R语言-ggplot初级
Posted 月上贺兰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言-ggplot初级相关的知识,希望对你有一定的参考价值。
ggplot2简介:
在2005年开始出现,吸取了基础绘图系统和lattice绘图系统的优点,并利用一个强大的模型来对其进行改进,这一模型基于之前所述的一系列准则,
能够创建任意类型的统计图形
1.导入包
library(maps)
library(maptools)
library(rgdal)
library(plyr)
library(MASS)
library(dplyr)
library(ggplot2)
案例1:钻石数据集
采用ggplot2自带的钻石数据集.
数据集变量简介
## 主要变量 ## price 价格 ## color 颜色 ## carat 重量 ## cut 切工
1.1 使用qplot进行简单的快速作图
set.seed(123) # 从整个数据集取出100行进行分析 dsmall <- diamonds[sample(nrow(diamonds), 100), ] dim(dsmall) # 1.1.1根据x和y和数据集自动作图 qplot(carat, price, data = diamonds) # 1.1.2根据log x和log y和数据集,自动作图 qplot(log(carat), log(price), data = diamonds) # 1.1.3根据x和y和数据集按照color进行分类,自动作图 qplot(carat, price, data = dsmall, colour = color) # 1.1.4根据x和y和数据集按照shape进行分类,自动作图 qplot(carat, price, data = dsmall, shape = cut) # 1.1.5根据x和y和数据集,指定作图的类型,自动作图 qplot(carat, price, data = dsmall, geom = c("point", "smooth")) # 1.1.6根据x和y和数据集,做箱线图 qplot(cut, price / carat, data = diamonds, geom = "boxplot") # 1.1.7根据x和y和数据集,做条形图 qplot(color, data = diamonds, geom = "bar") # 1.1.8根据x和y和数据集,做直方图 qplot(carat, data = diamonds, geom = "histogram") # 1.1.9根据x和y和数据集,做核密度图 qplot(carat, data = diamonds, geom = "density")
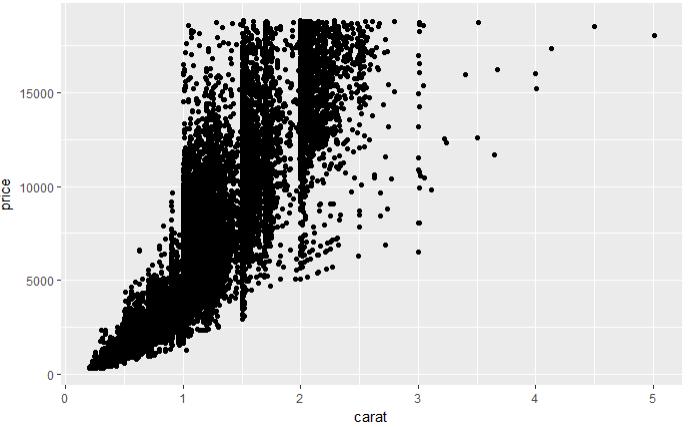
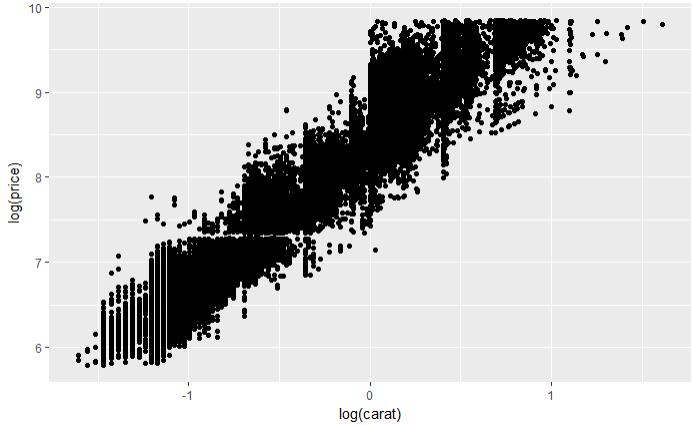
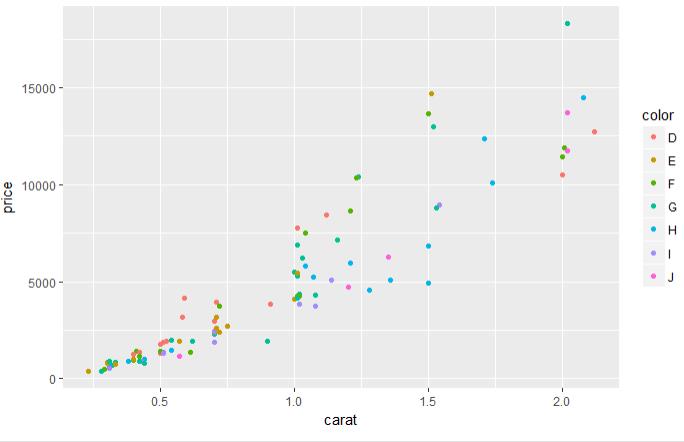
图 1.1.1 图 1.1.2 图 1.1.3
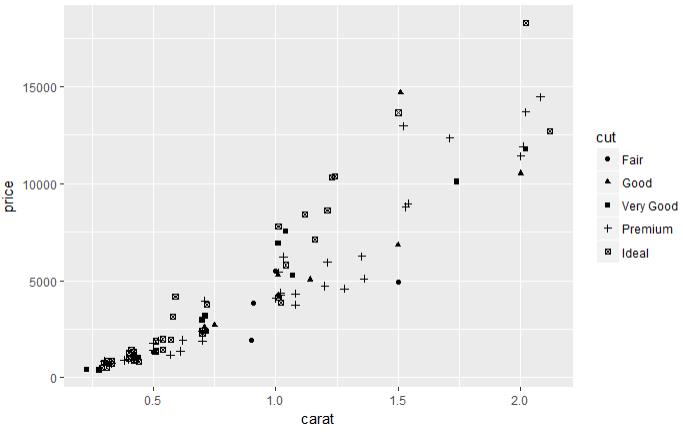
