WordCountPro,完结撒花
软测第四周作业
一、概述
该项目github地址如下:
https://github.com/YuQiao0303/WordCountPro
该项目需求如下:
http://www.cnblogs.com/ningjing-zhiyuan/p/8654132.html
在此完成了基本任务和拓展任务。
该项目PSP表格如下:
| PSP2.1表格 | |||
|---|---|---|---|
| PSP2.1 | PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 15 | 3 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 3 |
| Development | 开发 | 930 | 956 |
| · Analysis | · 需求分析 (包括学习新技术) | 360 | 339 |
| · Design Spec | · 生成设计文档 | 60 | 31 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 30 | 0 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 0 |
| · Design | · 具体设计 | 0 | 0 |
| · Coding | · 具体编码 | 60 | 130 |
| · Code Review | · 代码复审 | 120 | 0 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 240 | 456 |
| Reporting | 报告 | 305 | 204 |
| · Test Report | · 测试报告 | 0 | 0 |
| · Size Measurement | · 计算工作量 | 5 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 300 | 204 |
| 合计 | 1250 | 1163 |
基本任务
二、实现接口
这次任务设计的框架中,我们设计了一个类,类的结构如下:
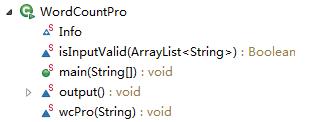
经过讨论认为wcPro()相对较难,最终分工如下:
isInputValid() :商莹
wcPro() :余乔(我),雷佳谕。(结对编程)
output():蒋雨晨
其中,我和队友雷佳谕分到的wcPro方法需要完成的功能是,统计文本文件input中的单词和词频,将结果存入类的静态属性Info中。(Info声明如下:)
static TreeMap<String,Integer> Info = new TreeMap<String,Integer>(); `
采用结对编程的方式完成了该方法的实现。设计思路如下:
- 与第二周相同,采用String类的split方法分割单词,将统计的单词和词频存入TreeMap类型的变量Info中。
- 按行读取文件。根据需求,输入的文本文件中,所有可能出现的字符分为三种:字母、连字符、其他字符(包括数字和给出的常用字符表中的全部常用字符)。我们将其他字符作为分隔符,分割得到“潜在单词”(word)。
String reg1 = "[\\\\s~`!#%\\\\^&\\\\*_\\\\.\\\\(\\\\)\\\\[\\\\]\\\\+=:;\\"\'\\\\|<>\\\\,/\\\\?0-9]+";
String words[] = line.split(reg1);
- 潜在单词中,可能出现“”(空字符串)和“---”(只含连字符的字符串)的情况。通过判断,直接丢弃改潜在单词。
for(String word: words){
if("".equals(word)||!word.matches(containLetter)){
continue;
}
...
}
- 剩下的潜在单词全是需要统计的单词,但统计是需要去掉单词首位的连字符。例如遇到潜在单词“-night”,存入Info的应该是“night”。我们的处理方法是通过循环语句,找到潜在单词word中,第一个不是连字符的字符的坐标firstIndex(也就是第一个字母的坐标),和最后一个不是连字符的字符的坐标lastIndex(也就是最后一个字母的坐标)。然后利用subString方法得到最终要存的单词。
String containLetter=".*[a-z].*";
int firstIndex=0,lastIndex=word.length()-1;
char hyphen=\'-\';
//寻找第一个字母的坐标
while(word.charAt(firstIndex)==hyphen){
firstIndex++;
}
//寻找最后一个字母的坐标
while(word.charAt(lastIndex)==hyphen){
lastIndex--;
}
word=word.substring(firstIndex, lastIndex+1);
- 最后将统计结果写如Info中即可。
if(!Info.containsKey(word)){
Info.put(word,1);
}
else{
Info.put(word,Info.get(word)+1);
}
