爬虫(Requests)
Posted l736
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫(Requests)相关的知识,希望对你有一定的参考价值。
什么是Requests
Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,但他比urllib更加方便,可以完全替代urllib。一句话,requests是python实现的最简单易用的HTTP库,建议爬虫使用requests库。以下为总体功能的一个演示:
import requests
response = requests.get("https://www.baidu.com")
print(type(response))
print(response.status_code)
print(type(response.text))
print(response.text)
print(response.cookies)
print(response.content)
print(response.content.decode("utf-8"))
我们可以看出response使用起来确实非常方便,这里有个问题需要注意一下:
很多情况下的网站如果直接response.text会出现乱码的问题,所以这个使用response.content,这样返回的数据格式其实是二进制格式,然后通过decode()转换为utf-8,这样就解决了通过response.text直接返回显示乱码的问题.
请求发出后,Requests 会基于 HTTP 头部对响应的编码作出有根据的推测。当你访问 response.text 之时,Requests 会使用其推测的文本编码。你可以找出 Requests 使用了什么编码,并且能够使用 response.encoding 属性来改变它.如:
response =requests.get("http://www.baidu.com")
response.encoding="utf-8"
print(response.text)
不管是通过response.content.decode("utf-8)的方式还是通过response.encoding="utf-8"的方式都可以避免乱码的问题发生
一、各种请求方式
requests里提供个各种请求方式,但主要用的还是get和post。
import requests
requests.post("http://httpbin.org/post")
requests.put("http://httpbin.org/put")
requests.delete("http://httpbin.org/delete")
requests.head("http://httpbin.org/get")
requests.options("http://httpbin.org/get")
(一)get方式
1.基本GET请求
import requests response = requests.get(‘http://httpbin.org/get‘) print(response.text)
2.带参数的GET请求,例子1
import requests
response = requests.get("http://httpbin.org/get?name=zhaofan&age=23")
print(response.text)
如果我们想要在URL查询字符串传递数据,通常我们会通过httpbin.org/get?key=val方式传递。Requests模块允许使用params关键字传递参数,以一个字典来传递这些参数,例子如下:
import requests
data = {
"name":"zhaofan",
"age":22
}
response = requests.get("http://httpbin.org/get",params=data)
print(response.url)
print(response.text)
上述两种的结果是相同的,通过params参数传递一个字典内容,从而直接构造url
注意:第二种方式通过字典的方式的时候,如果字典中的参数为None则不会添加到url上
3.解析json
import requests
import json
response = requests.get("http://httpbin.org/get")
print(type(response.text))
print(response.json())
print(json.loads(response.text))
print(type(response.json()))
从结果可以看出requests里面集成的json其实就是执行了json.loads()方法,两者的结果是一样的
4.获取二进制数据
在上面提到了response.content,这样获取的数据是二进制数据,同样的这个方法也可以用于下载图片以及视频资源。
1 import requests 2 resp=requests.get("https://pic2.zhimg.com/v2-a1f9b040fc2ab292faf162c44e4bf4ff_b.jpg") 3 print(resp.status_code) 4 5 #获取的内容为二进制 6 print(resp.content) 7 #wb 以二进制的方式进行写。先读后写 8 with open ("2.jpg","wb") as f: 9 f.write(resp.content) 10 f.close()
5.添加headers
和前面我们将urllib模块的时候一样,我们同样可以定制headers的信息,如当我们直接通过requests请求知乎网站的时候,默认是无法访问的。