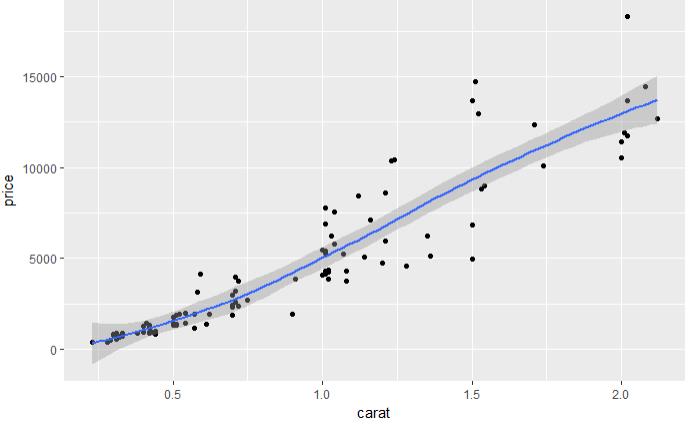
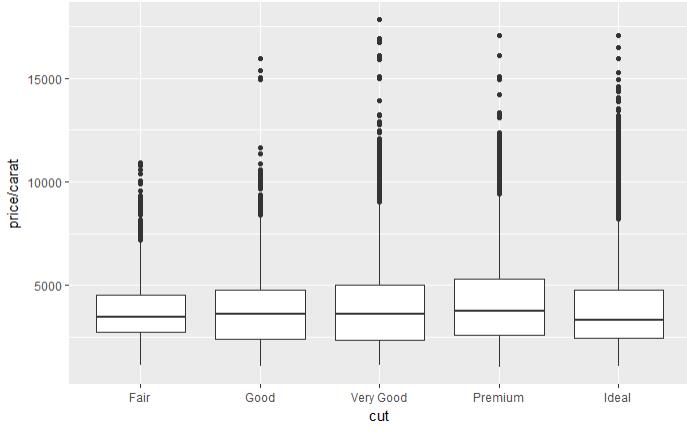
图 1.1.4 图 1.1.5 图 1.1.6
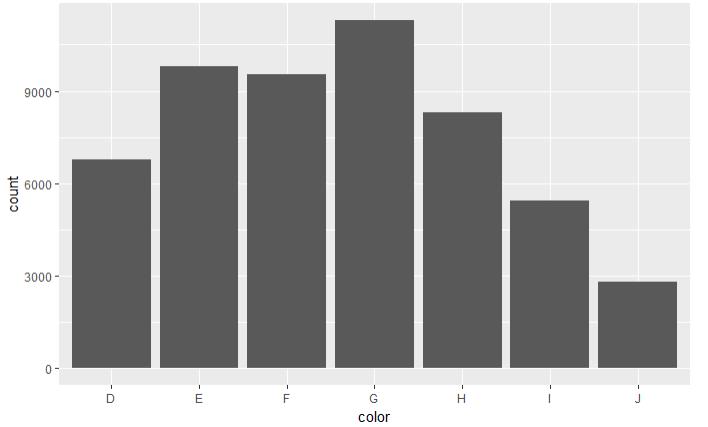
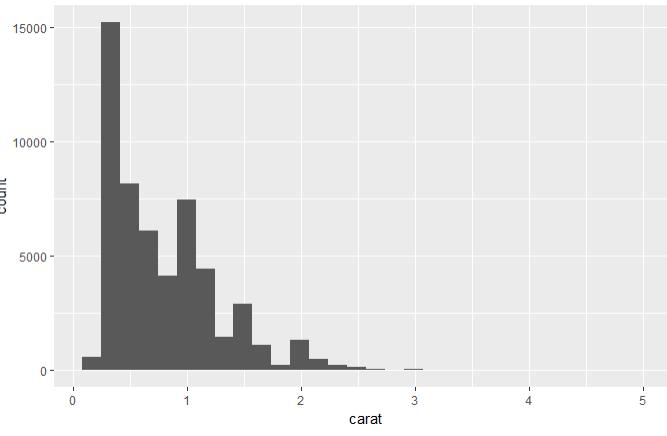
图 1.1.7 图 1.1.8 图1.1.9
1.2使用qplot进行分组
# 1.1.10 使用facets对需要分组的字段进行分组 qplot(carat, data = diamonds, facets = color ~ ., geom = "histogram", binwidth = 0.1, xlim = c(0, 3)) # 1.1.11 给图形添加信息 qplot( carat, price, data = dsmall, xlab = "Price ($)", ylab = "Weight (carats)", main = "Price-weight relationship" )
图 1.1.10 按照不同的颜色对重量进行统计 图 1.1.11 添加和标题,X轴,Y轴解释
案例2:地图(不包含中国)
ggplot是基于图层进行作图的
df <- data.frame(x = rnorm(2000), y = rnorm(2000)) norm <- ggplot(df, aes(x, y)) norm # 图层1 norm + geom_point() # 图层2
