mapreduce
Posted 草莓干123456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce相关的知识,希望对你有一定的参考价值。
MapReduce:
概念:MapReduce主要是分布式编程的一个编程模型
优势:
1、允许我们处理输入输出的限制
2、他是个无共享架构,每个节点可以并行处理该节点上的数据, 无需包含其他节点的运行情况
3、他能高效处理可能因为硬件问题造成的各种执行故障
4、数据局部性,就是说代码找到数据所在节点,并在该节点对数 据进行处理
5、他是从开发人员那里提炼分布是分层的一种办法。在编写程序时,不需要编写多线程程序。mapreduce确保代码能够获得不同节点上的数据,同时并行无间断的处理数据
mapreduce流的六个阶段:
1、input:mapper读取数据块
2、split:mapper从基于记录的数据块中将每条记录传递给map函数(对记录的识别非常重要)
3、mapping:mapper的业务逻辑会构成一张图
4、shuffling:把多个节点上的具有相同key的mapper输出数据被聚合起来,重新排序,传送给一个单独的reducer
5、reduceing:做最后的聚合工作,并将数据存储回HDFS
6、final result:
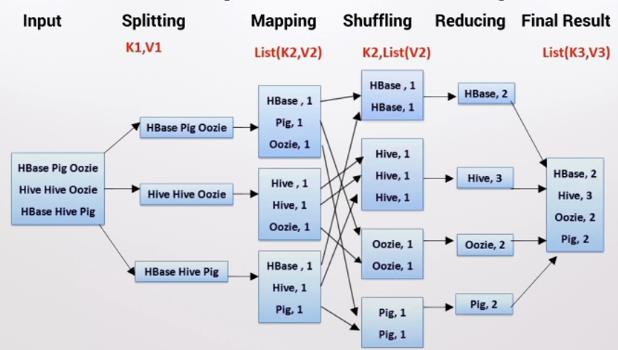
例如
1、输入数据块
hbase pig oozie
hive hive oozie
hbase hive pig
2、执行split操作,生成key-value键:
k1=0,v1=hbase pig oozie
k2=16,v2=hive hive oozie
k3=32,v3=hbase hive pig
3、key-value建传输给mapper,生成list(k,v)
【注意:mapper的执行结果写回执行处理程序的本地节点上,而不是写到HDFS上】
4、根据key值,数据聚合,表达形式k,list(v)
5、对结果继续执行聚集,聚集结果写进RDFS。
以上是关于mapreduce的主要内容,如果未能解决你的问题,请参考以下文章