异步调用与回调机制,协程
Posted dominic-ji
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了异步调用与回调机制,协程相关的知识,希望对你有一定的参考价值。
1.异步调用与回调机制
上一篇我们已经了解到了两组比较容易混淆的概念问题,1.同步与异步调用 2.阻塞与非阻塞状态。在说到异步调用的时候,说到提交任务后,就直接执行下一行代码,而不去拿结果,这样明显存在缺陷,结果是肯定要拿的,这辈子都肯定是要拿到这个结果的,没有这个结果后面的活又不会干,没办法,只能去拿结果的,那么问题是异步调用提交任务后,如何实现既要拿到结果又不需要原地等的理想状态呢?专门为异步调用配备了一个方法——回调机制
先来想想我们之前是怎么拿到一个函数的结果,就传给另外一个函数取执行,直接用一个变量接收第一个函数的返回值,然后将其传入第二个函数中,这种方式并不能达到异步调用的条件,第二种方式是在一个函数体内的结果产生之后,直接调用另外一个函数,这样的话就能实现异步调用的特征,但是这样的方式会将两个独立的函数耦合到了一起,没有实现程序与程序之间的解耦和概念,第三种方式就是借助于回调机制,它能够在一个函数产生运行结果的瞬间,就将该函数的结果作为参数传给其他函数取执行,有一种实时监控实时响应的感觉,相当于在一个函数体内植入了一段隐藏功能,这个功能在特点条件下自动触发~~~


from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import requests import os import time import random def get(url): print(‘%s GET %s‘ %(os.getpid(),url)) response=requests.get(url) time.sleep(random.randint(1,3)) if response.status_code == 200: pasrse(response.text) #此方法不好的地方在于没有实现两个函数之间的解耦和 def pasrse(res): print(‘%s 解析结果为:%s‘ %(os.getpid(),len(res))) if __name__ == ‘__main__‘: urls=[ ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.python.org‘, ] pool=ProcessPoolExecutor(4) for url in urls: pool.submit(get,url)
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import requests import os import time import random def get(url): print(‘%s GET %s‘ %(os.getpid(),url)) response=requests.get(url) time.sleep(random.randint(1,3)) if response.status_code == 200: # 干解析的活 return response.text def pasrse(obj): res=obj.result() print(‘%s 解析结果为:%s‘ %(os.getpid(),len(res))) if __name__ == ‘__main__‘: urls=[ ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.baidu.com‘, ‘https://www.python.org‘, ] pool=ProcessPoolExecutor(4) for url in urls: obj=pool.submit(get,url) obj.add_done_callback(pasrse) #回调函数,在创建的进程中绑上一个方法,使得绑定的进程一旦运行完毕产生结果就立马拿到返回的结果去给另外一个函数执行 #之所以叫回调是因为进程的创建是由主进程申请的,等子进程里产生结果后,会再次返回给主进程,由主进程来负责执行数据分析的活! #如果是线程的话,则是哪个线程空闲就由哪个线程去干,(线程没有主次) # 问题: # 1、任务的返回值不能得到及时的处理,必须等到所有任务都运行完毕才能统一进行处理 # 2、解析的过程是串行执行的,如果解析一次需要花费2s,解析9次则需要花费18s print(‘主进程‘,os.getpid())
2.协程
本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态
也就是说只要是能做到多个任务只要有一个遇到I/O我们就能控制程序立马跳转到其他任务去执行,实现一遇到I/O就保存状态并切换执行,那么就满足了并发的条件,而一个线程里面是有多个任务的,也就是说一个线程里面只要能达到上述要求也就能实现——一个线程下实现多并发的效果!
