对大文件排序
Posted THISISPAN
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对大文件排序相关的知识,希望对你有一定的参考价值。
设想你有一个20GB的文件,每行一个字符串,说明如何对这个文件进行排序。
内存肯定没有20GB大,所以不可能采用传统排序法。但是可以将文件分成许多块,每块xMB,针对每个快各自进行排序,存回文件系统。
然后将这些块逐一合并,最终得到全部排好序的文件。
外排序的一个例子是外归并排序(External merge sort),它读入一些能放在内存内的数据量,在内存中排序后输出为一个顺串(即是内部数据有序的临时文件),处理完所有的数据后再进行归并。[1][2]比如,要对900MB的数据进行排序,但机器上只有100 MB的可用内存时,外归并排序按如下方法操作:
- 读入100 MB的数据至内存中,用某种常规方式(如快速排序、堆排序、归并排序等方法)在内存中完成排序。
- 将排序完成的数据写入磁盘。
- 重复步骤1和2直到所有的数据都存入了不同的100 MB的块(临时文件)中。在这个例子中,有900 MB数据,单个临时文件大小为100 MB,所以会产生9个临时文件。
- 读入每个临时文件(顺串)的前10 MB( = 100 MB / (9块 + 1))的数据放入内存中的输入缓冲区,最后的10 MB作为输出缓冲区。(实践中,将输入缓冲适当调小,而适当增大输出缓冲区能获得更好的效果。)
- 执行九路归并算法,将结果输出到输出缓冲区。一旦输出缓冲区满,将缓冲区中的数据写出至目标文件,清空缓冲区。一旦9个输入缓冲区中的一个变空,就从这个缓冲区关联的文件,读入下一个10M数据,除非这个文件已读完。这是“外归并排序”能在主存外完成排序的关键步骤 -- 因为“归并算法”(merge algorithm)对每一个大块只是顺序地做一轮访问(进行归并),每个大块不用完全载入主存。
问题
给你1个文件bigdata,大小4663M,5亿个数,文件中的数据随机,如下一行一个整数:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
61963023557681612158020393452095006174677379343122016371712330287901712966901...7005375 |
现在要对这个文件进行排序,怎么搞?
内部排序
先尝试内排,选2种排序方式:
3路快排:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
|
private final int cutoff = 8;public <T> void perform(Comparable<T>[] a) { perform(a,0,a.length - 1); } private <T> int median3(Comparable<T>[] a,int x,int y,int z) { if(lessThan(a[x],a[y])) { if(lessThan(a[y],a[z])) { return y; } else if(lessThan(a[x],a[z])) { return z; }else { return x; } }else { if(lessThan(a[z],a[y])){ return y; }else if(lessThan(a[z],a[x])) { return z; }else { return x; } } } private <T> void perform(Comparable<T>[] a,int low,int high) { int n = high - low + 1; //当序列非常小,用插入排序 if(n <= cutoff) { InsertionSort insertionSort = SortFactory.createInsertionSort(); insertionSort.perform(a,low,high); //当序列中小时,使用median3 }else if(n <= 100) { int m = median3(a,low,low + (n >>> 1),high); exchange(a,m,low); //当序列比较大时,使用ninther }else { int gap = n >>> 3; int m = low + (n >>> 1); int m1 = median3(a,low,low + gap,low + (gap << 1)); int m2 = median3(a,m - gap,m,m + gap); int m3 = median3(a,high - (gap << 1),high - gap,high); int ninther = median3(a,m1,m2,m3); exchange(a,ninther,low); } if(high <= low) return; //lessThan int lt = low; //greaterThan int gt = high; //中心点 Comparable<T> pivot = a[low]; int i = low + 1; /* * 不变式: * a[low..lt-1] 小于pivot -> 前部(first) * a[lt..i-1] 等于 pivot -> 中部(middle) * a[gt+1..n-1] 大于 pivot -> 后部(final) * * a[i..gt] 待考察区域 */ while (i <= gt) { if(lessThan(a[i],pivot)) { //i-> ,lt -> exchange(a,lt++,i++); }else if(lessThan(pivot,a[i])) { exchange(a,i,gt--); }else{ i++; } } // a[low..lt-1] < v = a[lt..gt] < a[gt+1..high]. perform(a,low,lt - 1); perform(a,gt + 1,high); } |
归并排序:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
|
