Sql Server 内存相关计数器以及内存压力诊断
Posted 专注,勤学,慎思。戒骄戒躁,谦虚谨慎
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Sql Server 内存相关计数器以及内存压力诊断相关的知识,希望对你有一定的参考价值。
在数据库服务器中,内存是数据库对外提供服务最重要的资源之一,
不仅仅是Sql Server,包括其他数据库,比如Oracle,mysql等,都是一类非常喜欢内存的应用.
在Sql Server服务器中,最理想的情况是Sql Server把所有所需的数据全部缓存到内存中,但是这往往也是不现实的,因为数据往往总是大于可用的物理内存
可以说内存是否存在压力能够直接决定数据库能否高效运行,
同时,如果内存出现压力,同时也会影响到CPU的使用和存储性能,可以说是一损俱损,具有连带性。
那么,如何识别内存是否存在压力,如何判断一台服务器上是否存在内存瓶颈?
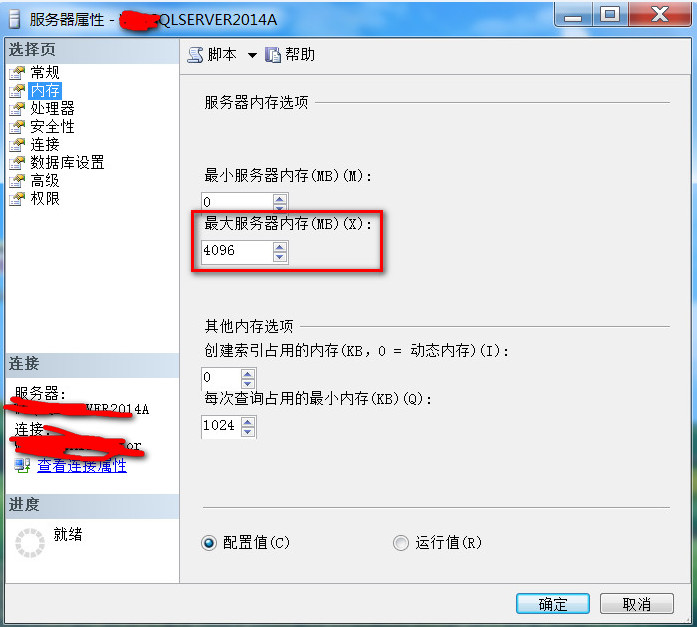
Sql Server 2012之后,对内存的管理进行了大刀阔斧的改革,所有的内存管理都受Max Server Memory的控制
如下截图所示的最大服务器内存设置(当然这个截图是我本机上一个测试实例,这里并不说明内存该怎么配置)
而大多数的内存量化都涉及到Sql Server的Buffer Pool,一个内部的缓存管理器,
/*
20160525补充:
Sql Server 2012之前的版本,
对于Buffer Pool是存储Data Cache的,
另外一部分专用的内存称之为Memory To Leave(Sql Server 2012之后,叫做Stolen Memory),
这部分内存的使用也是一个非常大的话题,这里暂不展开论述。
32位操作系统下,这部分内存是Sql Server 启动后直接初始化分配的,64位操作系统是直接跟操作系统申请,
如果需要的Stolen Memory过大,同样会“挤压”Buffer Pool的内存
*/
但是,Sql Server2012之后,所有内存的管理都受到Max Server Memory的控制。
同时,Sql Server在运行的过程中,会将各种内存的参数情况记录下来,这对我们去判断Sql Server内存压力有着非常重要的参考意义
下面提到的部分计数器的就存储在sys.dm_os_performance_counters这个系统视图中

我们抽取其中最重要的几个来做解释说明:
- Page Life Expectancy
- Buffer Cache hit ratio
- Page reads / sec
- Page writes / sec
- Lazy writes / sec
- Total Server Memory
- Target Server Memory
- Paging File % Usage
需要注意的是,不能通过上述某一个值就武断地断定内存瓶颈,各个计数器之间是有一定的关系的,要结合多个值来做谨慎的分析判断。
- Page Life Expectancy
Page Life Expectancy又简称位PLE,含义是内存页面在内存中停留的平均时间,是内存压力判断的一个重要参考值
在系统视图sys.dm_os_performance_counters中可以查到,单位是秒.