于是即可得到wcPro()方法的完整代码:
/**将单词和词频存入info
* 雷佳谕、余乔
* */
static void wcPro(String input) throws IOException{
File file=new File(input);
BufferedReader br = new BufferedReader(new FileReader(file));
String line = null;
//定义一个map集合保存单词和单词出现的个数
//TreeMap<String,Integer> tm = new TreeMap<String,Integer>();
//读取文件
while((line=br.readLine())!=null){
line=line.toLowerCase();
//System.out.println(line);
String reg1 = "[\\\\s~`!#%\\\\^&\\\\*_\\\\.\\\\(\\\\)\\\\[\\\\]\\\\+=:;\\"\'\\\\|<>\\\\,/\\\\?0-9]+";
String containLetter=".*[a-z].*";
//String reg2 ="\\\\w+";
//将读取的文本进行分割
String[] words = line.split(reg1);
for(String word: words){
if("".equals(word)||!word.matches(containLetter)){
continue;
}
int firstIndex=0,lastIndex=word.length()-1;
char hyphen=\'-\';
//寻找第一个字母的坐标
while(word.charAt(firstIndex)==hyphen){
firstIndex++;
}
//寻找最后一个字母的坐标
while(word.charAt(lastIndex)==hyphen){
lastIndex--;
}
word=word.substring(firstIndex, lastIndex+1);
if(!Info.containsKey(word)){
Info.put(word,1);
}else{
Info.put(word,Info.get(word)+1);
}
}
}
br.close();
}
设计测试用例
针对结对编写的wcPro()方法的单元测试,是我和队友雷佳谕,分别独立完成的。我们各有一个测试类。
其中,我按照白盒测试和黑盒测试方法,共设计了34个测试用例。
白盒测试
这里采用独立路径测试的思想。
首先画出程序图。原本画出的程序图是这样的:
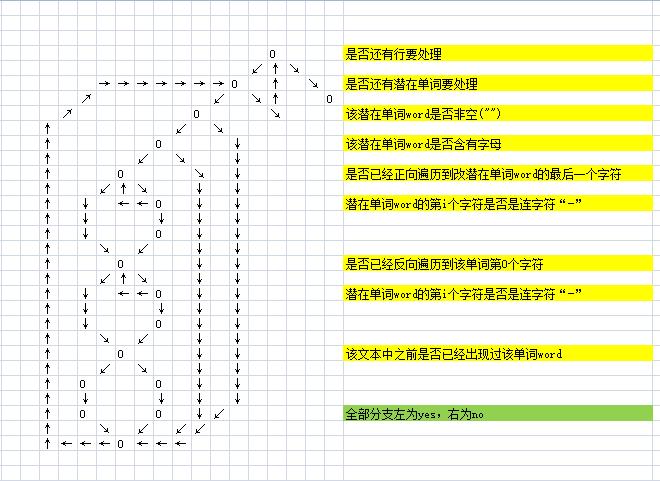
我和队友画完图,才发现程序结构实在让人看不下去。于是将程序修改之后(也就是刚才展示的样子),才得到新的程序图:
(分支节点用黄色标出)
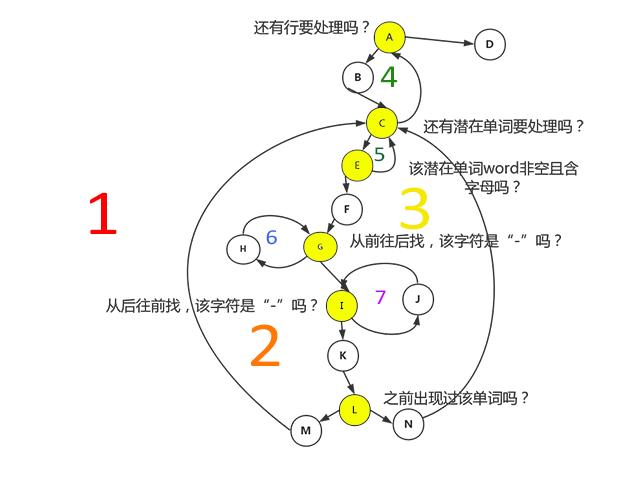
可以看到,wcPro()方法的环复杂度为7,需要设计七个测试用例。
首先选择了主路径ABCEFGIKLNCAD
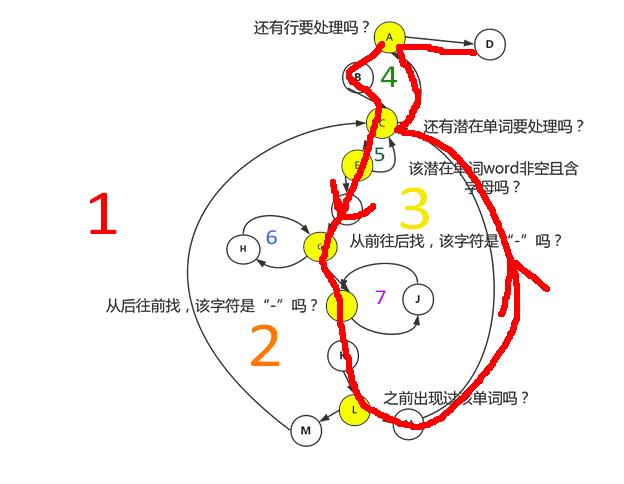
之后分别改变A/C/E/G/I/L六个分支节点的判定结果,得到剩下六个独立的测试用例。
最终得到的白盒测试(路经测试)的七个测试用例情况如下:
|Test Case ID 测试用例编号|Test Item 测试项(即功能模块或函数)|Test Case Title 测试用例标题|Test Criticality重要级别|是否自动用例|是否新增修改用例|Pre-condition 预置条件|Input 输入|Procedure 操作步骤|Output 预期结果|Result
实际结果|Status
是否通过|Remark 备注(在此描述使用的测试方法)||
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|YuTest0|static void wcPro(String input)|主路径|High|是|否|输入文件内容为:“a”|YuTest0.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|路经测试(白盒测试)|
|YuTest1|static void wcPro(String input)|没有行要处理|Low|是|否|输入文件内容为空|YuTest1.txt|直接执行|Info内容为空|Info内容为空|OK|路经测试(白盒测试)|
|YuTest2|static void wcPro(String input)|该行无潜在单词|Low|是|否|输入文件内容为:“a\\n\\nb”|YuTest2.txt|直接执行|Info内容为a:1.b:1|Info内容为a:1.b:1|OK|路经测试(白盒测试)|
|YuTest3|static void wcPro(String input)|潜在单词为空或不含字母|Low|是|否|输入文件内容为:“-----”|YuTest3.txt|直接执行|Info内容为空|Info内容为空|OK|路经测试(白盒测试)|
