ELF目标文件格式最前部ELF文件头(ELF Header),它包含了描述了整个文件的基本属性,比如ELF文件版本、目标机器型号、程序入口地址等。其中ELF文件与段有关的重要结构就是段表(Section Header Table)
ELF文件格式
- 可重定向文件:文件保存着代码和适当的数据,用来和其他的目标文件一起来创建一个可执行文件或者是一个共享目标文件。(目标文件或者静态库文件,即linux通常后缀为.a和.o的文件)
- 可执行文件:文件保存着一个用来执行的程序。(例如bash,gcc等)
- 共享目标文件:共享库。文件保存着代码和合适的数据,用来被下连接编辑器和动态链接器链接。(linux下后缀为.so的文件。)
另外的windows下为pe格式的文件;
ELF视图
首先,ELF文件格式提供了两种视图,分别是链接视图和执行视图。
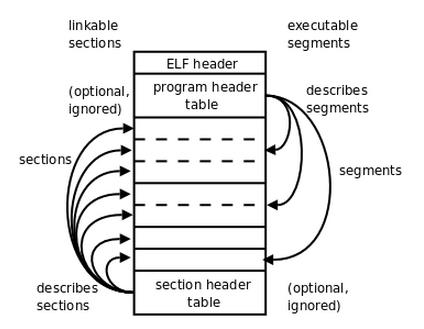
链接视图是以节(section)为单位,执行视图是以段(segment)为单位。链接视图就是在链接时用到的视图,而执行视图则是在执行时用到的视图。上图左侧的视角是从链接来看的,右侧的视角是执行来看的。总个文件可以分为四个部分:
- ELF header: 描述整个文件的组织。
- Program Header Table: 描述文件中的各种segments,用来告诉系统如何创建进程映像的。