需要注意的是它不是指某一个page的最大值或者最小值,而是所有由所有页面停留在buffer pool中的时间计算出来的一个平均值
如果这个值越大,说明Sql Server在检索数据时候直接从buffer pool中获取数据的概率越大,
如果Sql Server直接从buffer pool中检索到数据,那么就不用去磁盘中去查询,因为直接从内存中获取数据的效率要远远高出从磁盘中去获取数据
因为从内存中查询数据的延迟是纳秒级的,而从磁盘获取数据的延迟是毫秒级的,这之间差了两个数量级,
可见从缓存中获取数据和从磁盘中获取数据,对性能的影响有多大
那么PLE这个值多少位正常呢?我发现很多资料上多这个值都有误解,说是300S,300S是在十多年前的一个参考值,
是基于当时的服务器内存受到4GB内存的限制的影响得到的,
目前服务器内存动辄超过100GB的情况下,用同样的标准,显然是不够准确的,这个值的计算是跟具体的服务器内存配置有关的
具体我就不做进一步的解释,可以参考如下链接
https://simplesqlserver.com/2013/08/19/fixing-page-life-expectancy-ple/
一个可供参考的标准算法是 Max Buffer Pool(GB)/4*300(S)
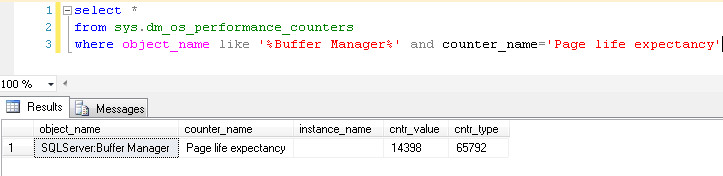
这个值可以通过sys.dm_os_performance_counters 这个系统视图直接查询得出
select * from sys.dm_os_performance_counters where object_name like \'%Buffer Manager%\' and counter_name=\'Page life expectancy\'
比如你的服务内存是64G,分配给Sql Server最大内存(上述Max Server Memory)是60G
那么PLE的参考值就是60/4*300=4500S,大概是75分钟,也就是说,最低限度是每75分钟,内存中的数据跟磁盘做一次完整的交换
如果你的服务器上的PLE值长期低于计算出来的这个参考值,或者这个值在某个时间段内有非常明显的变化,那么你就需要注意内存是否存在瓶颈了
如果你真的做过这方面观察的话,这个值在不同环境中差别是非常大的
当然对于测试服务器,经常没几个人用,或者压力非常小的服务器,内存没压力或者服务器根本没有负载的情况下,缓存进去的数据可能就一直存在于内存中
这个值有可能非常大,达到几万秒都是有可能的
不信我给你截个图,呵呵
当然对于压力比较大的生产服务器,即便是有几十个GB的内存,这个值,也有可能小到几十秒钟,我所在的公司就是这个情况。
所以,PLE的值是作为判断内存是否存在瓶颈的最重要的指标之一。
- Buffer Cache hit ratio
Buffer Cache hit ratio就是缓存命中率,字面上的解释就是一个查询过程中所需要的时候,直接从内存中读取出来的比例占所有数据的百分比
鉴于表现出来的值受到其算法的制约,反倒是在内存压力诊断的时候并不具备太多的参考意义,
既然Buffer Cache hit ratio不具备太多的参考意思,那么为什么把他放在这里呢?