|YuTest4|static void wcPro(String input)|潜在单词开头是连字符|Midium|是|否|输入文件内容为:“-a”|YuTest4.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|路经测试(白盒测试)|
|YuTest5|static void wcPro(String input)|潜在单词结尾是连字符|Midium|是|否|输入文件内容为:“a-”|YuTest5.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|路经测试(白盒测试)|
|YuTest6|static void wcPro(String input)|之前出现过该单词|High|是|否|输入文件内容为:“a\\n\\na”|YuTest6.txt|直接执行|Info内容为a:2|Info内容为a:2|OK|路经测试(白盒测试)|
黑盒测试
wordCountPro到底如何进行黑盒测试,这个问题困扰了我很久。几次推翻重来,最后的考虑是这样的:
输入作为一个文本,每个字符都有很多中可能,文本长度不限,从而文本的内容组合有几乎无数种。
从需求的角度看,只含字母的可以算一类,一串字母首尾含连字符的可以算一类,一串字母中间含连字符的可以算一类,等等。
但是从黑盒测试的角度,假装自己完全不了解程序内部结构,我会非常担心程序能否真的按要求,无bug地把这些情况按照一类来处理。
最后我的选择是,将每个字符分成三类:字母、连字符、其他字符(含数字和特殊字符)。如果将文本长度置为三个字符,27个用例即可穷尽三类字符的所有排列组合,同时也不失一般性。这样测试,我会感到保险很多。
|Test Case ID 测试用例编号|Test Item 测试项(即功能模块或函数)|Test Case Title 测试用例标题|Test Criticality重要级别|是否自动用例|是否新增修改用例|Pre-condition 预置条件|Input 输入|Procedure 操作步骤|Output 预期结果|Result
实际结果|Status
是否通过|Remark 备注(在此描述使用的测试方法)||
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|YuTest7|static void wcPro(String input)|字母,字母,字母|High|是|否|输入文件内容为:“aaa”|YuTest7.txt|直接执行|Info内容为aaa:1|Info内容为aaa:1|OK|等价类测试(黑盒测试)|
|YuTest8|static void wcPro(String input)|字母,字母,连字符|Low|是|否|输入文件内容为:“aa-”|YuTest8.txt|直接执行|Info内容为aa:1|Info内容为aa:1|OK|等价类测试(黑盒测试)|
|YuTest9|static void wcPro(String input)|字母,字母,其他字符|High|是|否|输入文件内容为:“aa1”|YuTest9.txt|直接执行|Info内容为aa:1|Info内容为aa:1|OK|等价类测试(黑盒测试)|
|YuTest10|static void wcPro(String input)|字母,连字符,字母|High|是|否|输入文件内容为:“a-a”|YuTest10.txt|直接执行|Info内容为a-a:1|Info内容为a-a:1|OK|等价类测试(黑盒测试)|
|YuTest11|static void wcPro(String input)|字母,连字符,连字符|Low|是|否|输入文件内容为:“a--”|YuTest11.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest12|static void wcPro(String input)|字母,连字符,其他字符|Low|是|否|输入文件内容为:“a-1”|YuTest12.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest13|static void wcPro(String input)|字母,其他字符,字母|High|是|否|输入文件内容为:“a1a”|YuTest13.txt|直接执行|Info内容为a:2|Info内容为a:2|OK|等价类测试(黑盒测试)|
|YuTest14|static void wcPro(String input)|字母,其他字符,连字符|Low|是|否|输入文件内容为:“a1-”|YuTest14.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest15|static void wcPro(String input)|字母,其他字符,其他字符|High|是|否|输入文件内容为:“a11”|YuTest15.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest16|static void wcPro(String input)|连字符,字母,字母|Low|是|否|输入文件内容为:“-aa”|YuTest16.txt|直接执行|Info内容为aa:1|Info内容为aa:1|OK|等价类测试(黑盒测试)|
