使用正则表达式
Posted 黄施策
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用正则表达式相关的知识,希望对你有一定的参考价值。
学会使用正则表达式
import requestsimport re newsurl = \'http://news.gzcc.cn/html/xiaoyuanxinwen/\' res = requests.get(newsurl) res.encoding = \'utf-8\' from bs4 import BeautifulSoup soup = BeautifulSoup(res.text, \'html.parser\')
1. 用正则表达式判定邮箱是否输入正确。
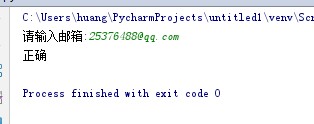
email = input("请输入邮箱:") result = re.match(\'^(\\w)+(\\.\\w+)*@(\\w)+((\\.\\w{2,3}){1,3})$\',email) if(result != None): print("正确") else: print("错误")

2. 用正则表达式识别出全部电话号码。
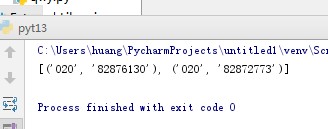
import re str = \'\'\'版权所有:广州商学院 地址:广州市黄埔区九龙大道206号 学校办公室:020-82876130 招生电话:020-82872773 粤公网安备 44011602000060号 粤ICP备15103669号\'\'\' print(re.findall(\'(\\d{3,4})-(\\d{6,8})\',str))
3. 用正则表达式进行英文分词。re.split(\'\',news)
string = "Today,we have a lot of homework" print(re.split(\',|\\s\',string))

4. 使用正则表达式取得新闻编号
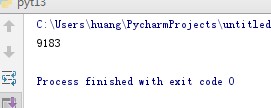
newsurl = "http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html" newID = re.match(\'http://news.gzcc.cn/html/2018/xiaoyuanxinwen(.*).html\', newsurl).group(1).split("/")[1] print(newID)
5. 生成点击次数的Request URL
url = "http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(newID) print(url)

6. 获取点击次数
newsurl = "http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html" newID = re.match(\'http://news.gzcc.cn/html/2018/xiaoyuanxinwen(.*).html\', newsurl).group(1).split("/")[1] url = "http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80".format(newID) contact = requests.get(url) count = contact.text.split(".html")[-1].lstrip("(\'").rstrip("\');") print(count)

7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
import re def getClickCount(): newUrl = "http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html" newsId = re.findall("\\_(.*).html",newUrl)[0].split("/")[-1]; res = requests.get("http://oa.gzcc.cn/api.php?op=count&id= {}&modelid=80".format(newsId)) return int(res.text.split(".html")[-1].lstrip("(\'").rsplit("\');")[0])
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
def getNewDetail(newsUrl): detail_res = requests.get(newsUrl) detail_res.encoding = "utf-8" detail_soup = BeautifulSoup(detail_res.text, "html.parser") print(detail_soup.select("#content")[0].text) # 正文 print(time, title, description, newsUrl) content = detail_soup.select("#content")[0].text info = detail_soup.select(".show-info")[0].text date_time = info.lstrip(\'发布时间:\')[:19] print(info)
9. 取出一个新闻列表页的全部新闻 包装成函数def getListPage(pageUrl):
def getlist(url): for news in soup.select("li"): if len(news.select(".news-list-title"))>0: #排除为空的li time = news.select(".news-list-info")[0].contents[0].text title = news.select(".news-list-title")[0].text description = news.select(".news-list-description")[0].text detail_url = news.select(\'a\')[0].attrs[\'href\'] print(time, title, description, detail_url)
10. 获取总的新闻篇数,算出新闻总页数包装成函数def getPageN():
def getPageN(url): res = requests.get(url) res.encoding = \'utf-8\' soup = BeautifulSoup(res.text, \'html.parser\') return int(soup.select(".a1")[0].text.rstrip("条"))//10+1
11. 获取全部新闻列表页的全部新闻详情。
def getall(url): for num in range(2,getPageN(url)): listpageurl="http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html".format(num) getlist(listpageurl) getNewDetail(listpageurl)
以上是关于使用正则表达式的主要内容,如果未能解决你的问题,请参考以下文章