import requests
response =requests.get("https://www.zhihu.com")
print(response.text)
这样会得到如下的错误
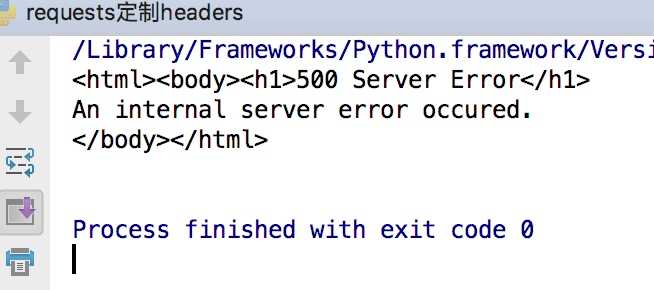
因为访问知乎需要头部信息,这个时候我们在谷歌浏览器里输入chrome://version,就可以看到用户代理,将用户代理添加到头部信息
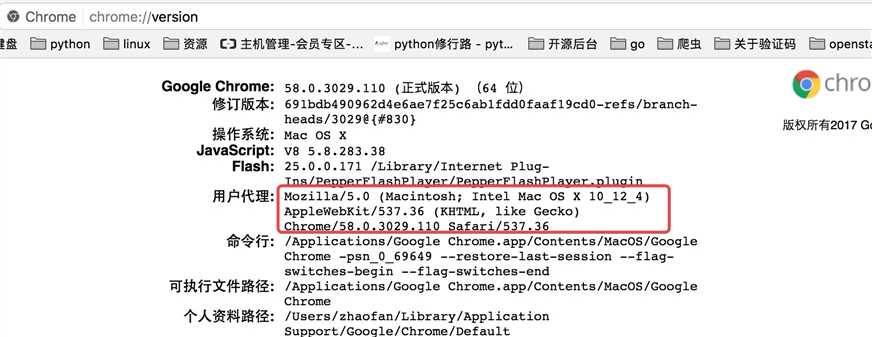
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
response =requests.get("https://www.zhihu.com",headers=headers)
print(response.text)
这样就可以正常的访问知乎了
(二)基本POST请求
通过在发送post请求时添加一个data参数,这个data参数可以通过字典构造成,这样对于发送post请求就非常方便。
注:post的三个参数
response = requests.post("http://httpbin.org/post", data=data, headers=headers)
import requests
data = {
"name":"zhaofan",
"age":23
}
response = requests.post("http://httpbin.org/post",data=data)
print(response.text)
同样的在发送post请求的时候也可以和发送get请求一样通过headers参数传递一个字典类型的数据
二、响应
我们可以通过response获得很多属性,例子如下
1 import requests 2 response = requests.get("http://www.baidu.com") 3 4 print(type(response.status_code),response.status_code) #显示状态 5 print(type(response.headers),response.headers) 6 print(type(response.cookies),response.cookies) 7 print(type(response.url),response.url) 8 print(type(response.history),response.history) 9 print(response.text) #显示内容 10 print(response.content) #显示内容(二进制)
结果如下:



1 注:状态码判断 2 Requests还附带了一个内置的状态码查询对象 3 主要有如下内容: 4 5 100: (‘continue‘,), 6 101: (‘switching_protocols‘,), 7 102: (‘processing‘,), 8 103: (‘checkpoint‘,), 9 122: (‘uri_too_long‘, ‘request_uri_too_long‘), 10 200: (‘ok‘, ‘okay‘, ‘all_ok‘, ‘all_okay‘, ‘all_good‘, ‘\\o/‘, ‘?‘), 11 201: (‘created‘,), 12 202: (‘accepted‘,), 13 203: (‘non_authoritative_info‘, ‘non_authoritative_information‘), 14 204: (‘no_content‘,), 15 205: (‘reset_content‘, ‘reset‘), 16 206: (‘partial_content‘, ‘partial‘), 17 207: (‘multi_status‘, ‘multiple_status‘, ‘multi_stati‘, ‘multiple_stati‘), 18 208: (‘already_reported‘,), 19 226: (‘im_used‘,), 20 21 Redirection. 22 300: (‘multiple_choices‘,), 23 301: (‘moved_permanently‘, ‘moved‘, ‘\\o-‘), 24 302: (‘found‘,), 25 303: (‘see_other‘, ‘other‘), 26 304: (‘not_modified‘,), 27 305: (‘use_proxy‘,), 28 306: (‘switch_proxy‘,), 29 307: (‘temporary_redirect‘, ‘temporary_moved‘, ‘temporary‘), 30 308: (‘permanent_redirect‘, 31 ‘resume_incomplete‘, ‘resume‘,), # These 2 to be removed in 3.0 32 33 Client Error. 