- sections 或者 segments:segments是从运行的角度来描述elf文件,sections是从链接的角度来描述elf文件,也就是说,在链接阶段,我们可以忽略program header table来处理此文件,在运行阶段可以忽略section header table来处理此程序(所以很多加固手段删除了section header table)。从图中我们也可以看出, segments与sections是包含的关系,一个segment包含若干个section。
- Section Header Table: 包含了文件各个segction的属性信息,我们都将结合例子来解释。
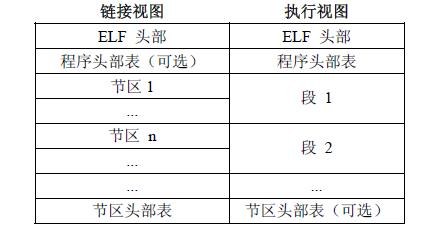
程序头部表(Program Header Table),如果存在的话,告诉系统如何创建进程映像。
节区头部表(Section Header Table)包含了描述文件节区的信息,比如大小、偏移等。
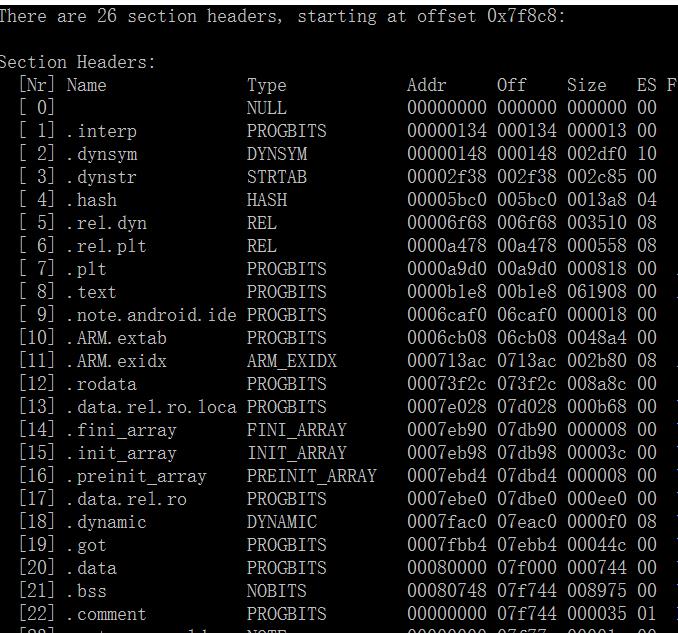
如下图,可以通过执行命令”readelf -S android_server”来查看该可执行文件中有哪些section。
通过执行命令readelf –segments android_server,可以查看该文件的执行视图。
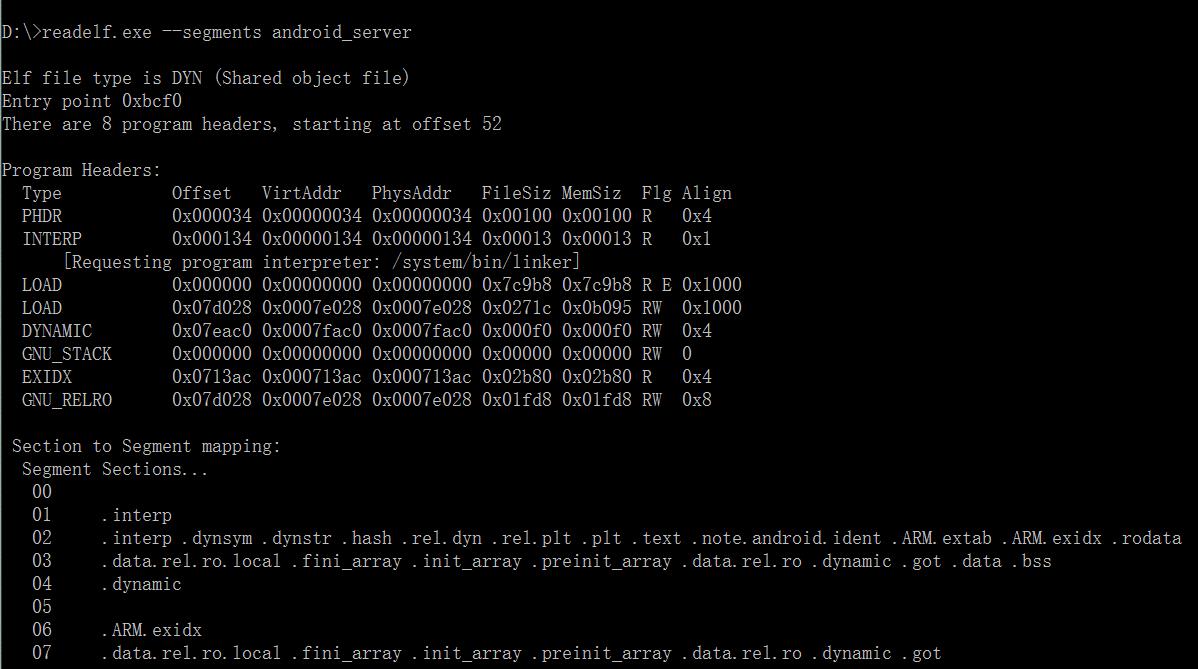
这验证了第一张图中所述,segment是section的一个集合,sections按照一定规则映射到segment。那么为什么需要区分两种不同视图?
