多线程-theading
Posted TiAmo_yu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程-theading相关的知识,希望对你有一定的参考价值。
1.使用threading模块
#coding=utf-8 import threading import time def saySorry(): print("亲爱的,我错了,我能吃饭了吗?") time.sleep(1) if __name__ == "__main__": for i in range(5): t = threading.Thread(target=saySorry) t.start() #启动线程,即让线程开始执⾏
说明
1. 可以明显看出使⽤了多线程并发的操作,花费时间要短很多
2. 创建好的线程,需要调⽤ start() ⽅法来启动
2.主线程会等待所有的⼦线程结束后才结束
#coding=utf-8 import threading from time import sleep,ctime def sing(): for i in range(3): print("正在唱歌...%d"%i) sleep(1) def dance(): for i in range(3): print("正在跳舞...%d"%i) sleep(1) if __name__ == \'__main__\': print(\'---开始---:%s\'%ctime()) t1 = threading.Thread(target=sing) t2 = threading.Thread(target=dance) t1.start() t2.start() #sleep(5) # 屏蔽此⾏代码,试试看,程序是否会⽴⻢结束? print(\'---结束---:%s\'%ctime())
3.查看线程数量
while True: length = len(threading.enumerate()) print(\'当前运⾏的线程数为:%d\'%length) if length<=1: break
4.run()方法写
#coding=utf-8 import threading import time class MyThread(threading.Thread): def run(self): for i in range(3): time.sleep(1) msg = "I\'m "+self.name+\' @ \'+str(i) #name属性中保存的是当前线程的名字 print(msg) if __name__ == \'__main__\': t = MyThread() t.start()
说明
python的threading.Thread类有⼀个run⽅法,⽤于定义线程的功能函
数,可以在⾃⼰的线程类中覆盖该⽅法。⽽创建⾃⼰的线程实例后,通
过Thread类的start⽅法,可以启动该线程,交给python虚拟机进⾏调
度,当该线程获得执⾏的机会时,就会调⽤run⽅法执⾏线程。
5.线程的执行顺序
#coding=utf-8 import threading import time class MyThread(threading.Thread): def run(self): for i in range(3): time.sleep(1) msg = "I\'m "+self.name+\' @ \'+str(i) print(msg) def test(): for i in range(5): t = MyThread() t.start() if __name__ == \'__main__\': test()
说明
从代码和执⾏结果我们可以看出,多线程程序的执⾏顺序是不确定的。当执
⾏到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进⼊就
绪(Runnable)状态,等待调度。⽽线程调度将⾃⾏选择⼀个线程执⾏。上
⾯的代码中只能保证每个线程都运⾏完整个run函数,但是线程的启动顺序、
run函数中每次循环的执⾏顺序都不能确定。
6.线程的几种状态
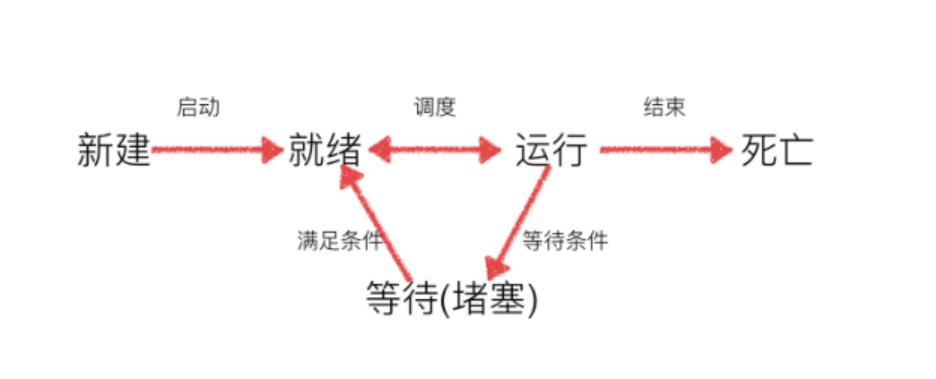
7.多线程-共享全局变量
from threading import Thread import time g_num = 100 def work1(): global g_num for i in range(3): g_num += 1 print("----in work1, g_num is %d---"%g_num) def work2(): global g_num print("----in work2, g_num is %d---"%g_num) print("---线程创建之前g_num is %d---"%g_num) t1 = Thread(target=work1) t1.start() #延时⼀会,保证t1线程中的事情做完 time.sleep(1) t2 = Thread(target=work2) t2.start()
8.列表当中参数传递到线程中
from threading import Thread import time def work1(nums): nums.append(44) print("----in work1---",nums) def work2(nums): #延时⼀会,保证t1线程中的事情做完 time.sleep(1) print("----in work2---",nums) g_nums = [11,22,33] t1 = Thread(target=work1, args=(g_nums,)) t1.start() t2 = Thread(target=work2, args=(g_nums,)) t2.start() 运⾏结果: ----in work1--- [11, 22, 33, 44] ----in work2--- [11, 22, 33, 44]
缺点就是,线程是对全局变量随意遂改可能造成多线程之间对全局变量
的混乱(即线程⾮安全)
9.进程 VS 线程
功能
·进程,能够完成多任务,⽐如 在⼀台电脑上能够同时运⾏多个QQ
·线程,能够完成多任务,⽐如 ⼀个QQ中的多个聊天窗⼝
定义的不同
·进程是系统进⾏资源分配和调度的⼀个独⽴单位.