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长或有一个优先级更高的程序替代了它
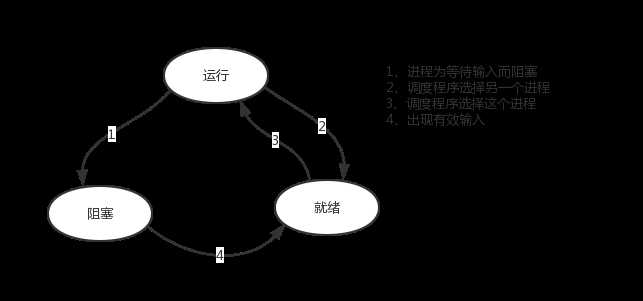
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。
二:第一种情况的切换。在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少,从而更多的将cpu的执行权限分配给我们的线程。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。 2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
二 协程介绍
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。
需要强调的是:
1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) 2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制)
Gevent介绍
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
#用法 g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
遇到IO阻塞时会自动切换任务
import gevent def eat(name): print(‘%s eat 1‘ %name) gevent.sleep(2) print(‘%s eat 2‘ %name) def play(name): print(‘%s play 1‘ %name) gevent.sleep(1) print(‘%s play 2‘ %name) g1=gevent.spawn(eat,‘egon‘) g2=gevent.spawn(play,name=‘egon‘) g1.join() g2.join() #或者gevent.joinall([g1,g2]) print(‘主‘)
上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,
而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
from gevent import monkey;monkey.patch_all() import gevent import time def eat(): print(‘eat food 1‘) time.sleep(2) print(‘eat food 2‘) def play(): print(‘play 1‘) time.sleep(1) print(‘play 2‘) g1=gevent.spawn(eat) g2=gevent.spawn(play_phone) gevent.joinall([g1,g2]) print(‘主‘)
我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程
from gevent import spawn,joinall,monkey;monkey.patch_all() import time def task(pid): """ Some non-deterministic task """ time.sleep(0.5) print(‘Task %s done‘ % pid) def synchronous(): for i in range(10): task(i) def asynchronous(): g_l=[spawn(task,i) for i in range(10)] joinall(g_l) if __name__ == ‘__main__‘: print(‘Synchronous:‘) synchronous() print(‘Asynchronous:‘) asynchronous() #上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
Gevent之应用举例一
from gevent import monkey;monkey.patch_all() import gevent import requests import time def get_page(url): print(‘GET: %s‘ %url) response=requests.get(url) if response.status_code == 200: print(‘%d bytes received from %s‘ %(len(response.text),url)) start_time=time.time() gevent.joinall([ gevent.spawn(get_page,‘https://www.python.org/‘), gevent.spawn(get_page,‘https://www.yahoo.com/‘), gevent.spawn(get_page,‘https://github.com/‘), ]) stop_time=time.time() print(‘run time is %s‘ %(stop_time-start_time))
Gevent之应用举例二
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