当ELF文件被加载到内存中后,系统会将多个具有相同权限(flg值)section合并一个segment。操作系统往往以页为基本单位来管理内存分配,一般页的大小为4096B,即4KB的大小。同时,内存的权限管理的粒度也是以页为单位,页内的内存是具有同样的权限等属性,并且操作系统对内存的管理往往追求高效和高利用率这样的目标。ELF文件在被映射时,是以系统的页长度为单位的,那么每个section在映射时的长度都是系统页长度的整数倍,如果section的长度不是其整数倍,则导致多余部分也将占用一个页。而我们从上面的例子中知道,一个ELF文件具有很多的section,那么会导致内存浪费严重。这样可以减少页面内部的碎片,节省了空间,显著提高内存利用率。
文件头(ELF header)
我们可以使用readelf命令来详细查看elf文件,代码如清单3-2所示:

从上面输出的结构可以看到:ELF文件头定义了ELF魔数、文件机器字节长度、数据存储方式、版本、运行平台等。
ELF文件头结构及相关常数被定义在“/usr/include/elf.h”,因为ELF文件在各种平台下都通用,ELF文件有32位版本和64位版本的ELF文件的文件头内容是一样的,只不过有些成员的大小不一样。它的文件图也有两种版本:分别叫“Elf32_Ehdr”和“Elf64_Ehdr”。
typedef struct {
unsigned char e_ident[16];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
}Elf32_Ehdr;
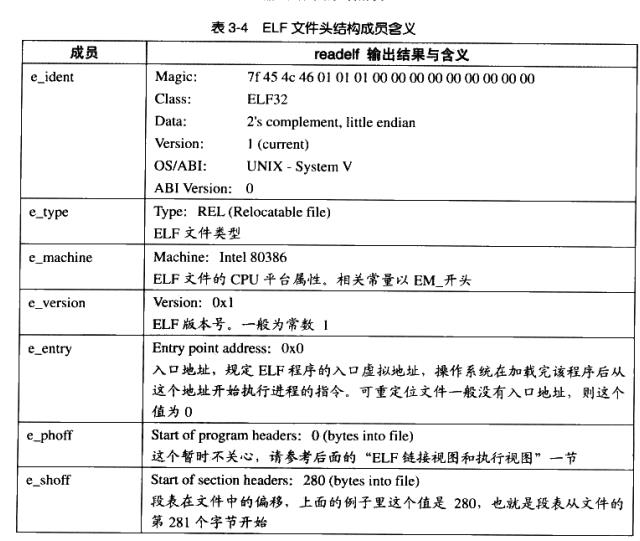
在ELF文件头中,我们需要重点关注以下几个字段:
- e_entry:程序入口地址
- e_ehsize:ELF Header结构大小
- e_phoff、e_phentsize、e_phnum:描述Program Header Table的偏移、大小、结构。
- e_shoff、e_shentsize、e_shnum:描述Section Header Table的偏移、大小、结构。
- e_shstrndx:这一项描述的是字符串表在Section Header Table中的索引,值25表示的是Section Header Table中第25项是字符串表(String Table)。
段表(Section Header Table)
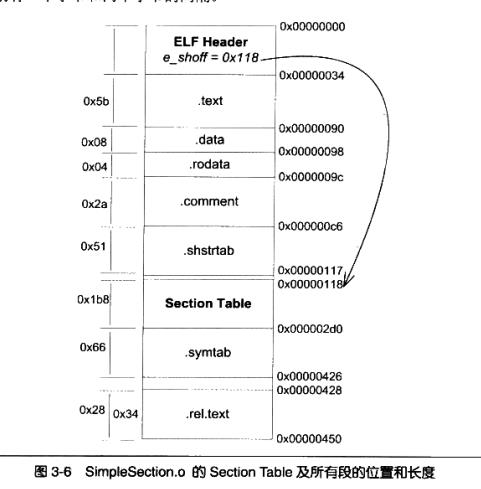
段表就是保存ELF文件中各种各样段的基本属性的结构。段表是ELF除了文件以外的最重要结构体,它描述了ELF的各个段的信息,ELF文件的段结构就是由段表决定的。编译器、链接器和装载器都是依靠段表来定位和访问各个段的属性的。段表在ELF文件中的位置由ELF文件头的“e_shoff”成员决定的,比如SimpleSection.o中,段表位于偏移0x118。
typedef struct {
Elf32_Word sh_name; //section的名字
Elf32_Word sh_type; //section类别
Elf32_Word sh_flags; //section在进程中执行的特性(读、写)
Elf32_Addr sh_addr; //在内存中开始的虚地址
Elf32_Off sh_offset; //此section在文件中的偏移
Elf32_Word sh_size;
Elf32_Word sh_link;
Elf32_Word sh_info;
Elf32_Word sh_addralign;
Elf32_Word sh_entsize;
}
表(Section)
符号表(.dynsym)
符号表包含用来定位、重定位程序中符号定义和引用的信息,简单的理解就是符号表记录了该文件中的所有符号,所谓的符号就是经过修饰了的函数名或者变量名,不同的编译器有不同的修饰规则。例如符号_ZL15global_static_a,就是由global_static_a变量名经过修饰而来。
符号表项的格式如下:
typedef struct {
Elf32_Word st_name; //符号表项名称。如果该值非0,则表示符号名的字
//符串表索引(offset),否则符号表项没有名称。
Elf32_Addr st_value; //符号的取值。依赖于具体的上下文,可能是一个绝对值、一个地址等等。
Elf32_Word st_size; //符号的尺寸大小。例如一个数据对象的大小是对象中包含的字节数。
unsigned char st_info; //符号的类型和绑定属性。