# 改变点的大小和形状 norm + geom_point(shape = 1) norm + geom_point(shape = ".")
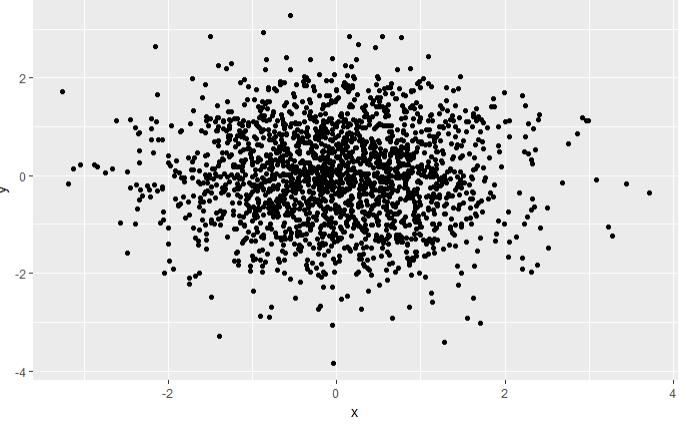
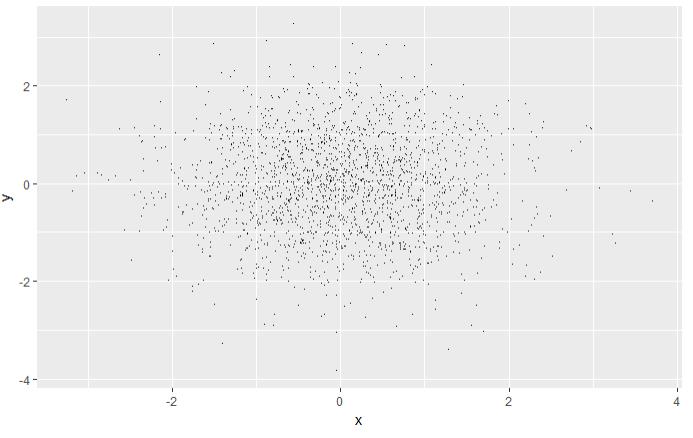
图层 1 图层 2 图层3
采用ggplot2自带的美国城市数据集us.city
数据集变量简介
## name 城市名称 ## country.etc 简称 ## pop 人口数量 ## lat 纬度 ## lon 经度 ## capital 是否是首府
2.1找出美国人口大于500000的城市
big_cities <- subset(us.cities, pop > 500000) qplot(long, lat, data = big_cities) + borders("state", size = 0.5)
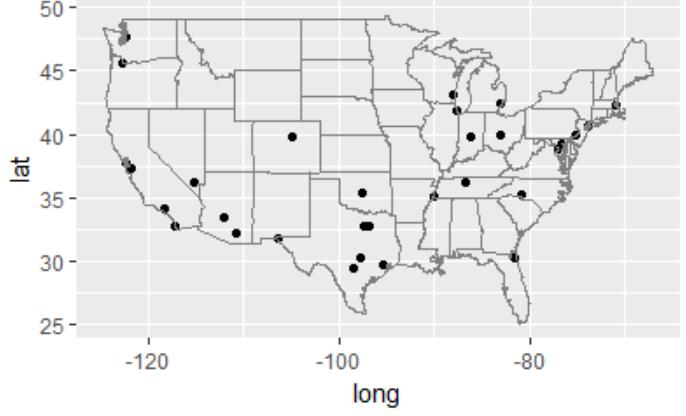
图 2.1
2.2 做出德州地图
tx_cities <- subset(us.cities, country.etc == "TX") # 在使用map做地图的时候,记住x和y一定指的是经纬度 ggplot(tx_cities, aes(long, lat)) + borders("county", "texas", colour = "grey70") + geom_point(colour = alpha("black", 0.5))
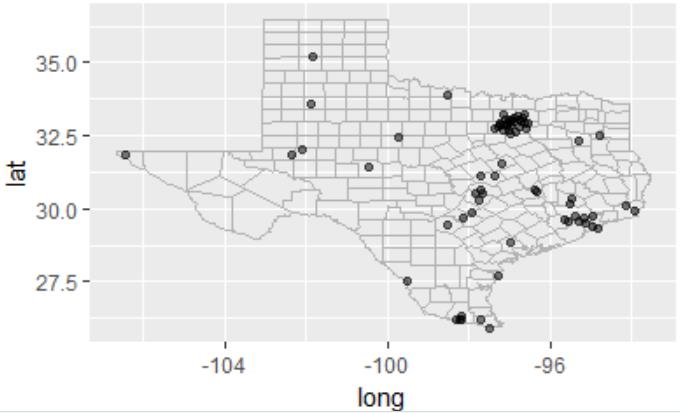
图 2.2 德州地图
2.3结合USAssert来做出美国各个州的犯罪率
# 从map中获取洲数据 states <- map_data("state") # 获取犯罪数据 arrests <- USArrests # 将犯罪的数据列名转换为小写 names(arrests) <- tolower(names(arrests)) # 获取根据行名获取区域数据 arrests$region <- tolower(rownames(USArrests)) # 