用bs4和urllib 爬取视频
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用bs4和urllib 爬取视频相关的知识,希望对你有一定的参考价值。
实验对象:麦子学院
1、大部分视频信息都存在http://www.maiziedu.com/course/all/中,所有的视频信息都有自己的ID,第一次查询地址应该是在:‘http://www.maiziedu.com/course/‘ + id中
?



分析页面获取title ,为创建文件夹获取目录
url_dict1 = {}
url = ‘http://www.maiziedu.com/course/{}‘.format(num)
page = urllib.request.urlopen(url)
context = page.read().decode(‘utf8‘)
title = re.search(‘<title>.*</title>‘, context)
title = title.group().strip(‘</title>‘)
if ‘500‘ in title:
return {}
else:
#对文件夹进行进一步的精简
if (len(title.split(":")) != 1):
title = title.split(":")[1]
title=title.split(‘-‘)[0]
url_dict1[‘url‘] = url
url_dict1[‘title‘] = title
# urls.append(url_dict1)
return url_dict1?
获取字典包含url和title
这一部分就是进行分析,获取到页面所有章节的地址和标题
在python代码中用bs4 分析并获取播放页面链接
?
urls = [] page = urllib.request.urlopen(url) context = page.read().decode(‘utf8‘) soup = BeautifulSoup(context, "html.parser") for tag in soup.find(‘ul‘, class_=‘lesson-lists‘).find_all(‘li‘): urls.append(tag.find(‘a‘).get(‘href‘).split(‘/‘)[-2]) return urls
返回所有章节的url和title
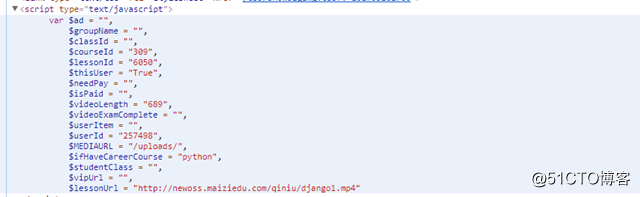
2、播放页面分析页面播放路径是从js中明文调用的,直接获取网站的title及视频调用的js文件中的url路径
page = urllib.request.urlopen(url) context = page.read().decode(‘utf8‘) soup = BeautifulSoup(context, "html.parser") title = soup.find(‘div‘, class_=‘bottom-module‘).find_all(‘span‘, class_=‘title‘)[0] title = re.compile(r‘<[^>]+>‘, re.S).sub(‘‘, str(title)) + ‘.mp4‘ ok = soup.find_all(‘script‘)[2] return ok.string.split(‘"‘)[-2], title
此处获取title是为了保存文件时,按照网站显示内容进行重命名。3、下载文件
{kind=link}
def report(count, blockSize, totalSize): j = ‘#‘ percent = int(count * blockSize * 100 / totalSize) sys.stdout.write(str(percent) + ‘% [‘ + j * int(percent / 2) + ‘->‘ + "]\r") sys.stdout.flush() def download(url, filename): # BASE_DIR = os.path.split(os.path.realpath(__file__))[0] saveFile = os.path.join(BASE_DIR, filename) if not os.path.exists(saveFile): urllib.request.urlretrieve(url, saveFile, reporthook=report) sys.stdout.write("\n\rDownload complete, saved as %s" % (saveFile) + ‘\n\r‘) sys.stdout.flush() else: print(‘文件已存在!跳过继续下载下一个‘)?
report 在命令行显示下载进度
urlretrieve进行下载,也可以使用其他方式
?
总结:
使用urlib+bs4直接粗暴的下载麦子视频文件,有许多不如意的地方需要改进,因版权原因,不在此贴出源码
以上是关于用bs4和urllib 爬取视频的主要内容,如果未能解决你的问题,请参考以下文章