/** * 小于等于这个值的时候,交给插入排序 */private final int cutoff = 8;/** * 对给定的元素序列进行排序 * * @param a 给定元素序列 */@Overridepublic <T> void perform(Comparable<T>[] a) { Comparable<T>[] b = a.clone(); perform(b, a, 0, a.length - 1);}private <T> void perform(Comparable<T>[] src,Comparable<T>[] dest,int low,int high) { if(low >= high) return; //小于等于cutoff的时候,交给插入排序 if(high - low <= cutoff) { SortFactory.createInsertionSort().perform(dest,low,high); return; } int mid = low + ((high - low) >>> 1); perform(dest,src,low,mid); perform(dest,src,mid + 1,high); //考虑局部有序 src[mid] <= src[mid+1] if(lessThanOrEqual(src[mid],src[mid+1])) { System.arraycopy(src,low,dest,low,high - low + 1); } //src[low .. mid] + src[mid+1 .. high] -> dest[low .. high] merge(src,dest,low,mid,high);}private <T> void merge(Comparable<T>[] src,Comparable<T>[] dest,int low,int mid,int high) { for(int i = low,v = low,w = mid + 1; i <= high; i++) { if(w > high || v <= mid && lessThanOrEqual(src[v],src[w])) { dest[i] = src[v++]; }else { dest[i] = src[w++]; } }} |
数据太多,递归太深 ->栈溢出?加大Xss?
数据太多,数组太长 -> OOM?加大Xmx?
耐心不足,没跑出来.而且要将这么大的文件读入内存,在堆中维护这么大个数据量,还有内排中不断的拷贝,对栈和堆都是很大的压力,不具备通用性。
sort命令来跑
|
1
|
sort
-n bigdata -o bigdata.sorted |
跑了多久呢?24分钟.
为什么这么慢?
粗略的看下我们的资源:
- 内存
jvm-heap/stack,native-heap/stack,page-cache,block-buffer- 外存
swap + 磁盘数据量很大,函数调用很多,系统调用很多,内核/用户缓冲区拷贝很多,脏页回写很多,io-wait很高,io很繁忙,堆栈数据不断交换至swap,线程切换很多,每个环节的锁也很多.
总之,内存吃紧,问磁盘要空间,脏数据持久化过多导致cache频繁失效,引发大量回写,回写线程高,导致cpu大量时间用于上下文切换,一切,都很糟糕,所以24分钟不细看了,无法忍受.
位图法
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
private
BitSet bits;public
void perform( String largeFileName, int
total, String destLargeFileName, Castor<Integer> castor, int
readerBufferSize, int
writerBufferSize, boolean
asc) throws
IOException { System.out.println("BitmapSort Started."); long
start = System.currentTimeMillis(); bits = new
BitSet(total); InputPart<Integer> largeIn = PartFactory.createCharBufferedInputPart(largeFileName, readerBufferSize); OutputPart<Integer> largeOut = PartFactory.createCharBufferedOutputPart(destLargeFileName, writerBufferSize); largeOut.delete(); Integer data; int
off = 0; try
{ while
(true) { data = largeIn.read(); if
(data == null) break; int
v = data; set(v); off++; } largeIn.close(); int
size = bits.size(); System.out.println(String.format("lines : %d ,bits : %d", off, size)); if(asc) { for
(int
i = 0; i < size; i++) { if
(get(i)) { largeOut.write(i); } } }else
{ for
(int
i = size - 1; i >= 0; i--) { if
(get(i)) { largeOut.write(i); } } } largeOut.close(); long
stop = System.currentTimeMillis(); long
elapsed = stop - start; System.out.println(String.format("BitmapSort Completed.elapsed : %dms",elapsed)); }finally
{ largeIn.close(); largeOut.close(); }}private
void set(int
i) { bits.set(i);}private
boolean get(int
v) { return
bits.get(v);} |
nice!跑了190秒,3分来钟.