|YuTest17|static void wcPro(String input)|连字符,字母,连字符|Low|是|否|输入文件内容为:“-a-”|YuTest17.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest18|static void wcPro(String input)|连字符,字母,其他字符|Low|是|否|输入文件内容为:“-a1”|YuTest18.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest19|static void wcPro(String input)|连字符,连字符,字母|Low|是|否|输入文件内容为:“--a”|YuTest19.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest20|static void wcPro(String input)|连字符,连字符,连字符|Low|是|否|输入文件内容为:“---”|YuTest20.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest21|static void wcPro(String input)|连字符,连字符,其他字符|Low|是|否|输入文件内容为:“--1”|YuTest21.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest22|static void wcPro(String input)|连字符,其他字符,字母|Low|是|否|输入文件内容为:“-1a”|YuTest22.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest23|static void wcPro(String input)|连字符,其他字符,连字符|Low|是|否|输入文件内容为:“-1-”|YuTest23.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest24|static void wcPro(String input)|连字符,其他字符,其他字符|Low|是|否|输入文件内容为:“-11”|YuTest24.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest25|static void wcPro(String input)|其他字符,字母,字母|High|是|否|输入文件内容为:“1aa”|YuTest25.txt|直接执行|Info内容为aa:1|Info内容为aa:1|OK|等价类测试(黑盒测试)|
|YuTest26|static void wcPro(String input)|其他字符,字母,连字符|Low|是|否|输入文件内容为:“1a-”|YuTest26.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest27|static void wcPro(String input)|其他字符,字母,其他字符|High|是|否|输入文件内容为:“1a1”|YuTest27.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest28|static void wcPro(String input)|其他字符,连字符,字母|Low|是|否|输入文件内容为:“1-a”|YuTest28.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest29|static void wcPro(String input)|其他字符,连字符,连字符|Low|是|否|输入文件内容为:“1--”|YuTest29.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest30|static void wcPro(String input)|其他字符,连字符,其他字符|Low|是|否|输入文件内容为:“1-1”|YuTest30.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest31|static void wcPro(String input)|其他字符,其他字符,字母|High|是|否|输入文件内容为:“11a”|YuTest31.txt|直接执行|Info内容为a:1|Info内容为a:1|OK|等价类测试(黑盒测试)|
|YuTest32|static void wcPro(String input)|其他字符,其他字符,连字符|Low|是|否|输入文件内容为:“11-”|YuTest32.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
|YuTest33|static void wcPro(String input)|其他字符,其他字符,其他字符|Low|是|否|输入文件内容为:“111”|YuTest33.txt|直接执行|Info内容为空|Info内容为空|OK|等价类测试(黑盒测试)|
但是仍然不觉得完全保险:程序真的能将数字和所有提到的特殊字符,都当做一类,进行正确处理吗?
