GIL全局解释器锁和进程池.线程池
Posted 木夂各
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GIL全局解释器锁和进程池.线程池相关的知识,希望对你有一定的参考价值。
GIL全局解释器锁
GIL本质就是一把互斥锁,是夹在解释器身上的,同一个进程内的所有线程都需要先抢到GIl锁,才能执行解释器代码
GIL的优缺点:
优点:保证Cpython解释器内存管理的线程安全
缺点:同一个进程内所有的线程同一时刻只能有一个执行,也就是说Cpython解释器的多线程无法实现并行,无法取得多核优势
GIL与单线程
每个进程的内存空间中都有一份python解释器的代码,所以在单线程的情况下,GIL锁没有线程争抢,只有垃圾回收机制线程会定时获取GIL权限
GIL与多线程
有了GIL存在,每个进程内同一时间只能有一个线程执行。
由于CPU只能提升运算能力,所以:
在处理IO密集型的任务时,应该使用 多线程
在处理计算密集型的任务时,应该使用 多进程
GIL的原理图示
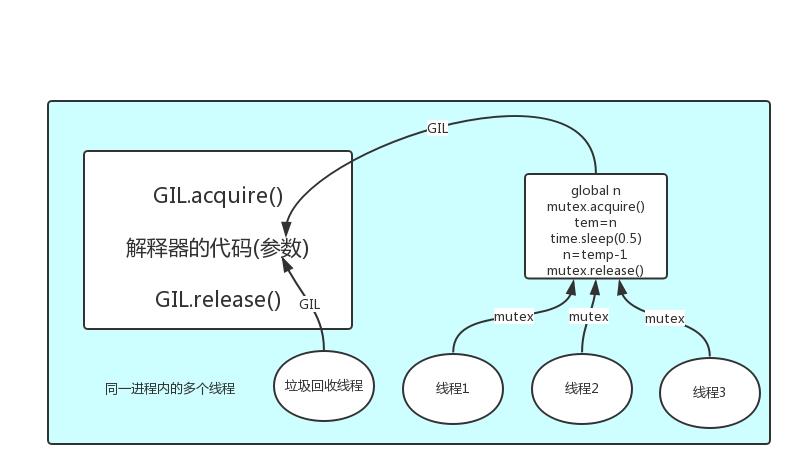
解释:py程序的执行,每次都是先启动python解释器,开辟的内存空间中首先就会有Python解释器的代码,其他py程序的代码,都是要交给解释器的代码去解释执行的,那么在多线程的情况下,为了解释器级别的数据安全,每个线程必须在拿到GIL锁的权限后,才能执行,GIL锁实际上就实现了Python的线程安全。(需要注意的是,Python的垃圾回收机制也是一个线程,默认开启。)
GIL与互斥锁
GIL只能实现解释器级别的数据安全,对于线程内部的用户自己的数据,还是需要枷锁处理
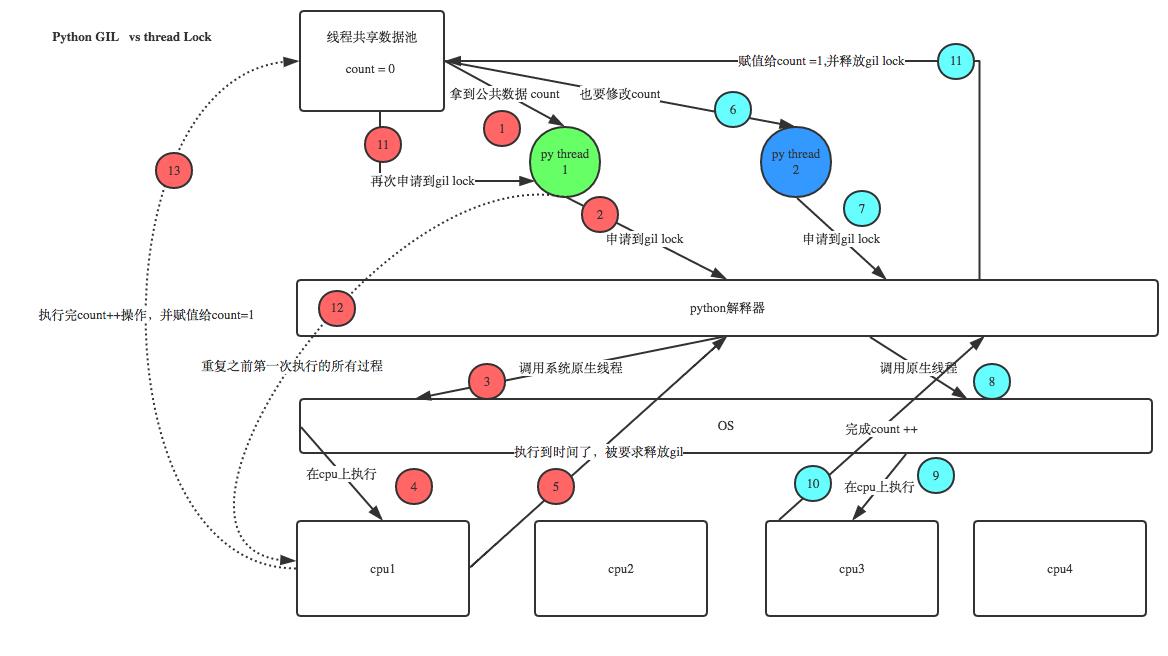


分析: #1.100个线程去抢GIL锁,即抢执行权限 #2. 肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire() #3. 极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL #4.直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
#不加锁:并发执行,速度快,数据不安全 from threading import current_thread,Thread,Lock import os,time def task(): global n print(\'%s is running\' %current_thread().getName()) temp=n time.sleep(0.5) n=temp-1 if __name__ == \'__main__\': n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print(\'主:%s n:%s\' %(stop_time-start_time,n)) \'\'\' Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:0.5216062068939209 n:99 \'\'\' #不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全 from threading import current_thread,Thread,Lock import os,time def task(): #未加锁的代码并发运行 time.sleep(3) print(\'%s start to run\' %current_thread().getName()) global n #加锁的代码串行运行 lock.acquire() temp=n time.sleep(0.5) n=temp-1 lock.release() if __name__ == \'__main__\': n=100 lock=Lock() threads=[] start_time=time.time() for i in range(100): t=Thread(target=task) threads.append(t) t.start() for t in threads: t.join() stop_time=time.time() print(\'主:%s