day21&22&23:线程进程协程
Posted john221100
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day21&22&23:线程进程协程相关的知识,希望对你有一定的参考价值。
1、程序工作原理
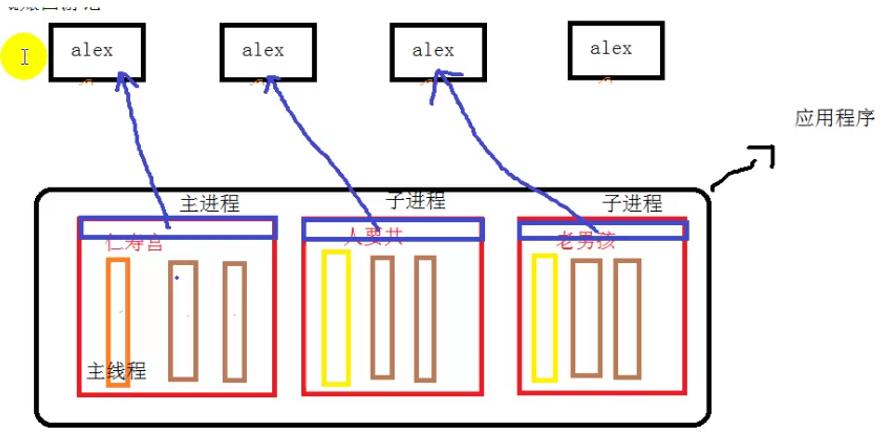
进程的限制:每一个时刻只能有一个线程来工作。
多进程的优点:同时利用多个cpu,能够同时进行多个操作。缺点:对内存消耗比较高
当进程数多于cpu数量的时候会导致不能被调用,进程不是越多越好,cpu与进程数量相等最好
线程:java和C# 对于一个进程里面的多个线程,cpu都在同一个时刻能使用。py同一时刻只能调用一个。
so:对于型的应用,py效率较java C#低。
多线程优点:共享进程的内存,可以创造并发操作。缺点:抢占资源,
多线程得时候系统在调用的时候需要记录请求上下文的信息,请求上下文的切换 这个过程非常耗时。因此 线程不是越多越好,具体案例具体分析。
在计算机中,执行任务的最小单元就是线程
IO操作不利用CPU,IO密集型操作适合多线程,对于计算密集型适合多进程
GIL:全局解释器锁,PY特有它会在每个进程上加个锁
系统存在进程和线程的目的是为了提高效率
1.1、单进程单线程
1.2、自定义线程:
主进程
主线程
子线程
2、线程锁 threading.RLock和threading.Lock
多线程修改一个数据得时候可能会造成咱数据。建议使用rlock
3、线程时间:threading.Event: 通知
当有进程间的通讯的情况下这个才有应用场景。汽车类比线程,Event.wait()红灯,Event.set()绿灯,Event.clear():使红灯变绿
even是线程间的通讯机制。Event.wait([timeout]):赌赛线程,知道event对象内部标示位被设置为True或超时时间。Event.set():将标识位设为True。Event.clear():标识位设为False。Event.isSet():判断标识位是否为True。
4、queue模块:生产者-消费者模型


#!/usr/bin/env python # -*- coding:utf-8 -*- import queue import threading # import queue # q = queue.Queue(maxsize=0) # 构造一个先进显出队列,maxsize指定队列长度,为0 时,表示队列长度无限制。 # # q.join() # 等到队列为空的时候,在执行别的操作 # q.qsize() # 返回队列的大小 (不可靠) # q.empty() # 当队列为空的时候,返回True 否则返回False (不可靠) # q.full() # 当队列满的时候,返回True,否则返回False (不可靠) # q.put(item, block=True, timeout=None) # 将item放入Queue尾部,item必须存在,可以参数block默认为True,表示当队列满时,会等待队列给出可用位置, # # 为False时为非阻塞,此时如果队列已满,会引发queue.Full 异常。 可选参数timeout,表示 会阻塞设置的时间,过后, # # 如果队列无法给出放入item的位置,则引发 queue.Full 异常 # q.get(block=True, timeout=None) # 移除并返回队列头部的一个值,可选参数block默认为True,表示获取值的时候,如果队列为空,则阻塞,为False时,不阻塞, # # 若此时队列为空,则引发 queue.Empty异常。 可选参数timeout,表示会阻塞设置的时候,过后,如果队列为空,则引发Empty异常。 # q.put_nowait(item) # 等效于 put(item,block=False) # q.get_nowait() # 等效于 get(item,block=False) message = queue.Queue(10) def producer(i): print("put:",i) # while True: message.put(i) def consumer(i): # while True: msg = message.get() print(msg) for i in range(12): t = threading.Thread(target=producer, args=(i,)) t.start() for i in range(10): t = threading.Thread(target=consumer, args=(i,)) t.start() qs = message.qsize() print("当前消息队列的长度为:%d"%(qs)) print("当前消息队列的长度为:",qs)
join()方法主线程等待,最多等待时间可以hi设置,eg:t.join(2)
import threading def f0(): pass def f1(a1,a2): time.sleep(10) f0() t = threading.Thread(target=f1,args(111,222,)) t.setDaemon(True) #默认false 主线程将等待执行完成后结束,设置为true后主线程将不在等待 t.start() t = threading.Thread(target=f1,args(111,222,)) t.start() t = threading.Thread(target=f1,args(111,222,)) t.start() t = threading.Thread(target=f1,args(111,222,)) t.start()
5、进程 :multiprocess是py进程模块
进程之间默认是隔离得,线程的资源默认是共享的
两个进程共享数据需要使用特殊得对象: array:其他语音 或manager.dict()
进程不是,越多越好,建议使用线程池来控制。