from gevent import monkey;monkey.patch_all() from socket import * import gevent #如果不想用money.patch_all()打补丁,可以用gevent自带的socket # from gevent import socket # s=socket.socket() def server(server_ip,port): s=socket(AF_INET,SOCK_STREAM) s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) s.bind((server_ip,port)) s.listen(5) while True: conn,addr=s.accept() gevent.spawn(talk,conn,addr) def talk(conn,addr): try: while True: res=conn.recv(1024) print(‘client %s:%s msg: %s‘ %(addr[0],addr[1],res)) conn.send(res.upper()) except Exception as e: print(e) finally: conn.close() if __name__ == ‘__main__‘: server(‘127.0.0.1‘,8080) 服务端
#_*_coding:utf-8_*_ __author__ = ‘Linhaifeng‘ from socket import * client=socket(AF_INET,SOCK_STREAM) client.connect((‘127.0.0.1‘,8080)) while True: msg=input(‘>>: ‘).strip() if not msg:continue client.send(msg.encode(‘utf-8‘)) msg=client.recv(1024) print(msg.decode(‘utf-8‘))
from threading import Thread from socket import * import threading def client(server_ip,port): c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了 c.connect((server_ip,port)) count=0 while True: c.send((‘%s say hello %s‘ %(threading.current_thread().getName(),count)).encode(‘utf-8‘)) msg=c.recv(1024) print(msg.decode(‘utf-8‘)) count+=1 if __name__ == ‘__main__‘: for i in range(500): t=Thread(target=client,args=(‘127.0.0.1‘,8080)) t.start()
EVENT事件
同进程的一样
线程的一个关键特性是每个线程都是独立运行且状态不可预测。如果程序中的其 他线程需要通过判断某个线程的状态来确定自己下一步的操作,这时线程同步问题就会变得非常棘手。为了解决这些问题,我们需要使用threading库中的Event对象。 对象包含一个可由线程设置的信号标志,它允许线程等待某些事件的发生。在 初始情况下,Event对象中的信号标志被设置为假。如果有线程等待一个Event对象, 而这个Event对象的标志为假,那么这个线程将会被一直阻塞直至该标志为真。一个线程如果将一个Event对象的信号标志设置为真,它将唤醒所有等待这个Event对象的线程。如果一个线程等待一个已经被设置为真的Event对象,那么它将忽略这个事件, 继续执行
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度; event.clear():恢复event的状态值为False。
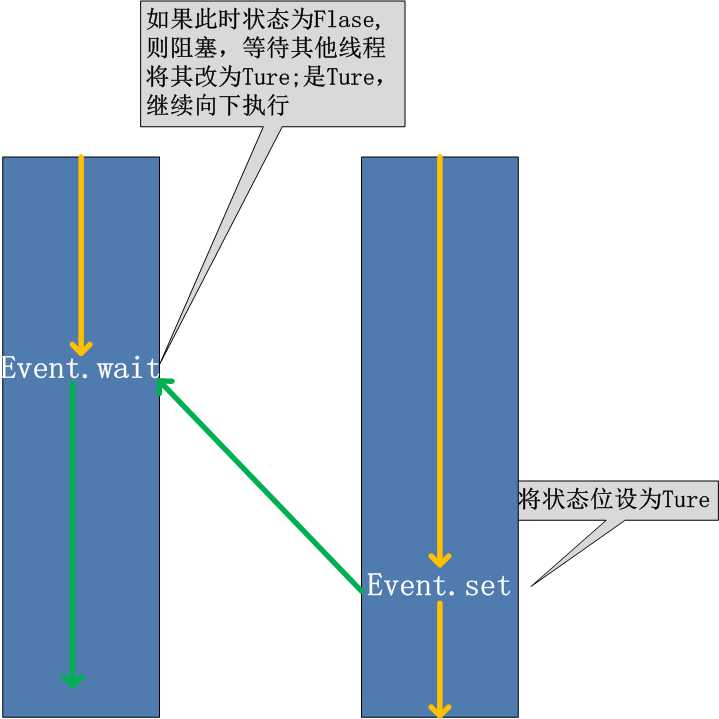
例如,有多个工作线程尝试链接mysql,我们想要在链接前确保MySQL服务正常才让那些工作线程去连接MySQL服务器,如果连接不成功,都会去尝试重新连接。那么我们就可以采用threading.Event机制来协调各个工作线程的连接操作
from threading import Thread,Event import threading import time,random def conn_mysql(): count=1 while not event.is_set(): if count > 3: raise TimeoutError(‘链接超时‘) print(‘<%s>第%s次尝试链接‘ % (threading.current_thread().getName(), count)) event.wait(0.5) count+=1 print(‘<%s>链接成功‘ %threading.current_thread().getName()) def check_mysql(): print(‘\\033[45m[%s]正在检查mysql\\033[0m‘ % threading.current_thread().getName()) time.sleep(random.randint(2,4)) event.set() if __name__ == ‘__main__‘: event=Event() conn1=Thread(target=conn_mysql) conn2=Thread(target=conn_mysql) check=Thread(target=check_mysql) conn1.start() conn2.start() check.start()
以上是关于异步调用与回调机制,协程的主要内容,如果未能解决你的问题,请参考以下文章