unsigned char st_other; //未定义。
Elf32_Half st_shndx; //每个符号表项都以和其他节区的关系的方式给出定义。
//此成员给出相关的节区头部表索引。
} Elf32_sym;
重定位表
重定位表在ELF文件中扮演很重要的角色,首先我们得理解重定位的概念,程序从代码到可执行文件这个过程中,要经历编译器,汇编器和链接器对代码的处理。然而编译器和汇编器通常为每个文件创建程序地址从0开始的目标代码,但是几乎没有计算机会允许从地址0加载你的程序。如果一个程序是由多个子程序组成的,那么所有的子程序必需要加载到互不重叠的地址上。重定位就是为程序不同部分分配加载地址,调整程序中的数据和代码以反映所分配地址的过程。简单的言之,则是将程序中的各个部分映射到合理的地址上来。
换句话来说,重定位是将符号引用与符号定义进行连接的过程。例如,当程序调用了一个函数时,相关的调用指令必须把控制传输到适当的目标执行地址。
具体来说,就是把符号的value进行重新定位。
字符串表(.dynstr)
ELF文件中用到了许多的字符串,比如段名,变量名等。因为字符串的长度往往是不定的,所以用固定的结构来表示它比较困难。一种常见的做法是把字符串集中起来存放到一个表,然后使用字符串在表中的偏移来引用字符串。
通常用这种方式,在ELF文件中引用字符串只需给一个数字下标即可,不用考虑字符串的长度问题。一般字符串标在ELF文件中国也以段的方式保存,常见的段名为“.strtab”或“.shstrtab”。这两个字符串分别表示为字符串表和段表字符串表。
只有分析ELF文件头,就可以得到段表和段表字符串表的位置,从而解析整个ELF文件。
装载elf文件步骤
首先在用户层面,shell进行会调用fork()系统调用创建一个新进程 - 新进程调用execve()系统调用执行制定的ELF文件 - 原来的shell进程继续返回等待刚才启动的新进程结束,然后继续等待用户输入。
execve()系统调用的原型如下: c int execve(const char *filename, char *const argv[], char *const envp[]); 它所对应的三个参数分别是程序文件名, 执行参数, 环境变量,通过对内核代码的分析,我们知道execve()系统调用的相应入口是sys_execve(),在sys_execve之后,内核会分别调用do_execve(),search_binary_handle(),load_elf_binary等等,其中do_execve()是最主要的函数,所以接下来我们主要对他来进行具体分析
do_execve
具体看一下下面链接:Linux进程启动过程分析do_execve(可执行程序的加载和运行)---Linux进程的管理与调度(十一)
int do_execve(struct filename *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp)
{
return do_execve_common(filename, argv, envp);
}
//do_execve_common
static int do_execve_common(struct filename *filename,
struct user_arg_ptr argv,
struct user_arg_ptr envp)
{
// 检查进程的数量限制
// 选择最小负载的CPU,以执行新程序
sched_exec();
// 填充 linux_binprm结构体
retval = prepare_binprm(bprm);
// 拷贝文件名、命令行参数、环境变量
retval = copy_strings_kernel(1, &bprm->filename, bprm);
retval = copy_strings(bprm->envc, envp, bprm);
retval = copy_strings(bprm->argc, argv, bprm);
// 调用里面的 search_binary_handler
retval = exec_binprm(bprm);
// exec执行成功
}
// exec_binprm
static int exec_binprm(struct linux_binprm *bprm)
{
// 扫描formats链表,根据不同的文本格式,选择不同的load函数
ret = search_binary_handler(bprm);
// ...
return ret;
}
- 如果想要了解elf文件格式,可以在命令行下面man elf,Linux手册中有参考.
