glusterfs4.0.1 mempool 分析笔记
Posted robinfox
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了glusterfs4.0.1 mempool 分析笔记相关的知识,希望对你有一定的参考价值。
关于3.2.5版本分析,详见《GlusterFS之内存池(mem-pool)实现原理及代码详解》
此4.0.1版本内存池与版本3中的描述变化有点大,总的原理还是类似LINUX中的SLAB算法,定义一系列大小类型的池子,
1. 一共定义了15个池,每个池子大小都是依次幂级数增长的
#define POOL_SMALLEST 7 /* i.e. 128 2的7次幂 */ #define POOL_LARGEST 20 /* i.e. 2048576 2的20次幂 */ #define NPOOLS (POOL_LARGEST - POOL_SMALLEST + 1)
结构体 mem_pool_shared 用来记录每一类池子大小,同时用来记录各种操作的次数,用来检测使用情况以及趋势分析
struct mem_pool_shared
{
unsigned int power_of_two; // 每个池子大小定义
gf_atomic_t allocs_hot;
gf_atomic_t allocs_cold;
gf_atomic_t allocs_stdc;
gf_atomic_t frees_to_list;
};
2. 又定义了一组全局变量:
// 这里定义了内存池的全局变量 static pthread_key_t pool_key; // 用来线程本地存储 per_thread_pool_list_t *pool_list,见 mem_get_pool_list ,初始化见mem_pools_init_early static pthread_mutex_t pool_lock; static struct list_head pool_threads; // 用来把每个线程的pool_list 链接在一起,见 mem_get_pool_list (void) static pthread_mutex_t pool_free_lock; static struct list_head pool_free_threads; //
static struct mem_pool_shared pools[NPOOLS]; // 总共15个池子类型 static size_t pool_list_size; // 线程上本地存储一个队列,队列里面是15个池子类型的链表头,mem_pools_preinit (void) 里给出了计算方法
每个线程使用本地存储方式保存一个链表,链表是开辟的整块内存,内存头是struct per_thread_pool_list 结构,
后面跟着15个 struct per_thread_pool结构,每个结构都有一个热链表和一个冷链表,分别用来保存正在使用的池链表和暂时空闲的池链表。
在函数per_thread_pool_list_t * mem_get_pool_list (void) 中是分配线程池链表头的初始化代码。
逻辑关系如图:
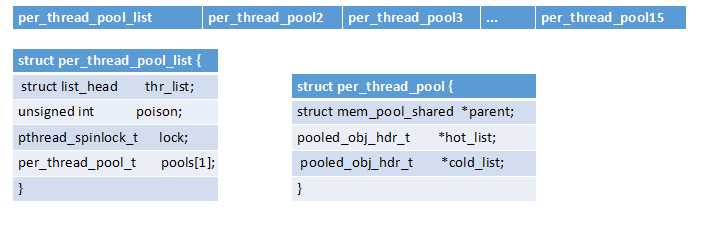
3. 在struct per_thread_pool链表中挂着很多内存块,每个内存块都是一个小的分配池。每个内存块都用 结构体 struct pooled_obj_hdr 来描述头部。
struct pooled_obj_hdr {
unsigned long magic; // 标记内存块幻数,固定为:#define GF_MEM_HEADER_MAGIC 0xCAFEBABE
struct pooled_obj_hdr *next; // 下一个
struct per_thread_pool_list *pool_list; // 反向引用,指向线程池链表
unsigned int power_of_two; // 块大小
/* track the pool that was used to request this object */
struct mem_pool *pool; //
}
函数 mem_get (struct mem_pool *mem_pool) 是用来获取内存块的函数。
4. struct mem_pool的用法与之前的版本有很大的不同。这个结构体,仅仅用来保存某个类型大小线程池的基本信息,并不实际存储内存块链表。
个人分析如下:之前的版本使用了一个大的结构体管理,但是多个线程竞争影响效率,所以4.0版本每建立一个struct mem_pool 对象就按照大小与 全局 pools[NPOOLS] 相对应,并且将池内存块链表的根使用线程本地存储方式保存。这样每个线程不存在竞争关系。
1)每个需要内存池的地方都是使用宏 mem_pool_new(type,count) 生成。
2)当需要使用内存的时候,调用mem_get0 (struct mem_pool *mem_pool) 。此函数内部再次调用 mem_get(mem_pool) ,该函数内部流程如下:
per_thread_pool_list_t *pool_list = mem_get_pool_list ();
之后从pool_list列表中找到指定大小的per_thread_pool_t *pt_pool,
再根据pooled_obj_hdr_t * retval = mem_get_from_pool (pt_pool); 初始化内存块 前面部分作为 pooled_obj_hdr_t 结构,函数返回结构体后面部分的内存块。
3)释放内存块回链表中:mem_put (void *ptr)
根据ptr指针前移获得 hdr = ((pooled_obj_hdr_t *)ptr) - 1; 检查内存块幻数,并把幻数改为GF_MEM_INVALID_MAGIC 0xDEADC0DE,
之后将内存块放回线程本地存储的对应类型链表头中“hot_list”。
以上是关于glusterfs4.0.1 mempool 分析笔记的主要内容,如果未能解决你的问题,请参考以下文章
DPDK — MEMPOOL(librte_mempool,Memory Pool Manager,内存池管理组件)
DPDK — MEMPOOL(librte_mempool,Memory Pool Manager,内存池管理组件)