hive 表的创建的操作与测试
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hive 表的创建的操作与测试相关的知识,希望对你有一定的参考价值。
- Hive 中创建表的三种方式,应用场景说明及练习截图
- 内部表和外部表的区别,练习截图
- 分区表的功能、创建,如何向分区表中加载数据、如何检索分区表中的数据,练习截图
一:hive HQL 的表操作:
1.1.1创建数据库:
hive> create database yangyang;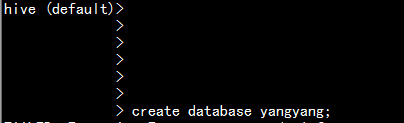
hive> desc database yangyang;
删除数据库:
hive> drop database yangyang casecad; ----> casecad 表示有表也删除1.1.2创建测试表:
emp表:
create table emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
row format delimited fields terminated by ‘\t‘;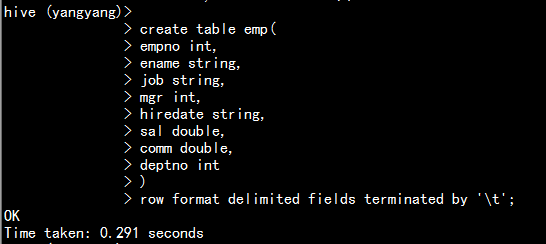
dept表:
create table dept(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by ‘\t‘;
1.1.3 导入测试数据:
load data local inpath "/home/hadoop/emp.txt" into table emp;
load data local inpath "/home/hadoop/dept.txt" into table dept;
注释: --local表示本地
--overwrite表示覆盖(默认情况使用的是append)
一般要加上overwrite 表示覆盖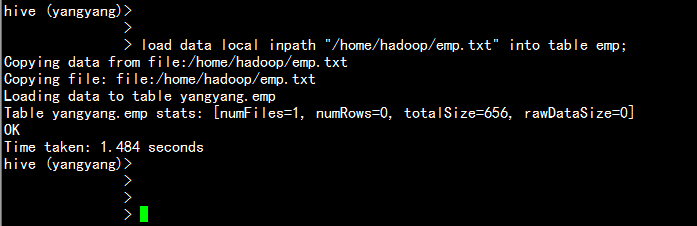

1.1.4 查看数据信息:
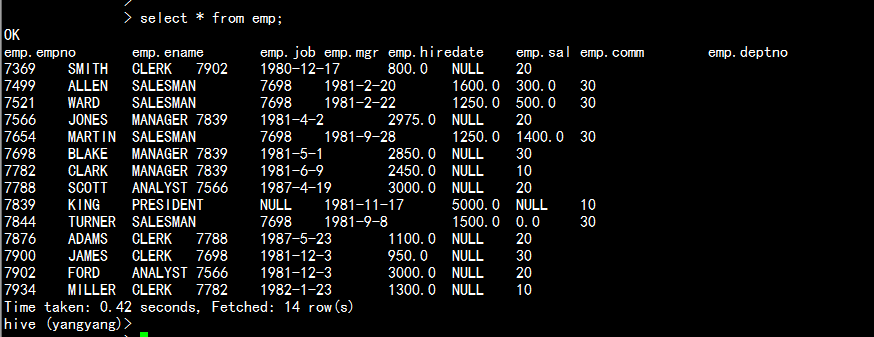
查看emp 表的信息
select * from emp;
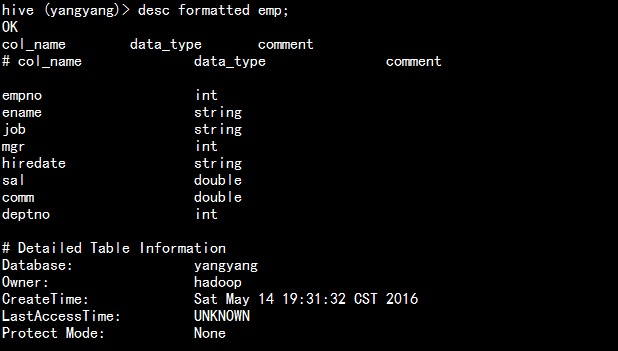
desc fromatted emp;

