一个简单的百度爬虫
Posted _昏鸦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个简单的百度爬虫相关的知识,希望对你有一定的参考价值。
0x00
之前不知道python怎么爬取百度的内容,因为看到有很多参数,直接复制下来改变wd参数总是会出现各种奇怪的问题
昨晚经程师傅指点才知道原来很多参数并不是必要的。今天才搜了下百度的各个参数的意义,以前居然没想到去搜一下百度的参数,感觉自己真是太愚钝了
于是,今天写了个小小的百度爬虫
0x01
代码:
#!/usr/bin/python
# -*- coding:utf-8 -*-
# 昏鸦
import requests
import re
import sys
def get_baidu(s,page=5):
pattern = "data-tools=\'{\\"title\\":\\"(.*?)\\",\\"url\\":\\"(.*?)\\""
for p in xrange(0,page*10+1,10):
req = "http://www.baidu.com/s?wd={}&pn={}&cl=3".format(s,p)
res = requests.get(url=req).text
reg = re.findall(pattern,res)
for i in xrange(len(reg)):
title = reg[i][0]
url = requests.get(url=reg[i][1]).url
print title+\'\\n\'+url+\'\\n\\n\'
if __name__==\'__main__\':
get_baidu(sys.argv[1],int(sys.argv[2]))
结果:
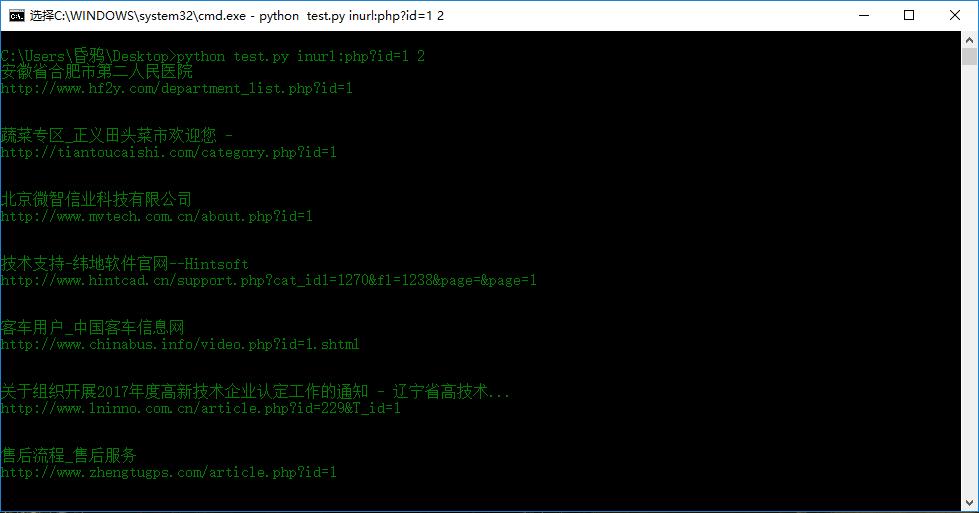
0x02
只爬取了百度出来的标题和URL链接,默认爬取前5页
以上是关于一个简单的百度爬虫的主要内容,如果未能解决你的问题,请参考以下文章