以核心内存4663M/32大小的空间跑出这么个结果,而且大量时间在用于I/O,不错.
问题是,如果这个时候突然内存条坏了1、2根,或者只有极少的内存空间怎么搞?
外部排序
该外部排序上场了.
外部排序干嘛的?
- 内存极少的情况下,利用分治策略,利用外存保存中间结果,再用多路归并来排序;
- map-reduce的嫡系.
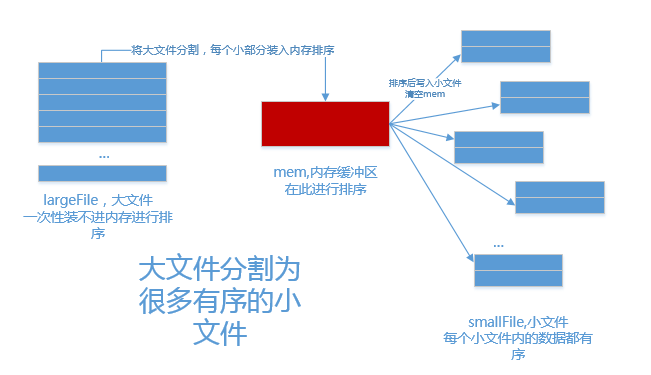
1.分
内存中维护一个极小的核心缓冲区memBuffer,将大文件bigdata按行读入,搜集到memBuffer满或者大文件读完时,对memBuffer中的数据调用内排进行排序,排序后将有序结果写入磁盘文件bigdata.xxx.part.sorted.
循环利用memBuffer直到大文件处理完毕,得到n个有序的磁盘文件:
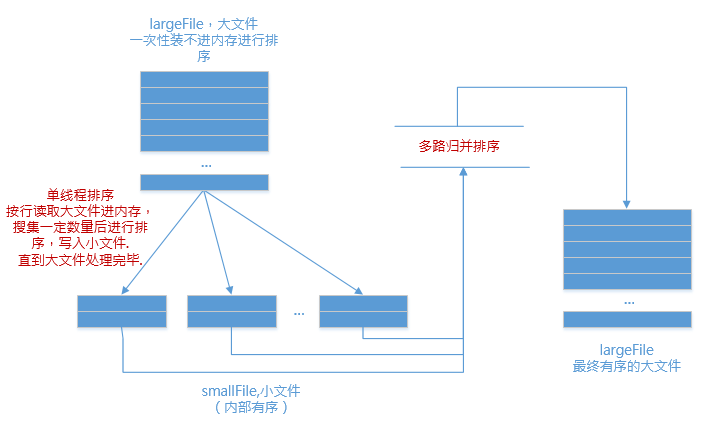
2.合
现在有了n个有序的小文件,怎么合并成1个有序的大文件?
把所有小文件读入内存,然后内排?
(⊙o⊙)…
no!
利用如下原理进行归并排序:
我们举个简单的例子:

文件1:3,6,9
文件2:2,4,8
文件3:1,5,7第一回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:1,排在文件3的第1行
那么,这3个文件中的最小值是:min(1,2,3) = 1
也就是说,最终大文件的当前最小值,是文件1、2、3的当前最小值的最小值,绕么?
上面拿出了最小值1,写入大文件.
第二回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:5,排在文件3的第2行
那么,这3个文件中的最小值是:min(5,2,3) = 2
将2写入大文件.也就是说,最小值属于哪个文件,那么就从哪个文件当中取下一行数据.(因为小文件内部有序,下一行数据代表了它当前的最小值)
最终的时间,跑了771秒,13分钟左右.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
less bigdata.sorted.text...9999966999996799999689999969999997099999719999972999997399999749999975999997699999779999978
|
以上是关于对大文件排序的主要内容,如果未能解决你的问题,请参考以下文章