于是还是加了最后一个大综合测试用例,其中包含所有需求文档中提到的常用字符:
|Test Case ID 测试用例编号|Test Item 测试项(即功能模块或函数)|Test Case Title 测试用例标题|Test Criticality重要级别|是否自动用例|是否新增修改用例|Pre-condition 预置条件|Input 输入|Procedure 操作步骤|Output 预期结果|Result
实际结果|Status
是否通过|Remark 备注(在此描述使用的测试方法)||
|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|:--|
|YuTest34|static void wcPro(String input)|大综合|High|是|否|输入文件内容为:“software Let\'s
night- night-night -night
"I I" "I"
TABLE1-2
(see Box 3–2).8885d_c01_016
a a a~a`a!a#a%a^a&a*a_a...a.a(a)a[a]a+a=a:a;a"a\'a|aa,a/a?a0a1a2a3a4a5a6a7a8a9a”|YuTest34.txt|直接执行|Info内容为:software:1 let:1 s:1 night:2 night-night:1 i:3 table:1 see:1 box:1 d:1 c:1 a:40|Info内容为:software:1 let:1 s:1 night:2 night-night:1 i:3 table:1 see:1 box:1 d:1 c:1 a:40|OK|综合测试|
这样就得到了35个测试用例。
编写测试脚本
测试脚本乏善可陈,唯一值得一提的地方或许在于,我在测试类WCProTestYuQiao的Beforeclass方法中,重写了一遍测试用到的输入文件,从而更好地保证了测试的可移植、可重用性。
@BeforeClass
public static void setUpBeforeClass() throws Exception {
int n=35;
String fileName[] = new String[n];
String fileContent[] = new String[n];
//给文件名赋值
for(int i=0;i<n;i++)
{
fileName[i]="YuQiaoTestFile\\\\YuTest"+i+".txt";
//System.out.println(fileName[i]);
}
//给文件内容赋值
fileContent[0]="a";
fileContent[1]="";
...