- 在do_exec()中会调用do_execve_common(),这个函数的参数与do_exec()一模一样
- 在do_execve_common()中的sched_exec(),会选择一个负载最小的CPU来执行新进程,这里我们可以得知Linux内核中是做了负载均衡的.
- 在这段代码中间出现了变量bprm,这个是一个重要的结构体struct linux_binfmt,下面我贴出此结构体的具体定义:
/*
* This structure is used to hold the arguments that are used when loading binaries.
*/
// 内核中注释表明了这个结构体是用于保存载入二进制文件的参数.
struct linux_binprm {
char buf[BINPRM_BUF_SIZE];
#ifdef CONFIG_MMU
struct vm_area_struct *vma;
unsigned long vma_pages;
#else
//...
unsigned interp_flags;
unsigned interp_data;
unsigned long loader, exec;
};
- 在do_execve_common()中的searchbinaryhandler(),这个函数回去搜索和匹配合适的可执行文件装载处理过程,下面这个函数的精简代码:
int search_binary_handler(struct linux_binprm *bprm)
{
// 遍历formats链表
list_for_each_entry(fmt, &formats, lh) {
if (!try_module_get(fmt->module))
continue;
read_unlock(&binfmt_lock);
bprm->recursion_depth++;
// 应用每种格式的load_binary方法
retval = fmt->load_binary(bprm);
read_lock(&binfmt_lock);
put_binfmt(fmt);
bprm->recursion_depth--;
// ...
}
return retval;
}
- 这里需要说明的是,这里的fmt变量的类型是struct linux_binfmt *, 但是这一个类型与之前在do_execve_common()中的bprm是不一样的,具体定义如下:
- 这里的linux_binfmt对象包含了一个单链表,这个单链表中的第一个元素的地址存储在formats这个变量中
- list_for_each_entry依次应用load_binary的方法,同时我们可以看到这里会有递归调用,bprm会记录递归调用的深度
- 装载ELF可执行程序的load_binary的方法叫做load_elf_binary方法,下面会进行具体分析
/*
* This structure defines the functions that are used to load the binary formats that
* linux accepts.
*/
struct linux_binfmt {
struct list_head lh; //单链表表头
struct module *module;
int (*load_binary)(struct linux_binprm *);
int (*load_shlib)(struct file *);
int (*core_dump)(struct coredump_params *cprm);
unsigned long min_coredump; /* minimal dump size */
};
load_elf_binary()
static int load_elf_binary(struct linux_binprm *bprm)
{
// ....