将两个数据集进行合并 choro <- merge(states, arrests, by = "region") # 按犯罪率升序排列 choro <- choro[order(choro$order), ] # 2.3.1 犯罪率的分布 qplot(long, lat, data = choro, group = group,fill = assault, geom = "polygon") # 2.3.2 谋杀率的分布 qplot(long, lat, data = choro, group = group, fill = assault / murder, geom = "polygon")
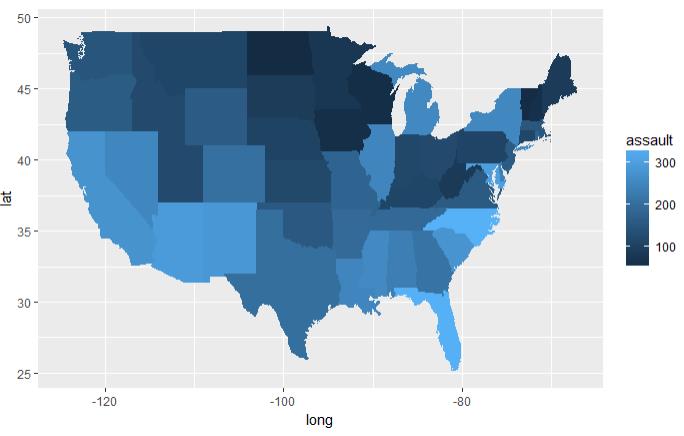
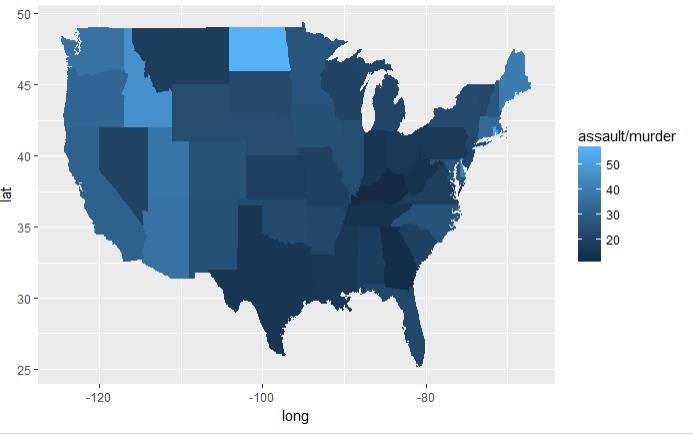
图 2.3.1 结论:越往东北犯罪率越低 图 2.3.2 结论:越往西北谋杀率越低
案例3:中国地图
3.1 做出各个省份人口的数量
# 载入中国地图数据集
china=readShapePoly(\'E:\\\\Udacity\\\\Data Analysis High\\\\R\\\\R_Study\\\\第一天数据\\\\bou2_4p.shp\')
# 获取数据 x<-china@data
# 转换为datafarme xs<-data.frame(x,id=seq(0:924)-1)
# 将china转换为datafarme shapefile_df <- fortify(china)
# 组合成完整的dataframe
china_mapdata<-join(shapefile_df, xs, type = "full")
# 省份名称
NAME<-c("北京市","天津市","河北省","山西省","内蒙古自治区","辽宁省","吉林省",
"黑龙江省","上海市","江苏省","浙江省","安徽省","福建省", "江西省","山东省","河南省",
"湖北省", "湖南省","广东省", "广西壮族自治区","海南省", "重庆市","四川省", "贵州省",