因为这一个非常流行的参数,很多材料上都提到过这个参数
很多材料上都介绍其阈值是90%,95%之类的参考值,其实都是错误的,
其实真正观察过的人,如下链接,早就有人有此疑问了,从PLE和Buffer hit ratio得出根本不一致的结论,
有时候我们做学问还是要讲究严禁的,不能人云亦云
怎样理解Buffer hit ratio 是99%, 但Page life expectancy<200?
我这里不做详述,可以参考我的另一篇博文,里面有详述。http://www.cnblogs.com/wy123/p/5272675.html
另外,真的很佩服老外,从本质上阐述了Buffer Cache hit ratio,能把学问做的这么认真,真的不容易。
通过sql查询缓存命中率
SELECT CAST(CAST((a.cntr_value * 1.0 / b.cntr_value)*100 as int) AS VARCHAR(20)) as BufferCacheHitRatio FROM ( SELECT * FROM sys.dm_os_performance_counters WHERE counter_name = \'Buffer cache hit ratio\' AND object_name = CASE WHEN @@SERVICENAME = \'MSSQLSERVER\' THEN \'SQLServer:Buffer Manager\' ELSE \'MSSQL$\' + rtrim(@@SERVICENAME) + \':Buffer Manager\' END ) a CROSS JOIN ( SELECT * from sys.dm_os_performance_counters WHERE counter_name = \'Buffer cache hit ratio base\' and object_name = CASE WHEN @@SERVICENAME = \'MSSQLSERVER\' THEN \'SQLServer:Buffer Manager\' ELSE \'MSSQL$\' + rtrim(@@SERVICENAME) + \':Buffer Manager\' END ) b
- Page reads(writes) / sec
这两个计数器分别是对应的平均每秒钟的物理读/写的数据量,这个计数器的是一个累计值,单位为page,而每个page又是8Kb,
可以换算成一个基于kb或者mb位单位数据
对于计数器中的类似累计值,并不妨碍我们通过计算得出某个时间间隔内的平均值。
也就是说,
对于 Page reads / sec,一个查询在执行过程中,发现需要的数据不存在于buffer pool中,需要到磁盘上去查询
对于 Page writes / sec ,就是在面临内存压力的时候,将内存页写入磁盘来腾出内存空间
上面说了,直接从buffer pool中,也就是内存中读取数据和从磁盘中读取数据的时间上的差别是巨大的,对性能的影响也是非常明显的
实际中我们也会经常遇到这种现象,有些SQL查询语句,第一次执行比较慢,但是再次执行的时候,就相对快了很多,
当然通过set statistics io 这个信息也能发现有第一次存在物理读的现象,这种速度上的差别,还是比较明显的
这两个值可以通过如下sql查询得到
select * from sys.dm_os_performance_counters where object_name like \'%Buffer Manager%\' and (counter_name=\'Page reads/sec\' or counter_name=\'Page writes/sec\' )
如果一台服务器上经常发生大批量的物理性IO操作,你就要注意是否存在内存问题,
因为经常性的大批量的物理IO会严重拖慢SQL的执行效率,理想情况下,这个值不应该过大,也有材料上说不能持续大于0,我个人觉得有点绝对了
其实也没有一个绝对的标准,只要这个值能够稳定在一个较低的水平,没有持续性的大批量数据的写入(磁盘)于读取(从磁盘载入内存),都可以接受
相反,如果长期在一个高位水平,并且观察到PLE不能稳定在参考值范围内,说明内存可能存在瓶颈。
- Lazy writes / sec
Lazy writes 是每秒被缓冲区管理器的惰性编写器(lazy writer)写入的缓存区的数据page信息。
Lazy writer是一个系统进程,用于批量刷新内存中的脏页到磁盘,并且将原来脏页占用的内存空间清理的一个动作。
如果存在内存压力,Lazy writer会被触发,将脏页和长时间没有用到的计划缓存清理出内存,
如果经常被触发,那么说明内存可能存在瓶颈
需要注意的是,通过如下 sys.dm_os_performance_counters 查询出来的Lazy writes/sec值是一个累计值
