爬虫大作业
Posted 117李智濠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫大作业相关的知识,希望对你有一定的参考价值。
# -*- coding:utf-8 -*-
# 第三方库
import scrapy
from scrapy.spiders import Spider
from lxml import etree
import re
import jieba
from BoKeYuan.items import BokeyuanItem
class BlogYuanSpider(Spider):
name = \'blog_yuan\'
start_urls = [\'https://www.cnblogs.com/\']
extra = \'/#p{}\'
def start_requests(self):
yield scrapy.Request(self.start_urls[0], callback=self.parse)
@staticmethod
def get_num(response):
html = response.body
selector = etree.HTML(html)
page_num = int(selector.xpath(\'string(//a[@class="p_200 last"])\'))
return page_num
@staticmethod
def get_info(response):
html = response.body
item = BokeyuanItem()
selector = etree.HTML(html)
i = selector.xpath(\'string(//div[@class="blogpost-body"])\')
info = re.sub(\'[\\s+\\n\\t]\', \'\', i)
item[\'info\'] = info
item[\'url\'] = response.url
d = {}
text = \'\'
text += \' \'.join(jieba.lcut(item[\'info\']))
t = re.sub(\'[\\,\\\'\\:\\/\\)\\.\\;\\}\\(\\,\\{]\', \'\', text).split()
for v in t:
d[v] = item[\'info\'].count(v)
e = list(d.items())
e.sort(key=lambda x: x[1], reverse=True)
for k, v in enumerate(e):
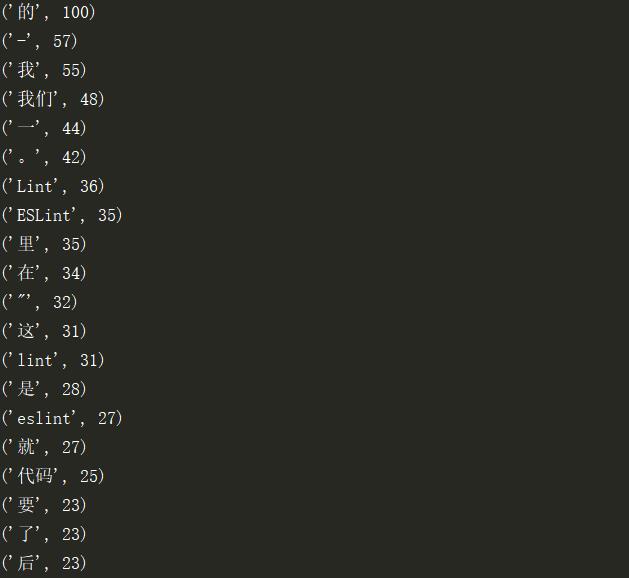
if k < 20:
print(v)
yield item
def get_page_url(self, response):
selector = etree.HTML(response.body)
page_url = selector.xpath(\'//a[@class="titlelnk"]/@href\')
for p in page_url:
yield scrapy.Request(url=p, callback=self.get_info)
def parse(self, response):
html = response.body
selector = etree.HTML(html)
page_url = selector.xpath(\'//a[@class="titlelnk"]/@href\')
for p in page_url:
yield scrapy.Request(url=p, callback=self.get_info)
page_num = self.get_num(response)
for n in range(2, page_num):
yield scrapy.Request(self.start_urls[0] + self.extra.format(n), callback=self.get_page_url)
通过设置入口url寻找首页中内容页的链接,并寻找首页中的最大页数,通过嵌套循环遍历页数和内容页链接,实现深度为3的深度爬取,通过yield生成item对象,同时输出词频统计后出现次数的top20
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
from scrapy.item import Item, Field
class BokeyuanItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
info = Field()
url = Field()
该函数定义scrapy中item的键以传值
# -*- coding: utf-8 -*- # Scrapy settings for BoKeYuan project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://doc.scrapy.org/en/latest/topics/settings.html # https://doc.scrapy.org/en/latest/topics/downloader-middleware.html # https://doc.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = \'BoKeYuan\' SPIDER_MODULES = [\'BoKeYuan.spiders\'] NEWSPIDER_MODULE = \'BoKeYuan.spiders\' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = \'BoKeYuan (+http://www.yourdomain.com)\' # Obey robots.txt rules ROBOTSTXT_OBEY = True # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: DEFAULT_REQUEST_HEADERS = { \'Accept\': \'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\', \'Accept-Language\': \'en\', } # Enable or disable spider middlewares # See https://doc.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # \'BoKeYuan.middlewares.BokeyuanSpiderMiddleware\': 543, #} # Enable or disable downloader middlewares # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # \'BoKeYuan.middlewares.BokeyuanDownloaderMiddleware\': 543, #} # Enable or disable extensions # See https://doc.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # \'scrapy.extensions.telnet.TelnetConsole\': None, #} # Configure item pipelines # See https://doc.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { \'BoKeYuan.pipelines.BokeyuanPipeline\': 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = \'httpcache\' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = \'scrapy.extensions.httpcache.FilesystemCacheStorage\'
该函数设置header头部信息及延迟时间的设置
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don\'t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html # 第三方库 import jieba import re import os from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator from scipy.misc import imread class BokeyuanPipeline(object): def __init__(self): pass def process_item(self, item, spider): text = \'\' name = item[\'url\'].split(\'/\')[-1].replace(\'.html\', \'\') p = os.path.abspath(__file__).replace(\'\\\\pipelines.py\', \'\') if os.path.exists(p+\'\\\\pic\'): path = p+\'\\\\pic\' else: path = os.mkdir(p+\'\\\\pic\') info = re.sub(\'[\\s+\\、\\(\\)\\(\\)\\{\\}\\_\\,\\.\\。\\“\\”\\;\\!\\?]\', \'\', item[\'info\']) text += \' \'.join(jieba.lcut(info)) backgroud_Image = imread(p + \'\\\\ju.PNG\') wc = WordCloud( width=500, height=500, margin=2, background_color=\'white\', # 设置背景颜色 mask=backgroud_Image, # 设置背景图片 font_path=\'C:\\Windows\\Fonts\\STZHONGS.TTF\', # 若是有中文的话,这句代码必须添加,不然会出现方框,不出现汉字 max_words=2000, # 设置最大现实的字数 stopwords=STOPWORDS, # 设置停用词 max_font_size=150, # 设置字体最大值 random_state=42 # 设置有多少种随机生成状态,即有多少种配色方案 ) wc.generate_from_text(text) wc.to_file(path + \'\\\\{}.jpg\'.format(name)) return item def close_spider(self, spider): pass
通过jieba库实现分词并输出词云

以上是关于爬虫大作业的主要内容,如果未能解决你的问题,请参考以下文章