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Pool import time def myFun(i): time.sleep(2) return i+100 def end_call(arg): print("end_call",arg) # print(p.map(myFun,range(10))) if __name__ == "__main__": p = Pool(5) for i in range(10): p.apply_async(func=myFun,args=(i,),callback=end_call) print("end") p.close() p.join()
#!/usr/bin/env python # -*- coding:utf-8 -*- from multiprocessing import Pool import time def f1(a): time.sleep(1) print(a) return 1000 def f2(arg): print(arg) if __name__ =="__main__": pool = Pool(5) for i in range(50): pool.apply_async(func=f1, args=(i,),callback=f2) # pool.apply(func=f1, args=(i,)) print(\'<<=================>>\') pool.close() pool.join()
6、线程池py没有提供,我们需要自己编写
简单线程池示例:
#!/usr/bin/env python # -*- coding:utf-8 -*- import queue import threading import time class ThreadPool(object): def __init__(self, max_num=20): self.queue = queue.Queue(max_num) for i in range(max_num): self.queue.put(threading.Thread) def get_thread(self): return self.queue.get() def add_thread(self): self.queue.put(threading.Thread) def func(pool,a1): time.sleep(2) print(a1) pool.add_thread() p = ThreadPool(10) for i in range(100): #获得类 thread = p.get_thread() #对象 = 类() # t = thread(target=func,args=(p,i,)) t.start() """ pool = ThreadPool(10) def func(arg, p): print arg import time time.sleep(2) p.add_thread() for i in xrange(30): thread = pool.get_thread() t = thread(target=func, args=(i, pool)) t.start() """ # p = ThreadPool() # ret = p.get_thread() # # t = ret(target=func,) # t.start()
复杂的线城池示例:
#!/usr/bin/env python # -*- coding:utf-8 -*- import queue import threading import contextlib import time StopEvent = object() class ThreadPool(object): def __init__(self, max_num, max_task_num = None): if max_task_num: self.q = queue.Queue(max_task_num) else: self.q = queue.Queue() # 多大容量 self.max_num = max_num self.cancel = False self.terminal = False # 真实创建的线程列表 self.generate_list = [] # 空闲线程数量 self.free_list = [] def run(self, func, args, callback=None): """ 线程池执行一个任务 :param func: 任务函数 :param args: 任务函数所需参数 :param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数) :return: 如果线程池已经终止,则返回True否则None """ if self.cancel: return if len(self.free_list) == 0 and len(self.generate_list) < self.max_num: self.generate_thread() w = (func, args, callback,) self.q.put(w) def generate_thread(self): """ 创建一个线程 """ t = threading.Thread(target=self.call) t.start() def call(self): """ 循环去获取任务函数并执行任务函数 """ # 获取当前进程 current_thread = threading.currentThread() self.generate_list.append(current_thread) # 取任务 event = self.q.get() while event != StopEvent: # 是元组=》是任务 # 解开任务包 # 执行任务 func, arguments, callback = event try: result = func(*arguments) success = True except Exception as e: success = False result = None if callback is not None: try: callback(success, result) except Exception as e: pass