单元测试的结果与评价
几度重新设计用例,重新编写脚本,最终终于得到一条令人满意的green bar:
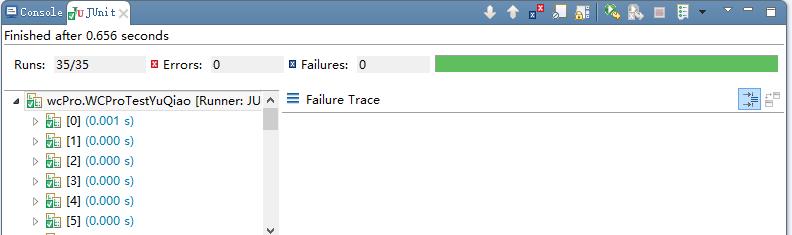
测试质量
白盒测试的七个测试用例,完全符合独立路径测试的方法和思想,认为完成得很不错。
而黑盒测试部分,可以说我的等价类划分、测试用例设计都只是很大程度上运用了黑盒测试的思想,而非严格遵循其方法。
三种字符,27个用例,其中类似 “-a1”和“1-a”的文本内容,从需求的角度,程序应该作为同一等价类处理。这样的设计,从等价类划分的角度来说,是有冗余的。
但是这里我认为,“程序能否按照需求,对同一等价类内的输入进行等价处理”,本身就是风险的一大来源。因此完全按照需求进行等价类划分来测试,会让我感到风险太大;对不同输入的组合进行测试,结果更有保证。
测试的一大重点,在于低成本和低风险之间的平衡。
而对于wordCountPro这样的小程序,测试的成本和商品软件相比,是极低的(虽然对我个人来说还是下了很大功夫)。用35个用例所耗费的时间和精力,来换取一个更有保障的测试结果,我看性价比挺高,还是值得的。
也就是说,我认为我的测试质量不错。
被测模块质量
测试全部通过,可以认为被测模块较好地实现了功能需求。
拓展任务
考虑到基本任务和拓展任务分别要使用tag打标签,为了保证完成拓展任务时有事可做,我们在完成基本任务时,没有仔细参照代码规范;在拓展任务时,再对照规范进行检查。
规范阅读与理解
选择了阿里巴巴Java开发手册作为参考的规范。主要学习了其中的
- 命名风格
- 常量定义
- 代码格式
三个部分。
阿里巴巴java开发手册
【强制】类名使用 UpperCamelCase 风格,但以下情形例外: DO / BO / DTO / VO / AO /
PO 等。
正例: MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion
反例: macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion
【强制】方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格,必须遵从
驼峰形式。