34 400: (‘bad_request‘, ‘bad‘), 35 401: (‘unauthorized‘,), 36 402: (‘payment_required‘, ‘payment‘), 37 403: (‘forbidden‘,), 38 404: (‘not_found‘, ‘-o-‘), 39 405: (‘method_not_allowed‘, ‘not_allowed‘), 40 406: (‘not_acceptable‘,), 41 407: (‘proxy_authentication_required‘, ‘proxy_auth‘, ‘proxy_authentication‘), 42 408: (‘request_timeout‘, ‘timeout‘), 43 409: (‘conflict‘,), 44 410: (‘gone‘,), 45 411: (‘length_required‘,), 46 412: (‘precondition_failed‘, ‘precondition‘), 47 413: (‘request_entity_too_large‘,), 48 414: (‘request_uri_too_large‘,), 49 415: (‘unsupported_media_type‘, ‘unsupported_media‘, ‘media_type‘), 50 416: (‘requested_range_not_satisfiable‘, ‘requested_range‘, ‘range_not_satisfiable‘), 51 417: (‘expectation_failed‘,), 52 418: (‘im_a_teapot‘, ‘teapot‘, ‘i_am_a_teapot‘), 53 421: (‘misdirected_request‘,), 54 422: (‘unprocessable_entity‘, ‘unprocessable‘), 55 423: (‘locked‘,), 56 424: (‘failed_dependency‘, ‘dependency‘), 57 425: (‘unordered_collection‘, ‘unordered‘), 58 426: (‘upgrade_required‘, ‘upgrade‘), 59 428: (‘precondition_required‘, ‘precondition‘), 60 429: (‘too_many_requests‘, ‘too_many‘), 61 431: (‘header_fields_too_large‘, ‘fields_too_large‘), 62 444: (‘no_response‘, ‘none‘), 63 449: (‘retry_with‘, ‘retry‘), 64 450: (‘blocked_by_windows_parental_controls‘, ‘parental_controls‘), 65 451: (‘unavailable_for_legal_reasons‘, ‘legal_reasons‘), 66 499: (‘client_closed_request‘,), 67 68 Server Error. 69 500: (‘internal_server_error‘, ‘server_error‘, ‘/o\\‘, ‘?‘), 70 501: (‘not_implemented‘,), 71 502: (‘bad_gateway‘,), 72 503: (‘service_unavailable‘, ‘unavailable‘), 73 504: (‘gateway_timeout‘,), 74 505: (‘http_version_not_supported‘, ‘http_version‘), 75 506: (‘variant_also_negotiates‘,), 76 507: (‘insufficient_storage‘,), 77 509: (‘bandwidth_limit_exceeded‘, ‘bandwidth‘), 78 510: (‘not_extended‘,), 79 511: (‘network_authentication_required‘, ‘network_auth‘, ‘network_authentication‘),
通过下面例子测试:(不过通常还是通过状态码判断更方便)
import requests
response= requests.get("http://www.baidu.com")
if response.status_code == requests.codes.ok:
print("访问成功")
三、requests高级用法
1.文件上传
实现方法和其他参数类似,也是构造一个字典然后通过files参数传递
import requests
files= {"files":open("git.jpeg","rb")}
response = requests.post("http://httpbin.org/post",files=files)
print(response.text)
结果如下:
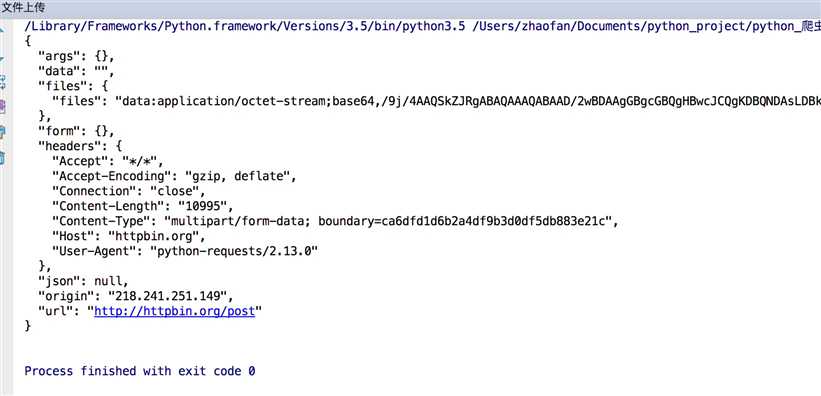
2.获取cookie
import requests
response = requests.get("http://www.baidu.com")
print(response.cookies)
for key,value in response.cookies.items():
print(key+"="+value)
3.会话维持
cookie的一个作用就是可以用于模拟登陆,做会话维持
import requests
s = requests.Session()
s.get("http://httpbin.org/cookies/set/number/123456")
response = s.get("http://httpbin.org/cookies")
print(response.text)
这是正确的写法,而下面的写法则是错误的
import requests
requests.get("http://httpbin.org/cookies/set/number/123456")