"云南省","西藏自治区","陕西省","甘肃省","青海省","宁夏回族自治区","新疆维吾尔自治区",
"台湾省","香港特别行政区")
# 各个省份的人口
pop<-c(7355291,3963604,20813492,10654162,8470472,15334912,9162183,13192935,8893483,25635291,20060115,19322432,11971873,11847841,30794664,26404973,
17253385,19029894,32222752,13467663,2451819,10272559,26383458,10745630,
12695396,689521,11084516,7113833,1586635,1945064,6902850,23193638,7026400)
# 组合成完整的d人口-省份的dataframe
pop<-data.frame(NAME,pop)
# 和中国的地图信息相结合,组合成datdaframe
china_pop<-join(china_mapdata, pop, type = "full")
ggplot(china_pop, aes(x = long, y = lat, group = group,fill=pop))+
geom_polygon( )+
geom_path(colour = "grey40")
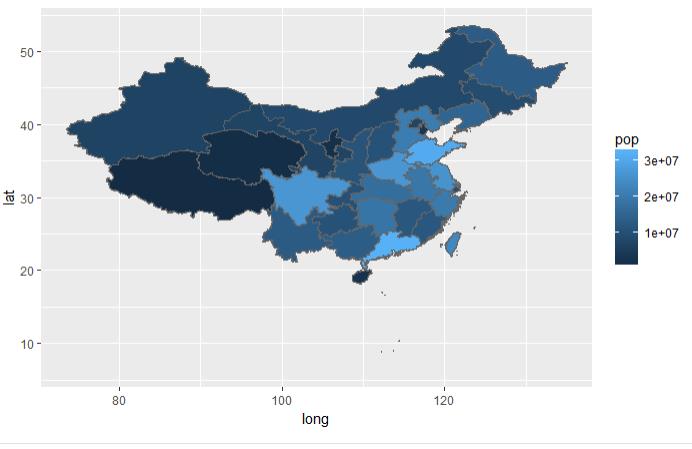
图3.1 结论颜色越浅的的省份人口越多
3.2 做出上海市的地图
# 使用subset来取出上海市的信息
SH<-subset(china_mapdata,NAME=="上海市") ggplot(SH, aes(x = long, y = lat, group = group,fill=NAME))+ geom_polygon(fill="lightblue" )+ geom_path(colour = "grey40")+ ggtitle("中华人民共和国上海市")+ annotate("text",x=121.4,y=31.15,label="上海市")
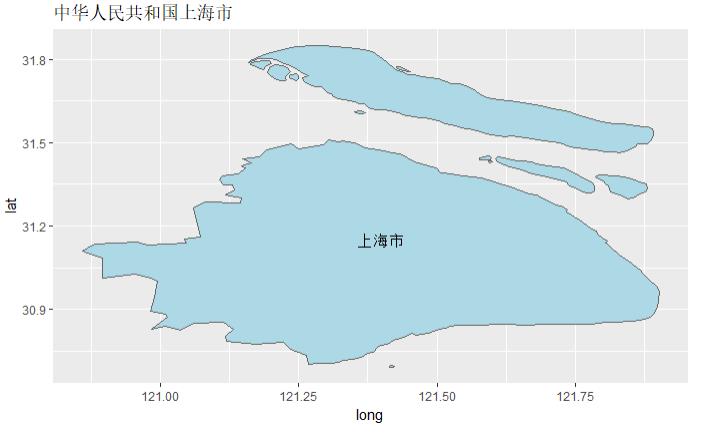