但是这也不妨碍我们得出某一个时间间隔内发生的Lazy writes/sec的数据,相信聪明的你一定可以算出来
select * from sys.dm_os_performance_counters where object_name like \'%Buffer Manager%\' and counter_name=\'Lazy writes/sec\'
对于脏页以及老化的缓存计划,有其他机制去实现写入磁盘存储并清理器占用的内存空间
Lazy Write是在面临内存压力的情况下触发的,
如果某一个时间间隔内,Lazy Write持续不为零,就要结合PLE以及Page reads(writes) / sec 来判断分析内存是否存在不够用的情况了。
说完PLE和Page reads(writes) / sec 以及Lazy writes / sec之后,就可以做一个小小的总结了
上面说了,衡量内存瓶颈的时候,通常要结合多个值来做出判断,
如果你的PLE不在计算出来的参考值预期之内,同时又伴随着大量的Page reads(writes) / sec
那么就几乎可以断定你的服务器存在内存瓶颈了
因为PLE达不到预期值,也就是说可能有大量所需要的数据不存在于缓存中,
而去读这些数据,又要进行从磁盘上的物理读取,那么就会出现Page reads(writes) / sec 较高的现象
物理读取出来的数据要占用缓存空间(之后才能返回给查询的客户端),
而原来缓存空间中的数据是通过Lazy writes被清理出内存,这样数据从磁盘进入缓存,而缓存中的数据又被清理出去,造成的结果就是PLE上不去
所以结合这三个值的信息,基本上就可以断定你的内存是否存在瓶颈。
当然除了上述三个计数器,还有其他更多的信息去对内存做诊断,我们继续。
- Total Server Memory/Target Server Memory
Total Server Memory是Sql Server内存管理器“已提交”内存,说白了就是已经占用了的内存,
而Target Server Memory则是Sql Server内存管理器可用的最大内存
这两个值也可用通过sys.dm_os_performance_counters 查询出来
select * from sys.dm_os_performance_counters where object_name like \'%Memory Manager%\' and counter_name in (\'Target Server Memory (KB)\',\'Total Server Memory (KB)\')
当Total Server Memory小于Target Server Memory的时候,Sql Server还知道系统还有可用内存,在需要内存中的时候,直接跟系统申请,
此时Total Server Memory会逐渐变大。
但是,当Total Server Memory接近于或者等于Target Server Memory的时候,Sql Server会意识到已经用完了系统的可用内存,
如果在需要内存的时候,系统已经无法继续分配新的内存,它就需要清理已用的内存空间,将新清理出来的空间给新的数据使用
这个似乎又要跟上面说的PLE以及lazy write联系上了,
当然,系统内存空间往往是小于数据的空间的,比如有可能你的数据库文件大小是500GB,而内存之后32G或者64G,
数据库经过一段时间的运行后,Total Server Memory总是接近于或者等于Target Server Memory的,
那么我们说Total Server Memory和Target Server Memory的意义何在?
上面说了,鉴于数据文件中的数据往往都是大于可用物理内存的(当然极端例子也有,你数据库只有2GB,内存32GB)
数据很有可能不完全都能缓存在内存中,但是最起码,要缓存持续到一定时间再去释放空间(给新的数据使用),而不是不停地直接去读磁盘,这就要求有一个度
你不能说Total Server Memory总是接近于或者等于Target Server Memory,没内存用了,清理内存是正常的
如果缓存75分钟是正常的,
发现Total Server Memory持续性接近或者等于Target Server Memory,而PLE明显低于计算出来的参考值,低到几分钟甚至一两分钟,
同时观察到内存跟磁盘之间频繁地、大量地物理性交换数据,这也说明,内存极有可能存在瓶颈。
- Paging File % Usage
Paging File也即缓存文件,另外一个名字叫做虚拟内存,你一定听说过,就是用拿物理磁盘空间当做内存空间使用,
Windows系统的虚拟内存文件一般是存储在C盘的,一个叫pagefile.sys的文件,默认是隐藏的
如下截图
这里先说明两个问题:
1,Sql Server会用到缓存文件吗?
