双向链表
Posted kdy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了双向链表相关的知识,希望对你有一定的参考价值。
1.概念的引入
相信大家都使用过各种集合来进行开发,但是较少的人会去研究其内部的存储原理和调用方法,今天我就来带大家一起学习数据结构算法:双向链表
首先我们先来了解什么是缓存,以及数据在内存中的存储方式.
1.缓存是什么
如果cup读取数据时,每次读取都是从内存再到硬盘读取,那么效率就太低了.
所以可以预先把数据存到内存,然后cup下次从内存读取即可.2.数据在内存中的存储方式
第1种.线性
所谓线性,就是内存是连续的
举例ArrayList或者数组:我们知道,数组存储数据的时候,当你申请100个大小,但是内存不足的时候就会导致内存不足而失败,或者即使你请求到了100个,但是你只存3个数据,那么就浪费内存了
=>优点:查找数据快(好比几个好朋友乘火车,车票都连在一起就好找了)
缺点:1,内存不足就失败;2.浪费内存(买了10张火车票,但是只有3个人乘车,那么就浪费了7张)第2种.链接
内存是链接的(用于解决内存不足,解决线性(上面)问题的不足),比如不连续的空间也能存数据,比如买火车票,有火车票就卖给你,要几张卖几张,不连续位置的也卖.
=>优点:解决内存不足,解决内存浪费
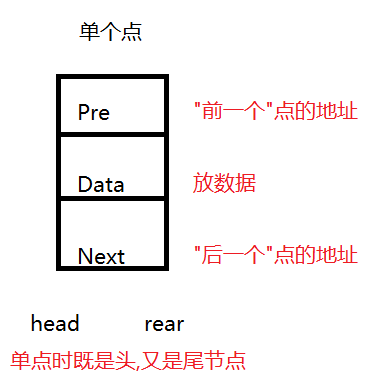
缺点:找人比较慢(票不连续,不一定在一个车厢)节点的属性:
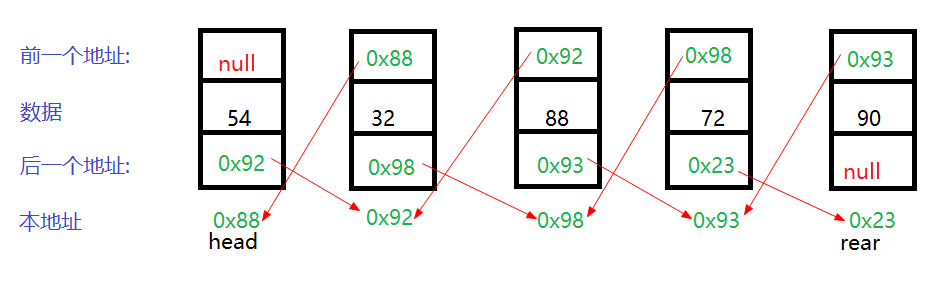
多个节点的内部构造:
代码思路
一.添加节点add(Object obj)
1.Node节点属性:
prev:存放前节点(相当于地址,地址就是指针,指针就是地址)
