使用正则表达式,取得点击次数,函数抽离
Posted 独毒诚
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用正则表达式,取得点击次数,函数抽离相关的知识,希望对你有一定的参考价值。
学会使用正则表达式
1. 用正则表达式判定邮箱是否输入正确。
r=\'^(\\w)+(\\.\\w+)*@(\\w)+((\\.\\w{2,3}){1,3})$\'
e=\'67890222@qq.com\'
if re.match(r,e):
print(re.match(r,e).group(0))
else:
print(\'非邮箱格式!\')
2. 用正则表达式识别出全部电话号码。
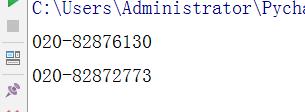
str=\'\'\'版权所有:广州商学院 地址:广州市黄埔区九龙大道206号
学校办公室:020-82876130 招生电话:020-82872773
粤公网安备 44011602000060号 粤ICP备15103669号\'\'\'
r = \'\\d{3}-\\d{8}|\\d{4}-\\d{7}\'
n=re.findall(r,str)
for i in n:
print(i)
3. 用正则表达式进行英文分词。re.split(\'\',news)
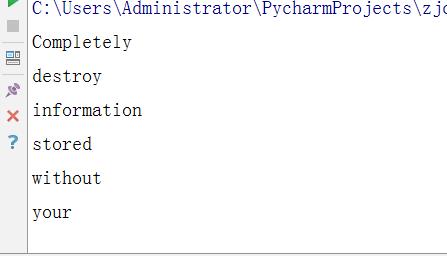
str=\'\'\'Completely destroy information stored without your knowledge or approval:
Internet history, Web pages and pictures from sites visited on the Internet,
unwanted cookies, chatroom conversations, deleted e-mail messages, temporary files,
the Windows swap file, the Recycle Bin, previously deleted files, valuable corporate
trade secrets, Business plans, personal files, photos or confidential letters,
etc.\'\'\'
n=re.split(r\'[ \\t\\n]+\',str)
for i in n:
print(i)
4. 使用正则表达式取得新闻编号
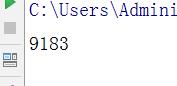
import re newurl=\'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html\' newid=re.search(\'\\_(.*).html\',newurl).group(1).split(\'/\')[-1] print(newid)
5. 生成点击次数的Request URL
import re newurl=\'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html\' newid=re.search(\'\\_(.*).html\',newurl).group(1).split(\'/\')[-1] res=\'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80\'.format(newid) print(res)

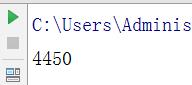
6. 获取点击次数
import requests
import re
newurl=\'http://news.gzcc.cn/html/2018/xiaoyuanxinwen_0404/9183.html\'
newid=re.search(\'\\_(.*).html\',newurl).group(1).split(\'/\')[-1]
res=requests.get(\'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80\'.format(newid))
r1=int(res.text.split(".html")[-1].lstrip("(\'").rstrip("\');"))
print(r1)
7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
import requests
import re
def getClickCount(newsUrl):
newid=re.search(\'\\_(.*).html\',newsUrl).group(1).split(\'/\')[-1]
res=requests.get(\'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80\'.format(newid))
return int(res.text.split(".html")[-1].lstrip("(\'").rstrip("\');"))
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
def getNewDetail(newsUrl):
resd = requests.get(newsUrl)
resd.encoding = \'utf-8\'
soupd = BeautifulSoup(resd.text, \'html.parser\')
title = soupd.select(\'.show-title\')[0].text
info = soupd.select(\'.show-info\')[0].text
ti = datetime.strptime(info.lstrip(\'发布时间:\')[0:19], \'%Y-%m-%d %H:%M:%S\')
if info.find(\'来源:\') > 0:
source = info[info.find(\'来源:\'):].split()[0].lstrip(\'来源:\')
else:
source = \'none\'
click = getClickCount(newsUrl)
print(ti, title, source, click)
9. 取出一个新闻列表页的全部新闻 包装成函数def getListPage(pageUrl):
def getListPage(pageUrl):
res = requests.get(pageUrl)
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
for news in soup.select(\'li\'):
if len(news.select(\'.news-list-title\')) > 0:
g = news.select(\'a\')[0].attrs[\'href\']
print(g)
getNewDetail(g)
10. 获取总的新闻篇数,算出新闻总页数包装成函数def getPageN():
def getPageN():
res = requests.get(\'http://news.gzcc.cn/html/xiaoyuanxinwen/\')
res.encoding = \'utf-8\'
soup = BeautifulSoup(res.text, \'html.parser\')
pagenumber=int(soup.select(\'.a1\')[0].text.rstrip(\'条\'))
page = pagenumber//10+1
return page
11. 获取全部新闻列表页的全部新闻详情。
pageUrl = \'http://news.gzcc.cn/html/xiaoyuanxinwen/\'
getListPage(pageUrl)
n = getPageN()
for i in range(2, n + 1):
listPageUrl = \'http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html\'.format(i)
getListPage(listPageUrl)

以上是关于使用正则表达式,取得点击次数,函数抽离的主要内容,如果未能解决你的问题,请参考以下文章