正例: localValue / getHttpMessage() / inputUserId
【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例: MAX_STOCK_COUNT
反例: MAX_COUNT
这几条规则,可以使代码读者看到名称,就知道是类还是变量、方法、常量。
【强制】抽象类命名使用 Abstract 或 Base 开头; 异常类命名使用 Exception 结尾; 测试类 命名以它要测试的类名开始,以 Test 结尾。
这一条可以使代码读者看到类名就知道是否是抽象类、测试类。
【强制】类型与中括号紧挨相连来定义数组。
正例: 定义整形数组 int[] arrayDemo;
反例: 在 main 参数中,使用 String args[]来定义。
变量类型和名称区分得更清晰。
【强制】不允许任何魔法值(即未经预先定义的常量) 直接出现在代码中。
反例: String key = "Id#taobao_" + tradeId;
cache.put(key, value);
更易修改,增强了代码的可维护性。
【强制】大括号的使用约定。如果是大括号内为空,则简洁地写成{}即可,不需要换行; 如果
是非空代码块则:
1) 左大括号前不换行。
2) 左大括号后换行。
3) 右大括号前换行。
4) 右大括号后还有 else 等代码则不换行; 表示终止的右大括号后必须换行。
初见这句左大括号前不换行,我既惊讶又愤怒。
这种方式严重降低了代码的清晰性、可读性和可维护性。
没有清晰的缩进对齐,别说其他人,就是作者本人,编程和修改的过程也会徒增痛苦。
百度了一下,这条规则的主要好处在于,使代码更加紧凑,同样大小的界面可以看到更多行的代码。
行吧行吧你说的对。
队友代码分析
其实我们通过开三场同行评审会的方式,对三个大模块都进行了静态代码检查。
由于其他同学写的模块中,output()相对复杂,这里主要说说,在17161同学的output()方法中,我发现的问题。
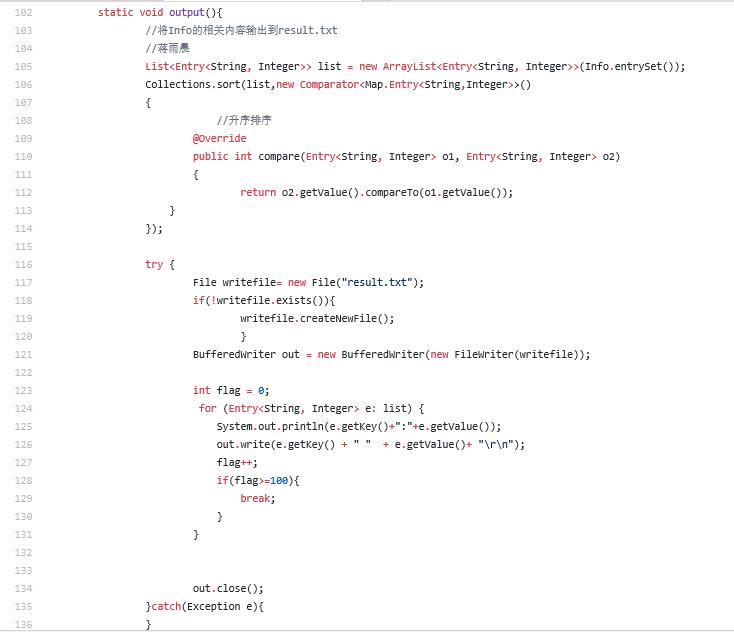
可以看到,代码中有许多地方不符合阿里巴巴java开发手册。
第107/111行的左大括号之前换了行;
第114/135行的右大括号后没换行;
第103/104行的类的注释没有采用javadoc规范;
