框架 day33 Hibernate,组件映射,继承映射,抓取(检索)策略-优化,检索方式总结
Posted 飛白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了框架 day33 Hibernate,组件映射,继承映射,抓取(检索)策略-优化,检索方式总结相关的知识,希望对你有一定的参考价值。
组件(组成)映射
例1:
public class Person {
private Integer pid; //OID 值
private String name;
//第一种方案
private String homeAddr;
private String homeTel;
private String companyAddr;
private String companyTel;↑一般项目都都采用此方案()
*通过面向对象角度,使用设计模式(组件|组合),将数据都抽取到一个对象中。将多个对象组合在一起,达到重复利用目的。
例2:抽取数据(地址)到一个对象中, 这个值对象既为组件,组件不支持共享引用(没有OID)
public class Address {
//值对象 (vo 值对象/po 持久对象/bo 业务对象)
private String addr;
private String tel;public class Person {
private Integer pid; //OID 值
private String name;
//第二种方案:组合
private Address homeAddress;
private Address companyAddress;组件映射配置
<hibernate-mapping>
<class name="com.itheima.b_component.Person" table="t_person">
<id name="pid">
<generator class="native"></generator>
</id>
<property name="name"></property>
<component name="homeAddress" class="com.itheima.b_component.Address">
<property name="addr" column="homeAddr"></property>
<property name="tel" column="homeTel"></property>
</component>
<component name="companyAddress" class="com.itheima.b_component.Address">
<property name="addr" column="companyAddr"></property>
<property name="tel" column="companyTel"></property>
</component>
</class>
</hibernate-mapping>注意:必须确定组合javabean类型 <component class="">
每一个对象属性必须在表中都存在独有列名。<property column="...">
继承映射
应用场景:
公司的员工,保存:小时工和正式员工
员工类
public class Employee {
private Integer eid;
private String name;public class HourEmployee extends Employee {
private int rate; //小时薪水public class SalaryEmployee extends Employee {
private int salary; //正式薪金简单方式
public class Employee {
private Integer eid;
private String name;
private String temp;//标志 1;小时工2;正式工
private int money; //金额继承方式1:<sub-class>
*所有内容保存一张表,给表提供表示字段,每一个子类具有独有字段

缺点:存在null值。
配置

继承方式2:<joined-subclass> (掌握)
*将提供三种表,主表存放基本信息,两个从表存放独有字段内容。
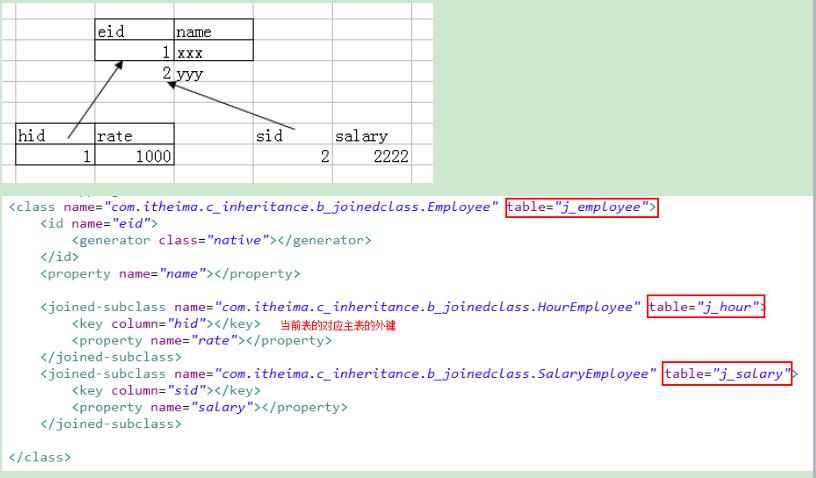
表之间存在一对一关系

一对一:
方式1:主表的主键,与从表的外键(唯一),形成主外键关系
方式2:主表的主键,与从表都主键,形成主外键关系
继承方式3:<union-class>

*缺点: 主键生成策略 increment,不能通过数据库自动生成。存在并发问题
每一次都执行select语句,从三张表中查询oid的最大值。
配置


抓取(检索)策略--优化
*开发中,使用都是默认值,最后进行优化,根据业务要求进行相应设置
3.1检索方式
* 立即检索:在执行查询方法之后,立即执行select语句,进行查询。

↓
//class 标签中lazy=false 立即检索
public void loadCustomerfalse(){
Session session=sessionFacoty.openSession();
Transaction tx=session.beginTransaction();
//该行代码让hibernate执行select语句,查询数据库
Customer c=(Customer)session.load(Customer.class, 1);
c.getId();
c.getAge();
tx.commit();
session.close();
}
*延迟检索:在执行查询方法之后,没有进行查询,底层生成代理对象,直到需要相应的数据,再进行查询。

↓
//class 标签中lazy=true 延迟检索
public void loadCustomertrue(){
Session session=sessionFacoty.openSession();
Transaction tx=session.beginTransaction();
Customer c=(Customer)session.load(Customer.class, 1);
//该行代码让hibernate执行select语句,
//查询数据库(需要用的时候查数据库)
c.getId();
c.getAge();
tx.commit();
session.close();
}
-相应的数据:除OID之外的值,关联数据。
-延迟加载在开发中,主要好处,延缓数据加载,在使用时才进行加载 (缩短数据在内存中时间)
-理解延迟检索中的代理

3.2检索类型
* 类级别检索:当前对象所有属性值。例如:Customer自己数据
Customer c=(Customer)session.load(Customer.class, 1);
session的方法直接检索Customer对象,对Customer对象到底采用立即检索 还是延迟检索方式
通过class元素的lazy属性设定
*关联级别检索:当前对象关联对象数据。例如:Customer 关联 Order 数据
Set set=c.getOrders()//检索Order对象的set集合
session.load(Customer.class, 1):查询的主体表
c.getOrders().size():查询客体表的集合大小
通过set元素lazy属性设定
3.3类级别检索策略
*类级别:查询当前类的所有内容,只查询一次。优化指的是查询时机优化,让空闲时间服务器做出其他处理。
*session.get(Customer.class ,oid) 通过OID立即检索(查询),如果数据不存在返回null。
*session.load(Customer.class , oid ) 默认通过OID延迟检索,如果数据不存在将抛异常。
类级别配置,只对load方法有效。
Customer.hbm.xml <class name="" table=""lazy="true|false">
true:默认值,延迟检索
false:立即检索。
*无论 <class>元素的 lazy 属性是 true 还是 false,
-Session 的 get() 方法及 Query 的 list() 方法在类级别总是使用立即检索策略
*若 <class> 元素的 lazy 属性为 true 或取默认值,
-Session 的 load() 方法不会执行查询数据表的 SELECT 语句, 仅返回代理类对象的实例, 该代理类实例有如下特征:
>由 Hibernate 在运行时采用 javassist 工具动态生成
>Hibernate创建代理类实例时, 仅初始化其 OID 属性
>在应用程序第一次访问代理类实例的非 OID 属性时, Hibernate 会初始化代理类实例
*应用:
-如果程序加载一个对象的目的是为了访问它的属性, 可以采取立即检索.
-如果程序加载一个持久化对象的目的是仅仅为了获得它的引用, 可以采用延迟检索
以上是关于框架 day33 Hibernate,组件映射,继承映射,抓取(检索)策略-优化,检索方式总结的主要内容,如果未能解决你的问题,请参考以下文章
框架 day38 SVN安装及使用,SSH练习项目CRM,环境搭建(myeclipse hibernate 反转引擎生成PO和映射)