data:Object各种数据
next:存放下节点
2.定义head,rear节点,当只有一个节点,那么head和rear同指一个节点
3.节点添加的方法add(Object obj)
1.创建节点new Node(),即每加一个数据就创一个节点
2.放数据
3.把节点放入链表中
1.如果头结点为空,那么头结点和尾节点都指向该节点
2.如果头节点不为空
1.往尾部添加
原来的next指向新节点
rear.next = note;
新节点pre指向原节点,新节点也变成尾节点
note.pre = rear
(ps,有需求再设置往头部添加)
4.toString方法[元素1,元素2,元素3] while(head!=null) if(head!=rear)append(head.data+","),***同temp代替head,否则会破坏head,影响后面的remove时head变才null了添加节点过程图
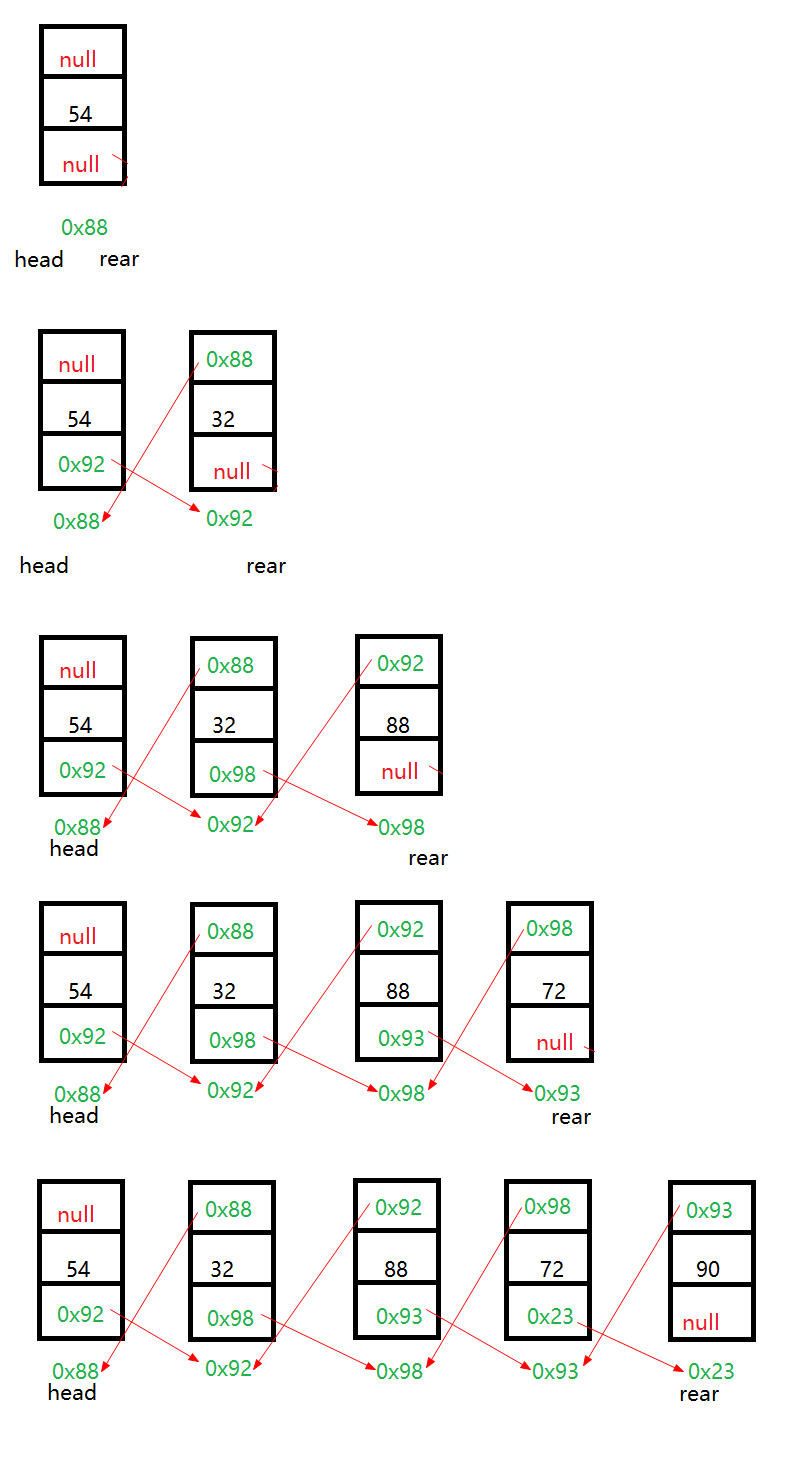
二.删除节点数据remove(Object obj)
注意判断该节点:1.是head 2.还是 rear 3.还是中间某值
1.查找数据所在节点find(Object obj)
1.从头结点开始遍历Note temp = head
2.while循环(temp!=null) 如果找到是数据相同就停止
判断数据相同的两标准 equals 和hashCode()
否则temp = temp.next,下一个
3.返回节点
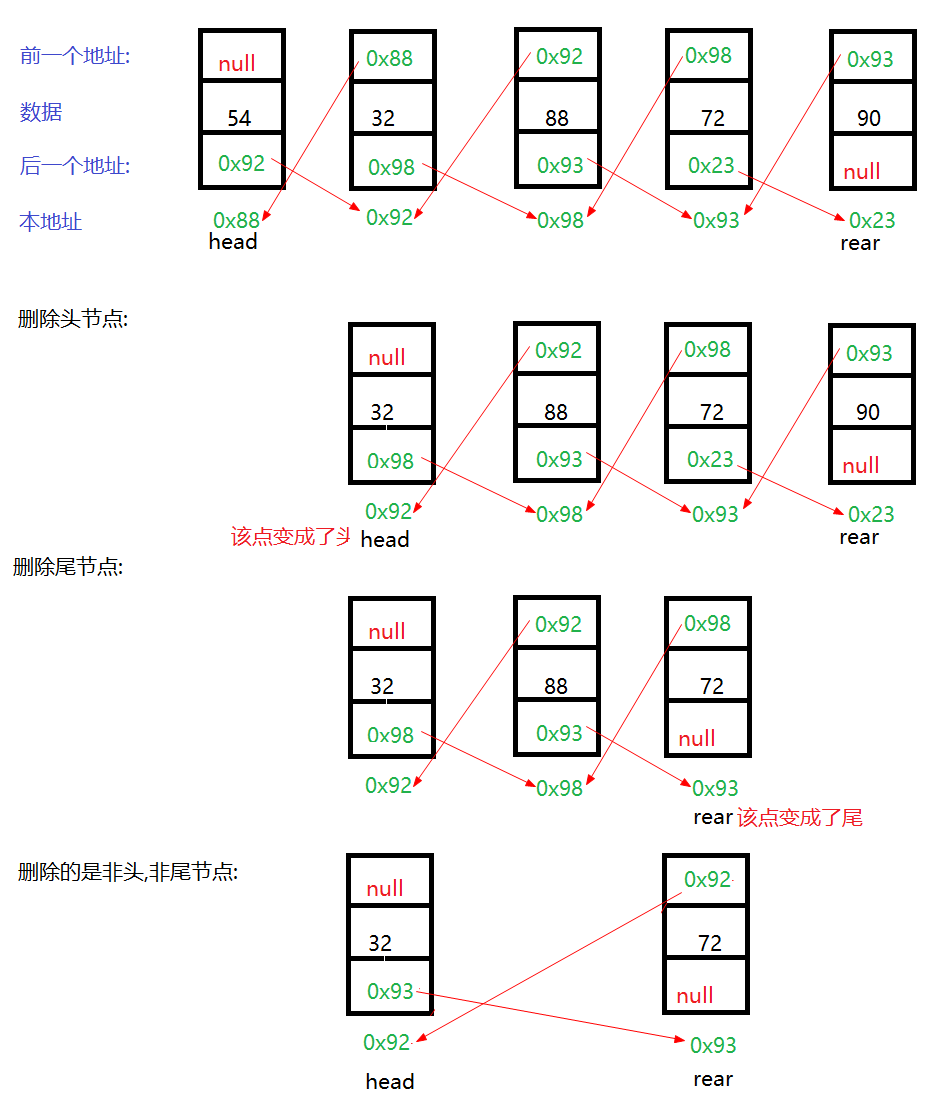
2. 确实找到一个有该数据的节点if(delete!=null),然后有4种情况如果删的是以下的
