https://github.com/YYCZ/WCPro
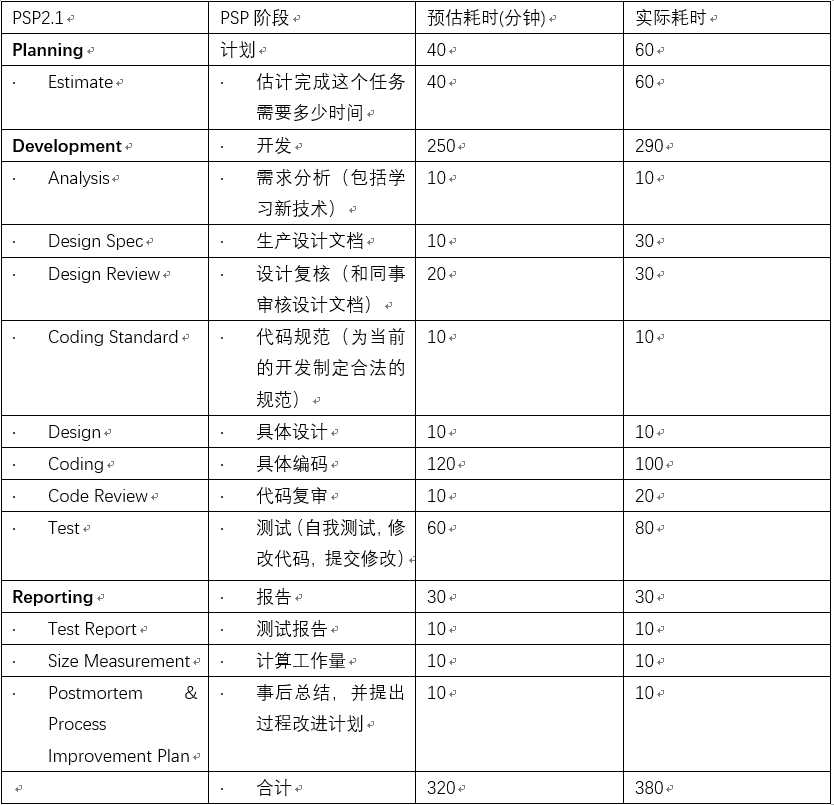
基础任务:
在WCPro的实现过程中,我负责核心模块即词频统计及排序功能的编写。具体可以划分为一下几个任务:
1)分词:从文本中提取出符合要求的单词,相比WordCount里的分词而言,此处尤其需要注意对连词符-的处理。
2)统计词频:要统计各个单词出现的次数,自然要时刻维护(单词,频度)这样的一个二元组集合。一种直接的做法是维护一个元素为(单词,频度)的线性表,提取出单词时先查找线性表再做进一步处理。假设文本共有n个单词,统计词频的时间复杂度为O(n^2),空间开销为O(n)。既然提到了查找,很容易想到哈希表,哈希表提供O(1)的查找操作,利用哈希统计词频的时间复杂度为O(n),空间开销O(n)。
3)排序,快排O(nlgn),如果对输入做一些限定(比如假定没有单词会出现1000次以上)或者不去考虑空间开销,可以用O(n)的计数排序。
于是可以看到哈希表+快排整体可达到O(nlgn)的时间复杂度。这个时候效率的瓶颈在于排序,如果对输入做一些限定(比如假定没有单词会出现1000次以上)或者不去考虑空间开销,可以用计数排序将整体的时间复杂度降到O(n),理论上不存在比O(n)更快的算法了,毕竟不遍历一遍文本中的所有单词就无法完成词频统计排序。
实现时我采用Word对象作为统计数据的单元。


用哈希+快排完成词频统计和排序。
出于效率考量,我选择了String和Integer作为hashmap的键值对类型。词频统计后再将其转为ArrayList<Word>对象进行排序。
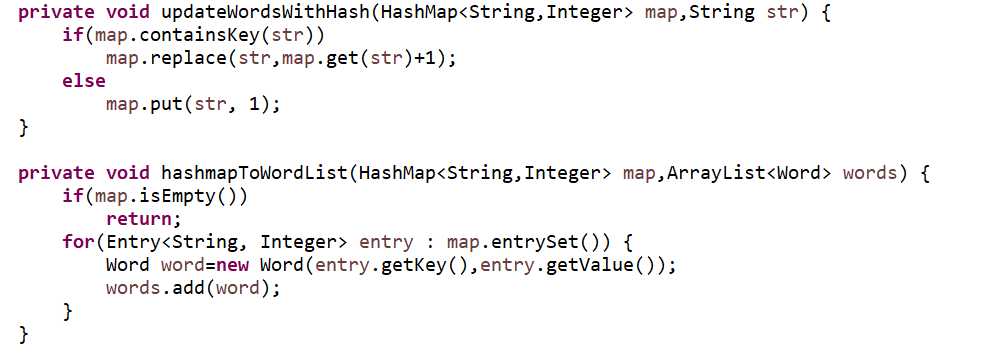
排序的话只要Collections.sort(words)即可。
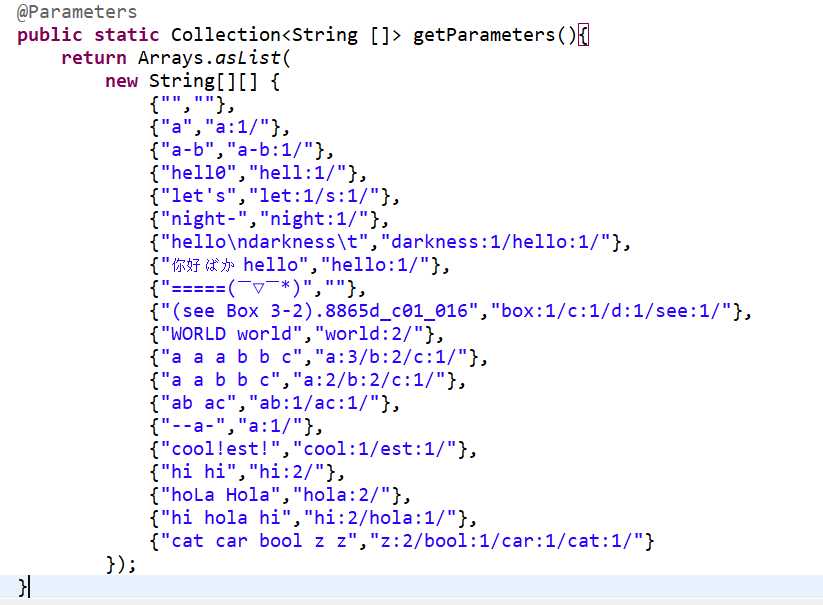
设计测试用例时我从黑盒测试和白盒测试的角度出发全面地测试该模块的功能。
用"-hello","a-b-c","hell0"等等测试分词的正确性。
用"hello hola hello"等测试词频统计的正确性。
用"ab ac ba"等测试排序的正确性。
最后做一些整体性的测试。
单元测试的截图:
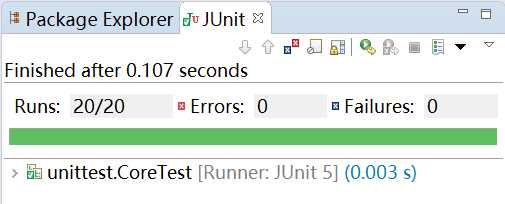
测试的过程中发现了两个程序的缺陷,一是Java提供的Charcter.isLetter()方法其实不是我想的那样,于是我自己写了一个。二是我在对‘-’的处理当中有一处疏漏。看来单元测试还是蛮有用的。
扩展任务:
从阿里巴巴Java开发手册中有如下规范