答案是:会
2,Sql Server能否控制使用物理内存还是page file?
答案是:不能,一个windows上的应用,使用物理内存还是page file,是由操作系统决定的,应用程序本身无法决定自身去使用哪一部分内存
那么如何知道使用了多少缓存文件空间,通过sys.dm_os_sys_memory这个视图可以查询出来。
当然我这个截图是在我本机,看不出来有什么特别大的使用了,一个字段是total_page_file_kb,一个是available_page_file_kb
顾名思义,总的减去可用的,就是已用的

那么,文件缓存跟内存瓶颈有什么关系呢?
应用程序对文件缓存的使用时不受自身因素控制的,完全是由操作系统来决定的,Sql Sever也不例外,文件缓存使用的多少当然也是由操作系统来调度
文件缓存的使用多少能反映什么?
如果说文件缓存使用的越多,从侧面可以反映出来服务器上当前物理内存和实际需求内存之间的差距,当然这个差距越大,说明内存缺乏程度越高
文件缓存的使用是受到Windows操作系统调度的,这一点Sql Server无法决定自己的缓存数据是存放在屋里内存中或者是page file中,
这一点就是一个黑盒了,具体算法我无从得知
从实际测试来看,物理内存的消耗和page file的消耗是同步的,
举个例子,执行一个非常大的查询,通过 sys.dm_os_sys_memory可以非常清楚地观察到,
在消耗物理内存的同时,也伴随着虚拟内存的消耗,这两者到底怎么分配,或者这之间有什么线性关系,我目前还不清楚,也希望有高人指点
可以很明确地说,某些生产服务器,因为缺乏物理内存,32GB的物理内存的机器,
对于文件缓存的使用达到了一个非常高的程度(30多个GB),超过了物理内存本身
这应该就是一种非正常状态,不过这个值也没有一个权威的数据,也希望有了解的可以留言贡献
当然获取某些环境下有更大的文件缓存使用,我只是没见过而已。
根据page file的使用情况,发现如果大量使用page file,甚至超过了物理内存本身,
可以大概了解到Sql Server服务器实际所需内存与现有内存的差异程度。
也可以在进行内存瓶颈判断的时候,作为参考指标之一。
总结
林林总总阐述了上述几个内存瓶颈压力判断指标,也仅仅是涉及到了一部分跟内存有关的计数器,当然包括但不限于上述几个值。
如果做内存瓶颈判断,可以有更多的参考值,
前文也说了,内存压力下,
Sql Server是一个具备自我调节(self tuning)的应用系统,各个计数值的值是具有一系列的相关性的,往往多个性能计数器会表现出来一些一致性的特征
比如内存不足的情况下:PLE上达不到预期值,Page reads(writes) / sec 又持续保持在一个较高的水平,同时伴随着Lazy Writer / sec 持续性的发生
如果有更多的其它参考的判断指标,当然更具备说服力
但是如果通过上述值,也能将内存的压力是否存在瓶颈定位个八九不离十。
对于其他的内存相关的计数器,有时间会继续总结。
其实说了这么些相关内容,也仅仅是对Sql Server内存一个做了一个非常粗略的分析,当然也可以对各个部分的内存分类进行进一步细化的分析和论述。
本文粗浅第分析了判断Sql Server内存瓶颈的一些知识点,尚有不足的地方还请指出,谢谢。希望能够帮到各位对Sql Server感兴趣的看官,共同学习。
以上是关于Sql Server 内存相关计数器以及内存压力诊断的主要内容,如果未能解决你的问题,请参考以下文章
Performance Monitor3:监控SQL Server的内存压力
Performance Monitor3:监控SQL Server的内存压力
(译)内存沉思:多个名称相关的神秘的SQL Server内存消耗者。