图 3.2
案例4:时间数据
采用ggplot2自带的economics数据集
数据集变量简介
## date 时间 ## pop 人口 ## uempmed 失业率 ## unemploy 失业人数
4.1 通过时间查看失业率
ggplot(aes(x=date,y=uempmed),data=economics)+
geom_line()
图4.1 图层1
4.2查看不同政党执政时期的失业率
# 获取失业率的折线图 图层1 (unemp <- qplot(date, unemploy, data=economics, geom="line",xlab = "", ylab = "No. unemployed (1000s)")) # 由于是1970年开始,所以去掉前三行,从尼克松开始统计 presidential1 <- presidential[-(1:3), ] #确定x和y的边界 yrng <- range(economics$unemploy) xrng <- range(economics$date) # 图层2 unemp + geom_vline(aes(xintercept = start), data = presidential) # 图层3 unemp + geom_rect(aes(NULL, NULL, xmin = start, xmax = end, fill = party), ymin = yrng[1], ymax = yrng[2], data = presidential1) + scale_fill_manual(values = alpha(c("blue", "red"), 0.2))
4.2 图层2 图层 3
5.作图其他设置
5.1 叠加多个图形
# 美国5大湖之一的休伦湖数据集
huron <- data.frame(year = 1875:1972, level = LakeHuron) ggplot(huron, aes(year)) + geom_line(aes(y = level - 5), colour = "blue") + geom_line(aes(y = level ), colour = "black") + geom_line(aes(y = level + 5), colour = "red")