·线程是进程的⼀个实体,是CPU调度和分派的基本单位,它是⽐进程更⼩的
能独⽴运⾏的基本单位.线程⾃⼰基本上不拥有系统资源,只拥有⼀点在运
⾏中必不可少的资源(如程序计数器,⼀组寄存器和栈),但是它可与同属⼀
个进程的其他的线程共享进程所拥有的全部资源.
区别
·⼀个程序⾄少有⼀个进程,⼀个进程⾄少有⼀个线程.
·线程的划分尺度⼩于进程(资源⽐进程少),使得多线程程序的并发性⾼。
·进程在执⾏过程中拥有独⽴的内存单元,⽽多个线程共享内存,从⽽极
⼤地提⾼了程序的运⾏效率
·线线程不能够独⽴执⾏,必须依存在进程中
优缺点
线程和进程在使⽤上各有优缺点:线程执⾏开销⼩,但不利于资源的管理和
保护;⽽进程正相反。
10.互斥锁
当多个线程⼏乎同时修改某⼀个共享数据的时候,需要进⾏同步控制
线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引⼊互
斥锁。
互斥锁为资源引⼊⼀个状态:锁定/⾮锁定。
threading模块中定义了Lock类,可以⽅便的处理锁定:
#创建锁 mutex = threading.Lock() #锁定 mutex.acquire([blocking]) #释放 mutex.release()
其中,锁定⽅法acquire可以有⼀个blocking参数。
·如果设定blocking为True,则当前线程会堵塞,直到获取到这个锁为⽌
(如果没有指定,那么默认为True)
·如果设定blocking为False,则当前线程不会堵塞
from threading import Thread, Lock import time g_num = 0 def test1(): global g_num for i in range(1000000): #True表示堵塞 即如果这个锁在上锁之前已经被上锁了,那么这个线程会在这⾥⼀直等待到解锁为⽌ #False表示⾮堵塞,即不管本次调⽤能够成功上锁,都不会卡在这,⽽是继续执⾏下⾯的代码 mutexFlag = mutex.acquire(True) if mutexFlag: g_num += 1 mutex.release() print("---test1---g_num=%d"%g_num) def test2(): global g_num for i in range(1000000): mutexFlag = mutex.acquire(True) #True表示堵塞 if mutexFlag: g_num += 1 mutex.release() print("---test2---g_num=%d"%g_num) #创建⼀个互斥锁 #这个所默认是未上锁的状态 mutex = Lock() p1 = Thread(target=test1) p1.start() p2 = Thread(target=test2) p2.start() print("---g_num=%d---"%g_num)
11.同步应用--多个线程有序执⾏
from threading import Thread,Lock from time import sleep class Task1(Thread): def run(self): while True: if lock1.acquire(): print("------Task 1 -----") sleep(0.5) lock2.release() class Task2(Thread): def run(self): while True: if lock2.acquire(): print("------Task 2 -----") sleep(0.5) lock3.release() class Task3(Thread): def run(self): while True: if lock3.acquire(): print("------Task 3 -----") sleep(0.5) lock1.release() #使⽤Lock创建出的锁默认没有“锁上” lock1 = Lock() #创建另外⼀把锁,并且“锁上” lock2 = Lock() lock2.acquire() #创建另外⼀把锁,并且“锁上” lock3 = Lock() lock3.acquire() t1 = Task1() t2 = Task2() t3 = Task3() t1.start() t2.start() t3.start()
12.⽣产者与消费者模式
队列:先进先出
栈:先进后出
⽣产者与消费者模式可以用来解决写入,读取不同步问题
⽣产者消费者模式是通过⼀个容器来解决⽣产者和消费者的强耦合问题。⽣
产者和消费者彼此之间不直接通讯,⽽通过阻塞队列来进⾏通讯,所以⽣产
者⽣产完数据之后不⽤等待消费者处理,直接扔给阻塞队列,消费者不找⽣
产者要数据,⽽是直接从阻塞队列⾥取,阻塞队列就相当于⼀个缓冲区,平
衡了⽣产者和消费者的处理能⼒。
这个阻塞队列就是⽤来给⽣产者和消费者解耦的。纵观⼤多数设计模式,都
会找⼀个第三者出来进⾏解耦,
13.ThreadLocal
ThreadLocal应运⽽⽣,不⽤查找dict,ThreadLocal帮你⾃动做这件事:
import threading # 创建全局ThreadLocal对象: local_school = threading.local() def process_student(): # 获取当前线程关联的student: std = local_school.student print(\'Hello, %s (in %s)\' % (std, threading.current_thread().name)) def process_thread(name): # 绑定ThreadLocal的student: local_school.student = name process_student() t1 = threading.Thread(target= process_thread, args=(\'dongGe\',), name= t2 = threading.Thread(target= process_thread, args=(\'⽼王\',), name= t1.start() t2.start() t1.join() t2.join()
说明
全局变量local_school就是⼀个ThreadLocal对象,每个Thread对它都可以读
写student属性,但互不影响。你可以把local_school看成全局变量,但每个
属性如local_school.student都是线程的局部变量,可以任意读写⽽互不⼲
扰,也不⽤管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是⼀个dict,不但可以⽤
local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常⽤的地⽅就是为每个线程绑定⼀个数据库连接,HTTP请
求,⽤户身份信息等,这样⼀个线程的所有调⽤到的处理函数都可以⾮常⽅
便地访问这些资源。
以上是关于多线程-theading的主要内容,如果未能解决你的问题,请参考以下文章