查看dept表:
select * from dept;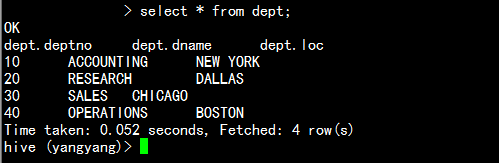


清空一个表:
truncate table emp;
重新命名一个表:
alter table emp rename to emp_bak;
补充hive 的操作:
hive 交互式登录:
bin/hive -e "select * from test01.dept;"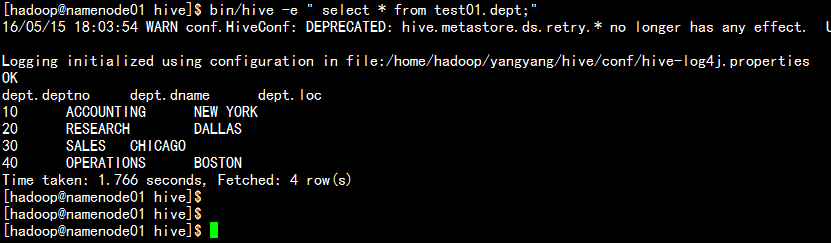
hive 执行sql 语句
bin/hive -f 可以执行编写的好的SQL 语句。
bin/hive -f 1.sql 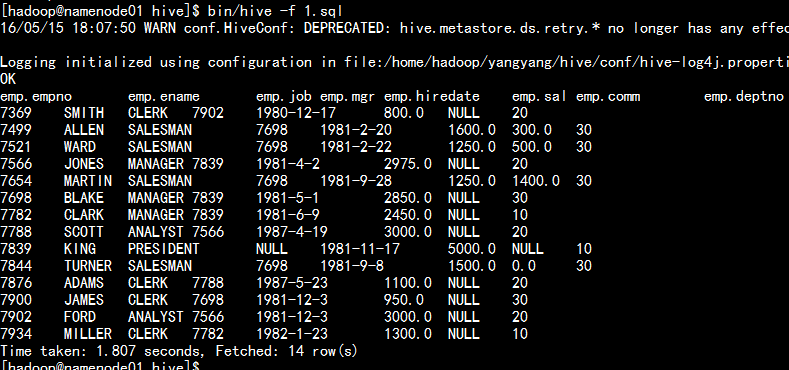
二:hive的数据表的类型:
hive 有三种表的类型:
hive 的管理表也可以称为内部表: 默认表类型。
1.数据存放的MANAGED_TABLE 内部
2.默认数据存储在仓库位置目录/user/hive/warehouse/下面,每创建一个库,就是一个目录,建表就会生成文件。
3.删除表的时候,也会删除HDFS上面的文件。create table dept1(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by ‘\t‘;
导入数据处理:
load data local inpath "/home/hadoop/dept.txt" into table dept1;2.1 hive 的外部表
应用场景面对不同的业务,提取数据处理。
业务1 业务2 业务3
drop select
2.1.1 数据存放的MANAGED_TABLE 内部
2.1.2 一般我们会使用location去指定存放到其他位置
2.1.3 删除表的时候,不会去删除HDFS上面的文体,只删除元数据create table dept2(
deptno int,
dname string,
loc string
)
row format delimited fields terminated by ‘\t‘ location ‘/hive/dept2‘;
导入数据处理
load data local inpath "/home/hadoop/dept.txt" into table dept2;2.2:hive的分区表
使用业务场景:
2.2.1 时间增量数据
2.2.2 提高查询速度(核心)
2.2.3 一级分区、二级分区 partitioned by (date string,time string)
2.2.4 创建表时需要给定partitioned 处理 一般是 指定日期为string 类型。create table emp3(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
partitioned by (data string)
row format delimited fields terminated by ‘\t‘;
导入数据的时候要加上partitioned处理。
load data local inpath "/home/hadoop/emp.txt" into table emp3 partition (date=‘20150515‘);
查找可以用按 分区去查找
select * from emp3 where date=‘20150515‘;hive 中 创建桶表:
create table emp4(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
)
clustered by(empno) into 3 buckets
row format delimited fields terminated by ‘\t‘;
默认情况下load 加载时不分桶表:
强制设置分区:set hive.enforce.bucketing = true;
可以使用查询其它表加载到桶表,
插入数据: insert into emp4 select * from emp4;
hive> dfs -lsr /
hive 中的桶表数量如何去设置
评估数据量,保证每个桶的数据量block 的2倍大小

上传 文件到 分区表当中 没有带分区等相关信息 就需要修复分区表:
msck repair table emp3 ;
或者:
alter table emp3 add partition(date=‘20150515‘);以上是关于hive 表的创建的操作与测试的主要内容,如果未能解决你的问题,请参考以下文章