图5.1
5.2 颜色设置
# 使用mtcars数据集
# 制定乐填充色red和边框色black ggplot(birthwt, aes(x=bwt)) + geom_histogram(fill="red", colour="black") # 将cyl转变为因子 mtcars$cyl <- factor(mtcars$cyl) # 对不同的ctl进行绘图 ggplot(mtcars, aes(x=wt, y=mpg, colour=cyl)) + geom_point()
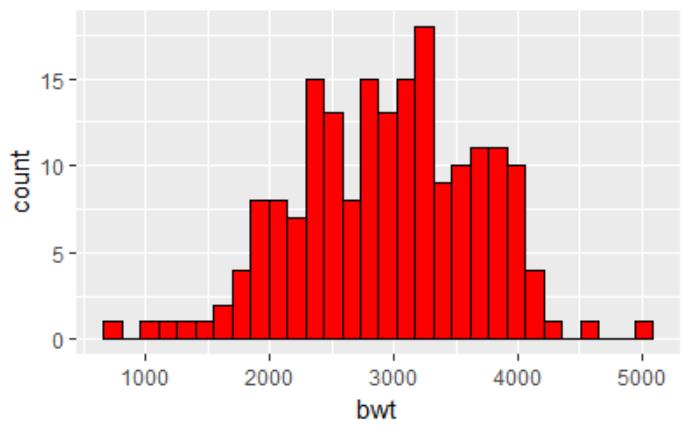
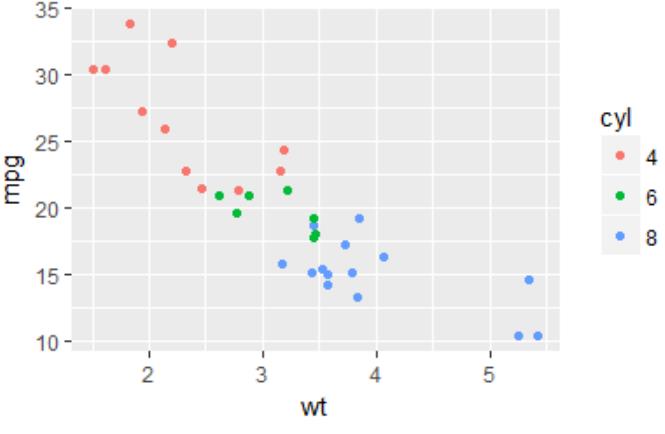
图 5.2.1 图 5.2.2
5.3 图例
# 采用的是植物数据集 p <- ggplot(PlantGrowth, aes(x=group, y=weight, fill=group)) + geom_boxplot() # 5.3.1 默认的图例放在右边
p # 5.3.2 不使用图例 p + guides(fill=FALSE)
# 5.3.3 将图例放在顶部 p + theme(legend.position="top")
# 5.3.4 指定图例的位置 p + theme(legend.position=c(1,0), legend.justification=c(1,0))
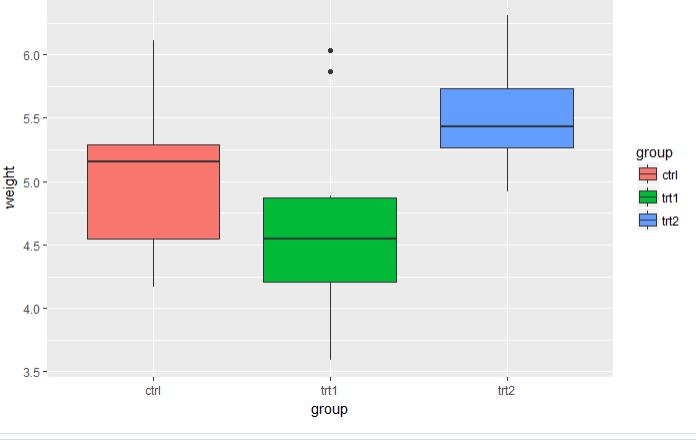
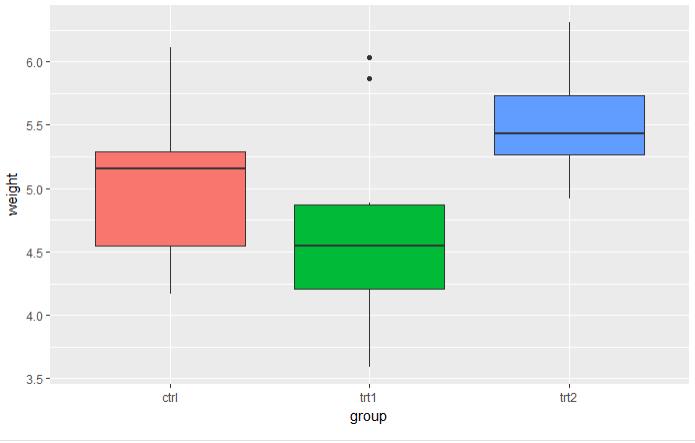
图 5.3.1 图 5.3.2
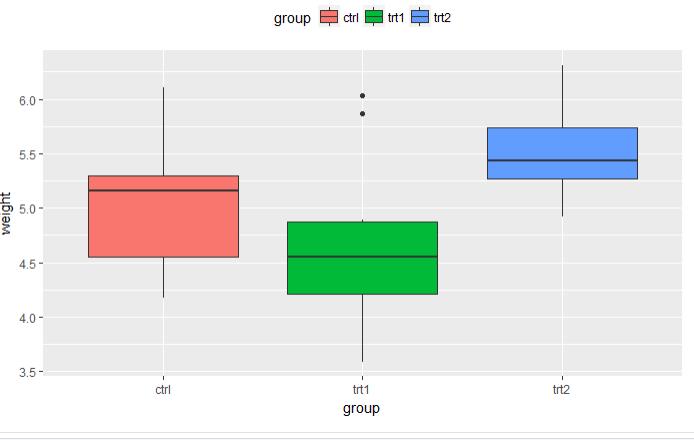
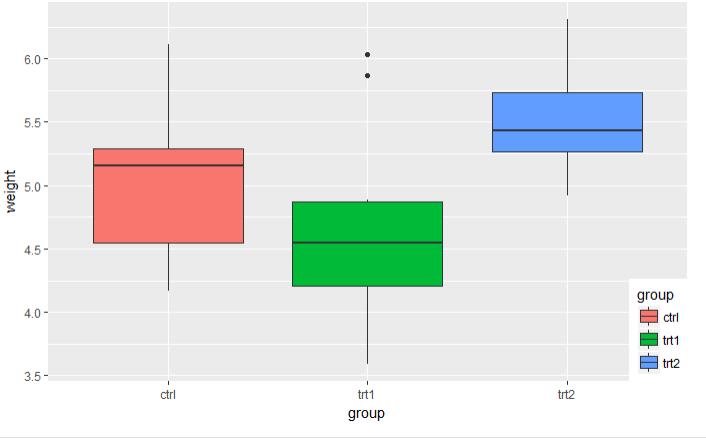
图 5.3.3 图 5.4.4
github:https://github.com/Mounment/R-Project
以上是关于R语言-ggplot初级的主要内容,如果未能解决你的问题,请参考以下文章