n:%s\' %(stop_time-start_time,n)) \'\'\' Thread-1 is running Thread-2 is running ...... Thread-100 is running 主:53.294203758239746 n:0 \'\'\' #有的同学可能有疑问:既然加锁会让运行变成串行,那么我在start之后立即使用join,就不用加锁了啊,也是串行的效果啊 #没错:在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是 #start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的 #单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高. from threading import current_thread,Thread,Lock import os,time def task(): time.sleep(3) print(\'%s start to run\' %current_thread().getName()) global n temp=n time.sleep(0.5) n=temp-1 if __name__ == \'__main__\': n=100 lock=Lock() start_time=time.time() for i in range(100): t=Thread(target=task) t.start() t.join() stop_time=time.time() print(\'主:%s n:%s\' %(stop_time-start_time,n)) \'\'\' Thread-1 start to run Thread-2 start to run ...... Thread-100 start to run 主:350.6937336921692 n:0 #耗时是多么的恐怖 \'\'\'
进程池和线程池
为什么要用‘池’:
使用池子来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务
什么时候使用进程池:并发的任务属于计算密集型
什么时候使用线程池:并发的任务属于IO密集型
语法
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
进程池实例
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print(\'%s 接客\' %os.getpid()) time.sleep(random.randint(2,5)) return x**2 if __name__ == \'__main__\': p=ProcessPoolExecutor() # 默认开启的进程数是cpu的核数 for i in range(20): p.submit(task,i)
线程池实例
from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor import time,os,random def task(x): print(\'%s 接客\' %x) time.sleep(random.randint(2,5)) return x**2 if __name__ == \'__main__\': p=ThreadPoolExecutor(4) # 默认开启的线程数是cpu的核数*5 # alex,武佩奇,杨里,吴晨芋,张三 for i in range(20): p.submit(task,i)
阻塞与非阻塞(指的是程序的两种运行状态)
阻塞:遇到IO就发生阻塞,程序一旦遇到阻塞操作就会停在原地,并且立刻释放CPU资源
非阻塞(就绪态或者运行态):没有遇到IO操作,或者通过某种手段让程序即便是遇到IO操作也不会停在原地,可以继续执行其他操作,力求尽可能多的占有CPU
同步与异步指的是提交任务的两种方式
同步调用:提交完任务后,就在原地等待,直到任务运行完毕后,拿到任务的返回值,才继续执行下一行代码、
异步调用:提交完任务后,不在原地等待,直接执行下一行代码,在最后可以代码每次任务的返回值
以上是关于GIL全局解释器锁和进程池.线程池的主要内容,如果未能解决你的问题,请参考以下文章