HBase整合MapReduce之建立HBase索引
Posted 汤高
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase整合MapReduce之建立HBase索引相关的知识,希望对你有一定的参考价值。
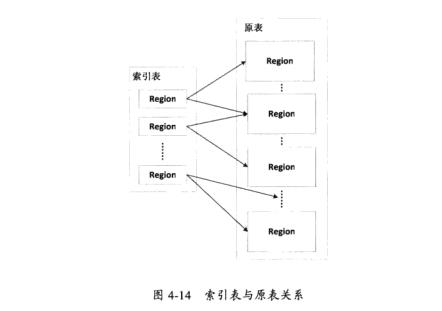
HBase索引主要用于提高Hbase中表数据的访问速度,有效的避免了全表扫描,HBase中的表根据行健被分成了多个Regions,通常一个region的一行都会包含较多的数据,如果以列值作为查询条件,就只能从第一行数据开始往下找,直到找到相关数据为止,这很低效。相反,如果将经常被查询的列作为行健、行健作为列重新构造一张表,即可实现根据列值快速定位相关数据所在的行,这就是索引。显然索引表仅需要包含一个列,所以索引表的大小和原表比起来要小得多,如图4-14给出了索引表与原表之间的关系。从图可以看出,由于索引表的单条记录所占的空间比原表要小,所以索引表的一个Region与原表相比,能包含更多条记录
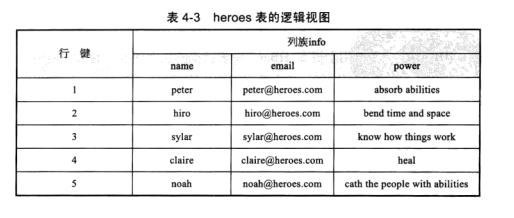
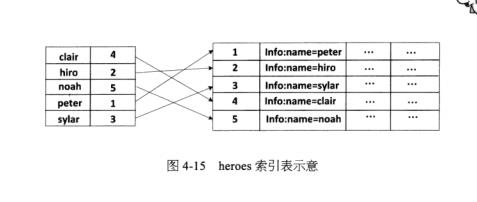
假设HBase中存在一张表heroes,里面的内容如表所示,则根据列info:name构建的索引表如图4-15所示。Hbase会自动将生成的索引表加入如图4-3所示的结构中,从而提高搜索的效率
下面看代码实现
首先创建heroes表
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Table;
import org.apache.hadoop.hbase.util.Bytes;
public class CreateTable {
public static void main(String[] args) {
// 2.获得会话
Admin admin = null;
Connection con = null;
try {
// 操作hbase数据库
// 1.建立连接
Configuration conf = HBaseConfiguration.create(); // 获得配制文件对象
conf.set("hbase.zookeeper.quorum", "192.168.52.140");
con = ConnectionFactory.createConnection(conf); // 获得连接对象
TableName tn = TableName.valueOf("heroes");
admin = con.getAdmin();
HTableDescriptor htd = new HTableDescriptor(tn);
HColumnDescriptor hcd = new HColumnDescriptor("info");
htd.addFamily(hcd);
admin.createTable(htd);
Table t = con.getTable(tn);
String[] heronames = new String[] { "peter", "hiro", "sylar", "claire", "noah" };
for (int i = 0; i < 5; i++) {
Put put = new Put((i + "").getBytes());
put.addColumn("info".getBytes(), "name".getBytes(), heronames[i].getBytes());
put.addColumn("info".getBytes(), "email".getBytes(), (i + "@qq.com").getBytes());
put.addColumn("info".getBytes(), "power".getBytes(), "Idotknow".getBytes());
t.put(put);
}
admin.close();
con.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}然后根据heroes表建立索引表
package com.tg.index;
import java.io.IOException;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
public class CreateHbaseIndex {
//map阶段,根据hbase中的数据取出行健和姓名
public static class HbaseIndexMapper extends TableMapper<ImmutableBytesWritable, ImmutableBytesWritable>{
@Override
protected void map(ImmutableBytesWritable key, Result value,
Mapper<ImmutableBytesWritable, Result, ImmutableBytesWritable, ImmutableBytesWritable>.Context context)