1.只有一个节点->既是头又是尾=>头尾都设空
2.是头结点=>新节点变头节点,新节点的pre变null
3.是尾节点=>新节点变尾节点,新节点的next变null
4.是其他
=>前一个节点的next=该节点的next
后一个节点的pre = 该节点的pre;删除节点过程图
三.修改数据update(Object oldData,Object newData)
1.找到data所在的节点find(oldData);
2.如果找到的节点不为空,就把data变成newData.四.容器中是否包含数据contains(Object data)
1.同理根据find(data)
2.返回 !note==null即可,不为空就是有包含五.可以改成增强泛型版,把所有的Object改成T,就可以增强为选择和泛型非泛型了
双向链表的迭代器
直接增强for循环或者迭代就报错,因为没实现接口iterable,该接口是所有集合的顶级接口.
1.实现iterable
2.重写iterator方法
1.返回new Iterator()
1.hasNext()方法
返回是否有数据 Note temp = head
temp==null;
2.next()方法
1.返回temp.data
2.temp指向下一个.temp = temp.next
3.remove()方法-不改变
3.ArrayList不给在增强for循环或者迭代器中做增删改,所以自己也可用设置,根据ArrayList的设计方法,同理,设置一个变量modCount.
1.在自己的链表类成员变量定义
2.在增删改的时候++;
3.在迭代器里面设置一个标记=modCount.(此时和前面的链表操作后的情况值的大小相同);
4.迭代过程中,如果再做了增删改的操作,就抛出异常.