with self.worker_state(self.free_list, current_thread): if self.terminal: event = StopEvent else: event = self.q.get() else: # 不是元组,不是任务 # 标记:我空闲了 # 执行后线程死掉 self.generate_list.remove(current_thread) def close(self): """ 执行完所有的任务后,所有线程停止 """ self.cancel = True full_size = len(self.generate_list) while full_size: self.q.put(StopEvent) full_size -= 1 def terminate(self): """ 无论是否还有任务,终止线程 """ self.terminal = True while self.generate_list: self.q.put(StopEvent) self.q.empty() @contextlib.contextmanager def worker_state(self, state_list, worker_thread): """ 用于记录线程中正在等待的线程数 """ state_list.append(worker_thread) try: yield finally: state_list.remove(worker_thread) # How to use pool = ThreadPool(5) def callback(status, result): # status, execute action status # result, execute action return value pass def action(i): print(i) for i in range(30): #将任务放在队列 #着手开始处理任务 #创建线程(有空闲线程则不创建;不高于线程池的限制;根据任务个数判断) =》线程去队列中去任务 ret = pool.run(action, (i,), callback) time.sleep(5) print(len(pool.generate_list), len(pool.free_list)) print(len(pool.generate_list), len(pool.free_list)) # pool.close() # pool.terminate()
7、上下文管理:
#!/usr/bin/env python # -*- coding:utf-8 -*- import queue import contextlib """ q = queue.Queue() li = [] # li.append(1) # q.get() # li.remove(1) @contextlib.contextmanager def worker_stater(xxx,val): xxx.append(val) try: yield 123 finally: xxx.remove(val) q.put("john") with worker_stater(li,1) as f: print(\'before\',li) print(f) q.get() pass pass print(\'after\',li) """ @contextlib.contextmanager def myopen(file_path,mode): f = open(file_path,mode,encoding=\'utf-8\') try: yield f finally: f.close() with myopen(\'index.html\',\'r\') as file_obj: print(file_obj.readline())
8、协程:
协程主要应用在IO密集型场景,由程序来控制,也叫微线程,高性能通常与协程挂钩
#!/usr/bin/env python # -*- coding:utf-8 -*- import gevent def foo(): print(\'Running in foo\') gevent.sleep(0) #切换协程 print(\'Explicit context switch to foo agein\') def bar(): print(\'Running in bar\') gevent.sleep(0) #切换协程 print(\'Explicit context switch back to bar agein\') gevent.joinall([ gevent.spawn(foo), gevent.spawn(bar), ])
#!/usr/bin/env python # -*- coding:utf-8 -*- from gevent import monkey;monkey.patch_all() import gevent import requests def f(url): print(\'GET:%s\' % url) resp = requests.get(url) data = resp.text print(url,len(data)) gevent.joinall([ gevent.spawn(f,\'http://www.python.org/\'), gevent.spawn(f,\'https://www.yahoo.com/\'), gevent.spawn(f,\'https://github.com/\'), ])
#!/usr/bin/env python # -*- coding:utf-8 -*- from greenlet import greenlet def test1(): print(12) gr2.switch() print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1.switch() gr1 = greenlet(test1) gr2 = greenlet(test2) gr1.switch()
end
以上是关于day21&22&23:线程进程协程的主要内容,如果未能解决你的问题,请参考以下文章