throws IOException, InterruptedException {
List<Cell> cs = value.listCells();
for (Cell cell : cs) {
String qualifier = Bytes.toString(CellUtil.cloneQualifier(cell));
System.out.println("qualifier="+qualifier);
if(qualifier.equals("name")){
//把名字做键 行健做值输出
context.write(new ImmutableBytesWritable(CellUtil.cloneValue(cell)), new ImmutableBytesWritable(CellUtil.cloneRow(cell)));
}
}
}
}
//reduce阶段,将姓名作为键,行健作为值存入hbase
public static class HbaseIndexReduce extends TableReducer<ImmutableBytesWritable, ImmutableBytesWritable, ImmutableBytesWritable>{
@Override
protected void reduce(ImmutableBytesWritable key, Iterable<ImmutableBytesWritable> value,
Reducer<ImmutableBytesWritable, ImmutableBytesWritable, ImmutableBytesWritable, Mutation>.Context context)
throws IOException, InterruptedException {
//把名字做行健
Put put=new Put(key.get());
//把行健做值
for (ImmutableBytesWritable v : value) {
put.addColumn("rowkey".getBytes(),"index".getBytes(),v.get() );
}
context.write(key, put);
}
}
private static void checkTable(Configuration conf) throws Exception {
Connection con = ConnectionFactory.createConnection(conf);
Admin admin = con.getAdmin();
TableName tn = TableName.valueOf("heroesIndex");
if (!admin.tableExists(tn)){
HTableDescriptor htd = new HTableDescriptor(tn);
HColumnDescriptor hcd = new HColumnDescriptor("rowkey".getBytes());
htd.addFamily(hcd);
admin.createTable(htd);
System.out.println("表不存在,新创建表成功....");
}
}
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf = HBaseConfiguration.create(conf);
conf.set("hbase.zookeeper.quorum", "192.168.52.140");
Job job = Job.getInstance(conf, "heroes");
job.setJarByClass(CreateHbaseIndex.class);
Scan scan = new Scan();
scan.addColumn(Bytes.toBytes("info"), Bytes.toBytes("name"));
TableMapReduceUtil.initTableMapperJob("heroes", scan, HbaseIndexMapper.class,
ImmutableBytesWritable.class, ImmutableBytesWritable.class,job);
TableMapReduceUtil.initTableReducerJob("heroesIndex", HbaseIndexReduce.class, job);
checkTable(conf);
System.exit(job.waitForCompletion(true) ? 0 : 1);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
heroes原表的记录如下图:
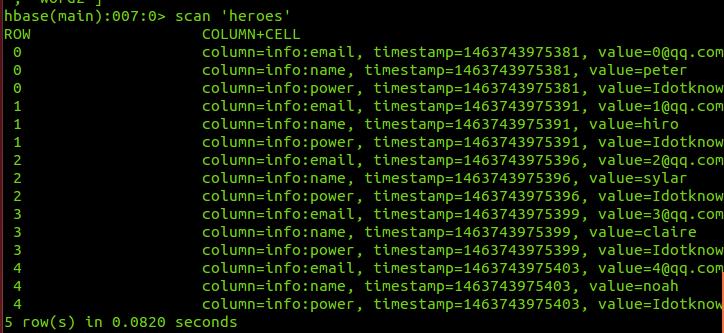
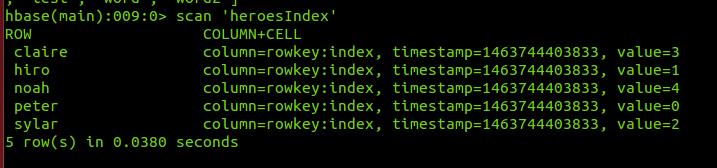
创建的索引表记录如下图:
转载请指明出处 http://blog.csdn.net/tanggao1314/article/details/51464226
以上是关于HBase整合MapReduce之建立HBase索引的主要内容,如果未能解决你的问题,请参考以下文章