写在next()方法的首位,if(标记改变),也抛出concurrentMotificationExaption(不能做增删改)经过了详细的过程讲解,下面给出详细代码
3.完整代码:


1 public class DoubleLink<T> implements Iterable<T> { 2 public class Note { 3 4 Note prev; 5 T data; 6 Note next; 7 } 8 9 Note head; 10 Note rear; 11 public int modCount; 12 13 // 默认增在后面,可相同的写个addLast(T data); 14 public void add(T data) { 15 Note note = new Note(); 16 // 加数据 17 note.data = data; 18 // 无数据 19 if (head == null) {// 等同head == null && rear == null,head没有那rear肯定没有 20 head = note; 21 rear = note; 22 } 23 // 有数据,加到后面,尾节点并变成新的节点 24 else { 25 note.prev = rear; 26 rear.next = note; 27 rear = note; 28 } 29 modCount++; 30 } 31 32 public void addFirst(T data) { 33 Note note = new Note(); 34 note.data = data; 35 if (head == null) { 36 head = note; 37 rear = note; 38 } else { 39 // 只改这里即可,note的前面变成null,next变成旧头,旧头的pre变成note,(新头变成了note,***比别把note变成新头要符合) 40 note.prev = null; 41 note.next = head; 42 head.prev = note; 43 head = note; 44 } 45 modCount++; 46 } 47 48 // 删 49 public void remove(T data) { 50 // 找到所在数据所在节点 51 Note delete = find(data); 52 // 如果有该节点 53 if (delete != null) { 54 // 1.只有一个节点(那么该节点的pre和next都是null),都置空 55 if (delete.prev == null && delete.next == null) {// 等同head==rear&&rear!=null; 56 head = null; 57 rear = null; 58 } 59 // 2.是头 60 else if (delete.prev == null) { 61 // 那么原本头结点的下一个的pre就变成null,头节点变成删除节点的后一个; 62 delete.next.prev = null; 63 head = delete.next;// 反过来写(delete.next=head)就不能给head赋值了,就会删除失效 64 } 65 // 3.是尾 66 else if (delete.next == null) { 67 // 尾巴的前一个的next变成null,尾巴变成新的尾巴 68 delete.prev.next = null; 69 rear = delete.prev;// 同理,不能反过来 70 } 71 // 4.是其他 72 else { 73 // 删除的前面的next指向删除的next 74 delete.prev.next = delete.next; 75 // 删除后面的pre = 删除的pre 76 delete.next.prev = delete.prev; 77 } 78 modCount++; 79 } 80 } 81 82 // 改 83 public void update(T oldData, T newData) { 84 Note note = find(oldData); 85 note.data = newData; 86 modCount++; 87 } 88 89 // 查 90 public boolean contains(T data) { 91 Note note = find(data); 92 return note != null; 93 } 94 95 // 大小 96 public int size() { 97 int count = 0; 98 Note temp = head; 99 while (temp != null) { 100 101 count++; 102 temp = temp.next; 103 } 104 return count; 105 } 106 107 // 获取位置 108 public T get(int index) { 109 int size = size();// 防止超出 110 if (index >= size) { 111 throw new IndexOutOfBoundsException("没有此角标"); 112 } 113 T data = null; 114 // 定义成头 115 Note temp = head; 116 117 if (temp != null) { 118 if (index == 0) { 119 data = temp.data; 120 } else { 121 for (int i = 0; i < index; i++) {// 1的时候是第下一个,2的时候是下一个的下一个; 122 data = temp.next.data; 123 } 124 } 125 } 126 return data; 127 } 128 129 @Override 130 public Iterator<T> iterator() { 131 return new Iterator<T>() { 132 Note temp = head; 133 int flag = modCount; 134 135 @Override 136 public boolean hasNext() {// 判断是否有值,即判空 137 return temp != null; 138 } 139 140 @Override 141 public T next() {// 返回具体数据 142 T data = temp.data; 143 temp = temp.next;// 关键:取值后变成下一个节点 144 // 发现迭代的过程中有改动 145 if (flag != modCount) { 146 throw new ConcurrentModificationException("迭代过程不能修改"); 147 } 148 return data; 149 } 150 151 @Override 152 public void remove() { 153 154 } 155 }; 156 } 157 158 /*--------------自定义堆栈,增加一个push,和poll尾部获取并移除--------------*/ 159 public void push(T data) { 160 add(data); 161 } 162 //获取并从尾部移除 163 public T poll() { 164 T data = null; 165 Note temp = rear;//从尾部拿; 166 if (temp != null) { 167 data = temp.data; 168 //移除 169 if (rear.prev != null) { 170 //前面有节点 171 rear.prev.next = null; 172 rear = rear.prev; 