这个规范我之前从没有注意过,以前我都是反例写法,学习了。
接下来是学号为17156的同学的部分代码:

该同学显然和我一样没有意识到内存资源浪费的问题。
此外该同学的代码格式不算完全规范,不过我个人认为可以接受。
我们组选择了Checkstyle来做静态代码检查。
下载地址:
http://checkstyle.sourceforge.net/
针对我自己写的Core类静态代码扫描的结果如下:
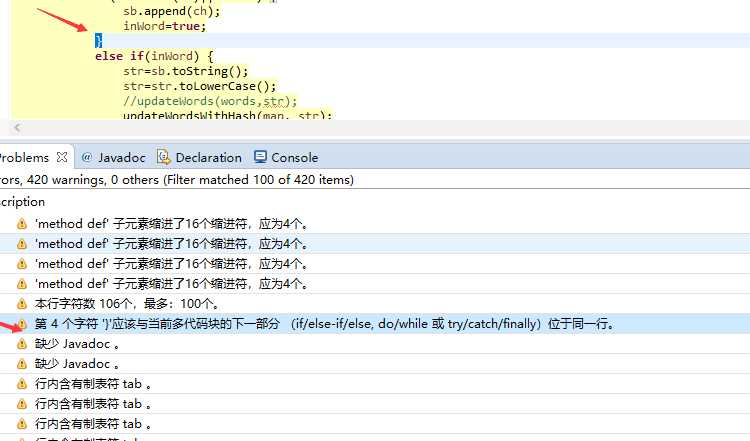
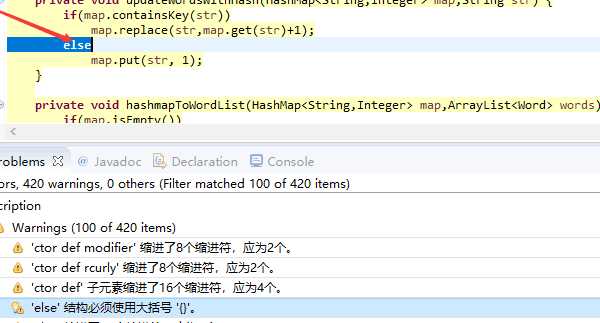
可以看到我的代码不规范之处主要在于
1)使用了tab而不是空格缩进
2)else换行了
3)if else for 等控制语句没有做到一定加大括号
因为都是一些格式问题,修改后再次运行单元测试并未发现很大区别。
将大家的代码都看了一遍以后,我发现主要的问题还是集中在代码格式不规范,变量命名随意上。
高级任务:
我们选择了英文版《飘》作为测试数据集。
最初的版本我没有采用哈希表来统计词频。
对《飘》词频统计的结果如下:

之后进行了小组讨论,由17172主持,17178,17172,17156参与评审。
17172指出程序中最耗时的部分毫无疑问是核心处理模块。
17178分享了编写核心处理模块时的思路。
17176赞成用哈希表完成词频统计会是更优的方案。
17156探讨了用计数排序进一步提升排序速度的可行性。
讨论结束我们一致认为使用哈希表将大大提高程序的效率。
使用哈希表后,结果如下:

可以看到使用哈希表后,程序的执行速度有了显著的提升。
就像我之前在接口实现分析中提到的一样,这是因为统计词频算法的复杂度从O(n^2)降到了O(n)的缘故。
通过本此作业实践,我体会到软件开发需要与软件测试同时进行,完成一个模块后就应该立刻进行单元测试,确保模块的正确性。在通过单元测试验证了正确性以后还应该重新审阅自己的代码,提升代码的规范性和可读性。如果在这之后还有时间的话可以进一步测试程序性能,并对程序进行性能优化。以上步骤基本可以保证开发出的软件满足基本的软件质量要求。