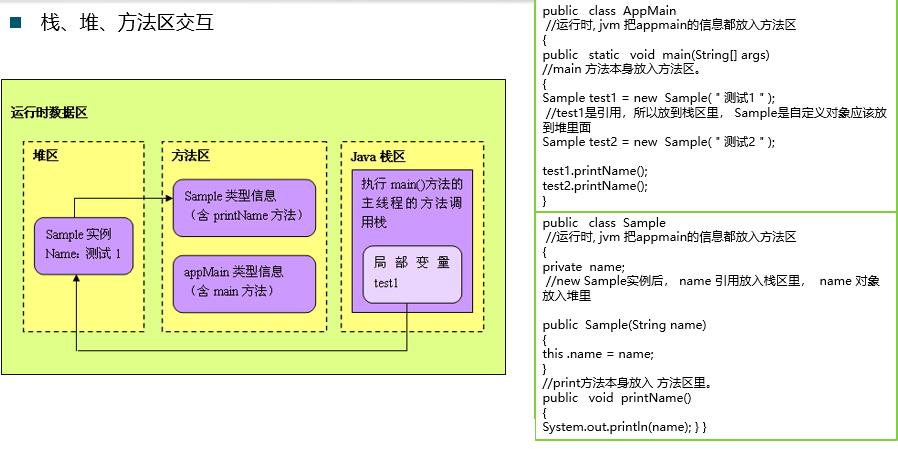
① 栈、堆、方法区的交互(jdk1.8是Metaspace,字符串常量池从jdk1.7开始就从永久区移除到对空间上了)
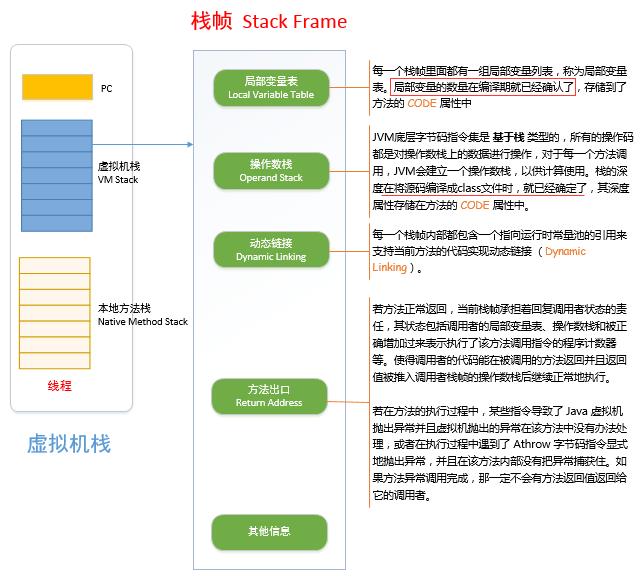
② 栈上分配
栈上分配是Java虚拟机提供的一项优化技术,它的基本思想是,对于那些线程私有的对象(这里指不可能被其他线程访问的对象),可以将它们打散分配在栈上,而不是分配在堆上。分配在栈上的好处是可以在函数调用结束后自行销毁,而不需要垃圾回收器的介入,从而提高了系统的性能。
栈上分配的基础是进行逃逸分析。逃逸分析的目的是判断对象的作用域是否有可能逃逸出函数体。
可逃逸对象:对象u分配在方法区内,该字段可能被任何线程访问,因此属于逃逸对象。
private static User u; public static void alloc(){ u = new User(); u.id = 5; u.name = "xxx"; }
非逃逸对象:局部变量,对象u的引用在栈上,并且该对象并没有被alloc()函数返回,或者任何形式的公开,因此,它并未发生逃逸,所以对于这种情况,虚拟机就有可能把对象u分配在栈上,而不是在堆上。
public static void alloc(){ User u = new User(); u.id = 5; u.name = "xxx"; }
/** * 非逃逸对象可能分配到栈上的测试 * 运行参数: * -server -Xmx10m -Xms10m -XX:+DoEscapeAnalysis * -XX:+PrintGCDetails -XX:-UseTLAB -XX:+EliminateAllocations */ public class UnEscapeTest { public static class User{ public int id = 0; public String name = ""; } public static void alloc(){ User u = new User(); u.id = 5; u.name = "xxx"; } public static void main(String[] args) { long begin = System.currentTimeMillis(); for (int i = 0; i < 100000000; i++) { alloc(); } long end = System.currentTimeMillis(); System.out.println(end - begin); } }
上面的测试结果:
[GC (Allocation Failure) [PSYoungGen: 2048K->488K(2560K)] 2048K->720K(9728K), 0.0008276 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[GC (Allocation Failure) [PSYoungGen: 2536K->488K(2560K)] 2768K->720K(9728K), 0.0019476 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
8
结果只进行了两次Minor GC,若是关闭逃逸分析(-XX:-DoEscapeAnalysis)或者关闭标量替换(-XX:-EliminateAllocations)(默认打开),将会有大量GC产生,说明栈上分配依赖逃逸分析和标量替换的实现。
结论:对于大量的零散小对象,栈上分配提供了一种很好的对象分配优化策略,栈上分配速度快,并且可以有效避免垃圾回收带来的负面影响,但由于和堆空间比较,栈空间较小,因此对于大对象也不适合在栈上分配。
3. 线程调用公共变量时
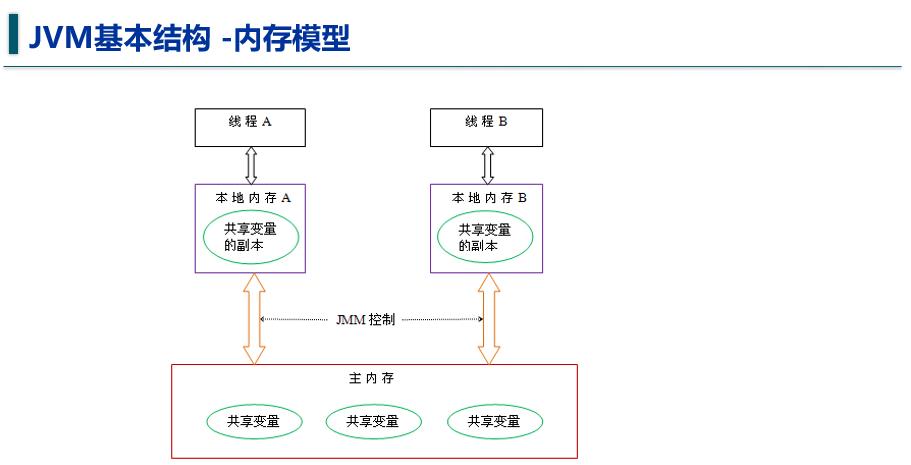
这里只看这张图能反应出的东西:
① 每一个线程都有一个独立工作内存(寄存器)
② 工作内存中存放的是主存中变量的值的拷贝
那我们可以发现,当一个线程修改了一个共享变量并写回主存时,另一个持有此共享变量的线程并不会立刻得知此变化,因为这个线程操作的是自己工作内存里的变量,这就是可见性问题(volatile,synchronized,final)。
之前写的博客:http://www.cnblogs.com/NoYone/p/8541898.html
三、指令重排
指令重排能帮助程序更快速的运行,这是jvm做的优化,但有些时候程序必须顺序执行,指令重排符合以下规则。

以上是关于JVM学习--数字存储,内存模型,指令重排的主要内容,如果未能解决你的问题,请参考以下文章