173 } else { 174 //前面没节点 175 rear = null; 176 head = null; 177 } 178 } else { 179 throw new EmptyStackException(); 180 } 181 return data; 182 } 183 private Note find(T data) { 184 Note temp = head; 185 while (temp != null) { 186 // System.out.println("data = " + data);//1234 187 // System.out.println("temp.data = " + temp.data);//1234 188 // System.out.println(1234 == 1234);//true 189 // System.out.println(temp.data == data);//false ,因为data是T泛型 190 // System.out.println(temp.data.equals(1234));//true 191 // System.out.println(temp.data.equals(data));//true 192 // 等于当前,返回当前 193 if (temp.data.equals(data) && temp.data.hashCode() == data.hashCode()) { 194 // 判断相同请用equals,发现用==有的数据居然不生效;最正规的方法是用equals+hashCode()==data.hashCode(); 195 return temp; 196 } else { 197 // 否则往下找,找不到可能为空,即没有下一个 198 temp = temp.next; 199 } 200 /* 201 * ==操作比较的是两个变量的值是否相等,对于引用型变量表示的是两个变量在堆中存储的地址是否相同,即栈中的内容是否相同。 equals操作表示的两个变量是否是对同一个对象的引用,即堆中的内容是否相同。 202 * 203 * ==比较的是2个对象的地址,而equals比较的是2个对象的内容。 显然,当equals为true时,==不一定为true; 204 */ 205 } 206 return temp; 207 } 208 209 @Override 210 public String toString() { 211 StringBuilder ms = new StringBuilder("["); 212 Note temp = head; 213 while (temp != null) { 214 if (temp != rear) { 215 ms.append(temp.data + ","); 216 } else { 217 ms.append(temp.data); 218 } 219 temp = temp.next; 220 } 221 return ms + "]"; 222 } 223 }
下面我们通过创建测试类来测试代码的各项功能
public class Test{
public static void main(String[] args) {
Demo07_DoubleLink<Integer> dl = new Demo07_DoubleLink();
/*--------------增后add--------------*/
dl.add(123);
dl.add(12345);
/*--------------增前addFirst--------------*/
dl.addFirst(77);
dl.addFirst(717);
System.out.println(dl);
/*--------------删remvove--------------*/
dl.remove(12345);
dl.remove(717);
System.out.println(dl);
/*--------------改update--------------*/
dl.update(77, 707);
System.out.println(dl);
/*--------------查contains--------------*/
System.out.println("contains 123 ? " + dl.contains(123));
/*--------------获取大小size--------------*/
int size = dl.size();
System.out.println("size = " + size);
/*--------------获取元素get--------------*/
int i0 = dl.get(1);
int i1 = dl.get(0);
// int i7 = dl.get(8);
System.out.println("get : " + i0);
System.out.println("get : " + i1);
/*--------------迭代+增强for循环--------------*/
// System.out.println("get : " + i7);
// 迭代
// for (Integer i : dl) {
// System.out.println(i);
// }
// Iterator<Integer> iterator = dl.iterator();
// while (iterator.hasNext()) {
// Integer data = iterator.next();
// if (data.equals(707)) {
// dl.remove(data);
// }
// System.out.println(data);
// }
/*--------------自定义堆栈--------------*/
System.out.println("----------------------自定义堆栈,并且自己加异常--------------------");
int poll = dl.poll();
System.out.println(poll);
System.out.println(dl);
System.out.println(dl.poll());
System.out.println(dl);
}
}打印结果:
--------------------往后面添加--------------------
[123,12345]
--------------------往前面增加--------------------
[717,77,123,12345]
--------------------移除方法----------------------
[77,123]
--------------------修改方法----------------------
[707,123]
--------------------判断是否包含方法---------------
contains 123 ? true
--------------------获取大小的方法-----------------
size = 2
--------------------获取元素----------------------
get : 123
get : 707
-------------------迭代和增强for循环--------------
-------------------自定义堆栈,并且自己加异常--------
123
[707]
707
[]总结
以上就是双链表的相关学习,大家只要记住一下几点即可:
1.节点的3个属性pre,data,next
2.头节点和尾节点head,rear
3.要完成迭代,需要让类继承Iterable,仿制迭代过程不可修改以上是关于双向链表的主要内容,如果未能解决你的问题,请参考以下文章