response = requests.get("http://httpbin.org/cookies")
print(response.text)
因为这种方式是两次requests请求之间是独立的,而第一次则是通过创建一个session对象,两次请求都通过这个对象访问
4.证书验证
现在的很多网站都是https的方式访问,所以这个时候就涉及到证书的问题
import requests
response = requests.get("https:/www.12306.cn")
print(response.status_code)
默认的12306网站的证书是不合法的,这样就会提示如下错误
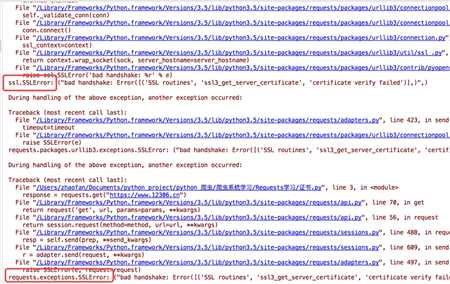
为了避免这种情况的发生可以通过verify=False
但是这样是可以访问到页面,但是会提示:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings InsecureRequestWarning)
解决方法为:
import requests
from requests.packages import urllib3
urllib3.disable_warnings()
response = requests.get("https://www.12306.cn",verify=False)
print(response.status_code)
这样就不会提示警告信息,当然也可以通过cert参数放入证书路径
5.代理设置
import requests
proxies= {
"http":"http://127.0.0.1:9999",
"https":"http://127.0.0.1:8888"
}
response = requests.get("https://www.baidu.com",proxies=proxies)
print(response.text)
如果代理需要设置账户名和密码,只需要将字典更改为如下:
proxies = {
"http":"http://user:[email protected]:9999"
}
如果你的代理是通过sokces这种方式则需要pip install "requests[socks]"
proxies= {
"http":"socks5://127.0.0.1:9999",
"https":"sockes5://127.0.0.1:8888"
}
6.超时设置
通过timeout参数可以设置超时的时间
1 import requests 2 from requests.exceptions import ReadTimeout 3 try: 4 response = requests.get("http://httpbin.org/get", timeout = 0.5) 5 print(response.status_code) 6 except ReadTimeout: 7 print(‘Timeout‘)
7.认证设置
如果碰到需要认证的网站可以通过requests.auth模块实现
import requests
from requests.auth import HTTPBasicAuth
response = requests.get("http://120.27.34.24:9001/",auth=HTTPBasicAuth("user","123"))
print(response.status_code)
当然这里还有一种方式
import requests
response = requests.get("http://120.27.34.24:9001/",auth=("user","123"))
print(response.status_code)
8.异常处理
关于reqeusts的异常在这里可以看到详细内容:
http://www.python-requests.org/en/master/api/#exceptions
所有的异常都是在requests.excepitons中

从源码我们可以看出RequestException继承IOError,
HTTPError,ConnectionError,Timeout继承RequestionException
ProxyError,SSLError继承ConnectionError
ReadTimeout继承Timeout异常
这里列举了一些常用的异常继承关系,详细的可以看:
http://cn.python-requests.org/zh_CN/latest/_modules/requests/exceptions.html#RequestException
通过下面的例子进行简单的演示
import requests
from requests.exceptions import ReadTimeout,ConnectionError,RequestException
try:
response = requests.get("http://httpbin.org/get",timout=0.1)
print(response.status_code)
except ReadTimeout:
print("timeout")
except ConnectionError:
print("connection Error")
except RequestException:
print("error")
其实最后测试可以发现,首先被捕捉的异常是timeout,当把网络断掉的haul就会捕捉到ConnectionError,如果前面异常都没有捕捉到,最后也可以通过RequestExctption捕捉到
以上是关于爬虫(Requests)的主要内容,如果未能解决你的问题,请参考以下文章