第117行变量writefile命名不符合小驼峰规范;
第123行变量flag命名含义不清晰;
此外,第108行降序排序被写成了升序排列;
总体上注释很少,但由于方法功能简单,可读性仍然很强,不会造成理解障碍。
代码其他变量明明均符合规范,其他大括号换行合理。
静态代码检查工具使用
选择了阿里代码规约检查插件,地址如下:https://p3c.alibaba.com/plugin/eclipse/update
安装方法如下:
https://blog.csdn.net/huangzhe1013/article/details/78248036
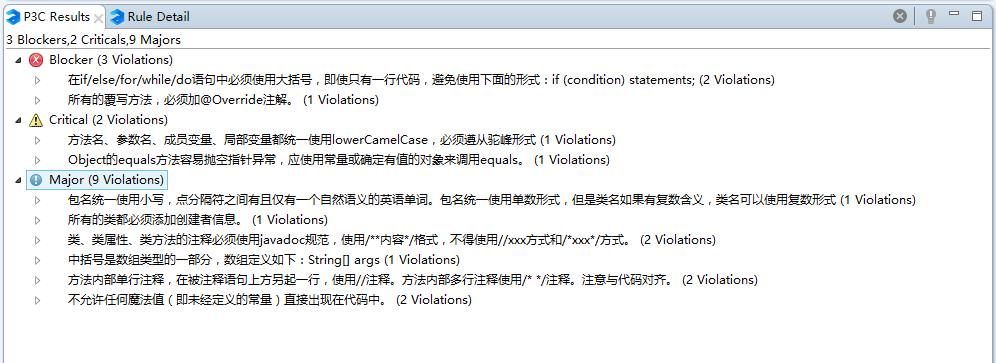
出现的问题已经在截图中列出,主要违反了大括号、命名和注释方面的规范。
其中最严重的问题在于if语句后没打大括号:
if(word.equals("")||!word.matches(containLetter))
continue;
于是进行了改进,得到了最终的代码。看到这0 Blockers,0 Criticals ,0 Majors ,真是舒服啊。
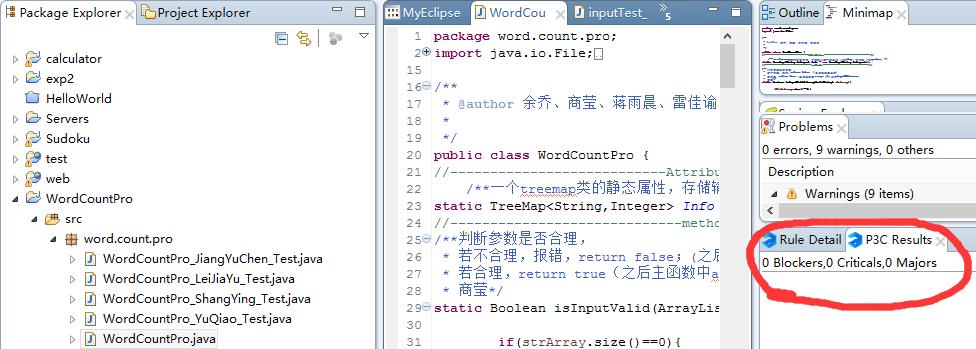
重新运行单元测试,没问题:
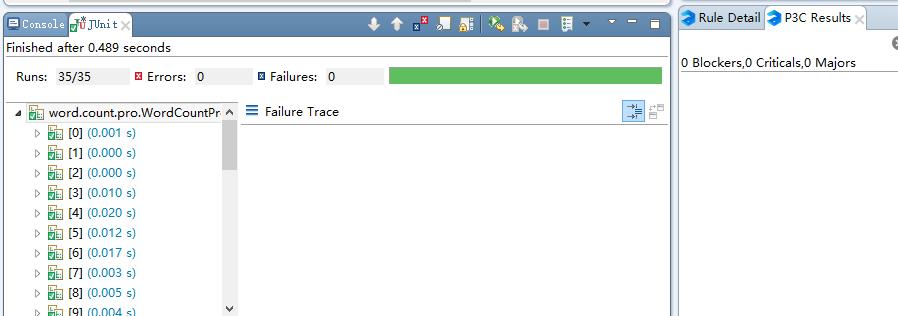
赏心悦目,赏心悦目。
小组总结
上面的截图没有扫描测试类,如果扫描整个小组含测试类的全部代码,结果如下:
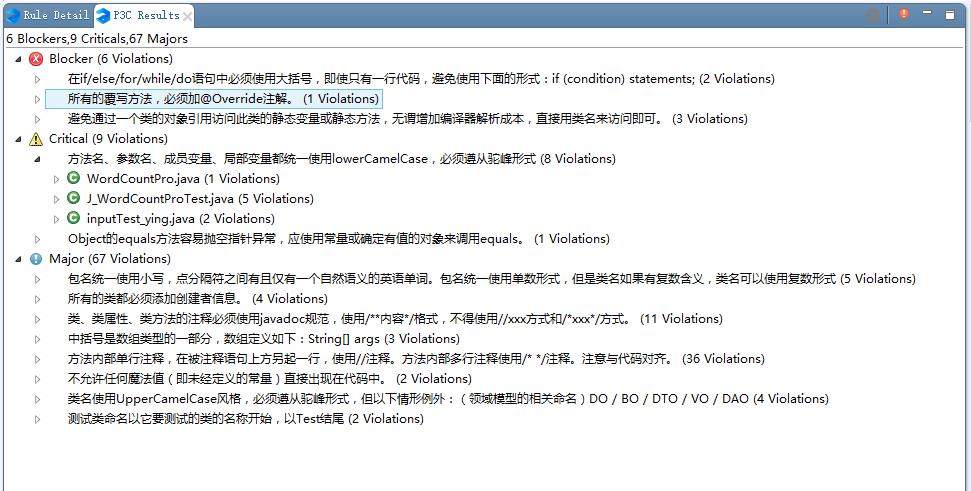
本次小组代码的主要问题,还是在大括号、命名、注释、个别函数使用、数组声明、魔法值等方面违反了代码规范。主要原因是开始编码前,没有仔细研读规范(以方便之后找错并修改)。现在有了这方面意识,也熟悉了常见的不合规范的错误,以后多注意,尽量不再犯。
后记
这次项目经历,让我印象较深的主要是一下两点:
1.先把设计做好,再开始实施。
已经写好测试脚本后,推到重来,重新设计测试用例,非常耗时。
2.一步一步完成一个项目,看着进度条一点一点前进,爽爽的。
3.做项目期间,室友竟然评论我:你最近吃饭怎么这么不积极。
一直信奉“良好的作息是生活高效健康,充满活力”的我,深感这样不好。
以后做项目,也好规律作息,抓紧时间,提高效率。