struct pt_regs *regs = current_pt_regs(); // 获取当前进程的寄存器存储位置
// 获取elf前128个字节,作为魔数
loc->elf_ex = *((struct elfhdr *)bprm->buf);
// 检查魔数是否匹配
if (memcmp(loc->elf_ex.e_ident, ELFMAG, SELFMAG) != 0)
goto out;
// 如果既不是可执行文件也不是动态链接程序,就错误退出
if (loc->elf_ex.e_type != ET_EXEC && loc->elf_ex.e_type != ET_DYN)
//
// 读取所有的头部信息
// 读入程序的头部分
retval = kernel_read(bprm->file, loc->elf_ex.e_phoff,
(char *)elf_phdata, size);
// 遍历elf的程序头
for (i = 0; i < loc->elf_ex.e_phnum; i++) {
// 如果存在解释器头部
if (elf_ppnt->p_type == PT_INTERP) {
//
// 读入解释器名
retval = kernel_read(bprm->file, elf_ppnt->p_offset,
elf_interpreter,
elf_ppnt->p_filesz);
// 打开解释器文件
interpreter = open_exec(elf_interpreter);
// 读入解释器文件的头部
retval = kernel_read(interpreter, 0, bprm->buf,
BINPRM_BUF_SIZE);
// 获取解释器的头部
loc->interp_elf_ex = *((struct elfhdr *)bprm->buf);
break;
}
elf_ppnt++;
}
// 释放空间、删除信号、关闭带有CLOSE_ON_EXEC标志的文件
retval = flush_old_exec(bprm);
setup_new_exec(bprm);
// 为进程分配用户态堆栈,并塞入参数和环境变量
retval = setup_arg_pages(bprm, randomize_stack_top(STACK_TOP),
executable_stack);
current->mm->start_stack = bprm->p;
// 将elf文件映射进内存
for(i = 0, elf_ppnt = elf_phdata;
i < loc->elf_ex.e_phnum; i++, elf_ppnt++) {
if (unlikely (elf_brk > elf_bss)) {
unsigned long nbyte;
// 生成BSS
retval = set_brk(elf_bss + load_bias,
elf_brk + load_bias);
// ...
}
// 可执行程序
if (loc->elf_ex.e_type == ET_EXEC || load_addr_set) {
elf_flags |= MAP_FIXED;
} else if (loc->elf_ex.e_type == ET_DYN) { // 动态链接库
// ...
}
// 创建一个新线性区对可执行文件的数据段进行映射
error = elf_map(bprm->file, load_bias + vaddr, elf_ppnt,
elf_prot, elf_flags, 0);
}
}
// 加上偏移量
loc->elf_ex.e_entry += load_bias;
// ....
// 创建一个新的匿名线性区,来映射程序的bss段
retval = set_brk(elf_bss, elf_brk);
// 如果是动态链接
if (elf_interpreter) {
unsigned long interp_map_addr = 0;
// 调用一个装入动态链接程序的函数 此时elf_entry指向一个动态链接程序的入口
elf_entry = load_elf_interp(&loc->interp_elf_ex,
interpreter,
&interp_map_addr,
load_bias);
// ...
} else {
// elf_entry是可执行程序的入口
elf_entry = loc->elf_ex.e_entry;
// ....
}
// 修改保存在内核堆栈,但属于用户态的eip和esp
start_thread(regs, elf_entry, bprm->p);
retval = 0;
//
}
这段代码相当之长,我们做了相当大的精简,虽然对主要部分做了注释,但是为了方便我还是把主要过程阐述一边:
- 检查ELF的可执行文件的有效性,比如魔数,程序头表中段(segment)的数量
- 寻找动态链接的.interp段,设置动态链接路径
- 根据ELF可执行文件的程序头表的描述,对ELF文件进行映射,比如代码,数据,只读数据
- 初始化ELF进程环境
- 将系统调用的返回地址修改为ELF可执行程序的入口点,这个入口点取决于程序的连接方式,对于静态链接的程序其入口就是e_entry,而动态链接的程序其入口是动态链接器
- 最后调用start_thread,修改保存在内核堆栈,但属于用户态的eip和esp,该函数代码如下:
start_thread
void
start_thread(struct pt_regs *regs, unsigned long new_ip, unsigned long new_sp)
{
set_user_gs(regs, 0); // 将用户态的寄存器清空
regs->fs = 0;
regs->ds = __USER_DS;
regs->es = __USER_DS;
regs->ss = __USER_DS;
regs->cs = __USER_CS;
regs->ip = new_ip; // 新进程的运行位置- 动态链接程序的入口处
regs->sp = new_sp; // 用户态的栈顶
regs->flags = X86_EFLAGS_IF;
set_thread_flag(TIF_NOTIFY_RESUME);
}
总结
如你所见,执行程序的过程是一个十分复杂的过程,exec本质在于替换fork()后,根据制定的可执行文件对进程中的相应部分进行替换,最后根据连接方式的不同来设置好执行起始位置,然后开始执行进程.