爬虫:爬取猫眼电影top100
Posted Felix Wang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫:爬取猫眼电影top100相关的知识,希望对你有一定的参考价值。
一:分析网站
目标站和目标数据
目标地址:http://maoyan.com/board/4?offset=20
目标数据:目标地址页面的电影列表,包括电影名,电影图片,主演,上映日期以及评分。
二:上代码
(1):导入相应的包
import requests from requests.exceptions import RequestException # 处理请求异常 import re import pymysql import json from multiprocessing import Pool
(2):分析网页
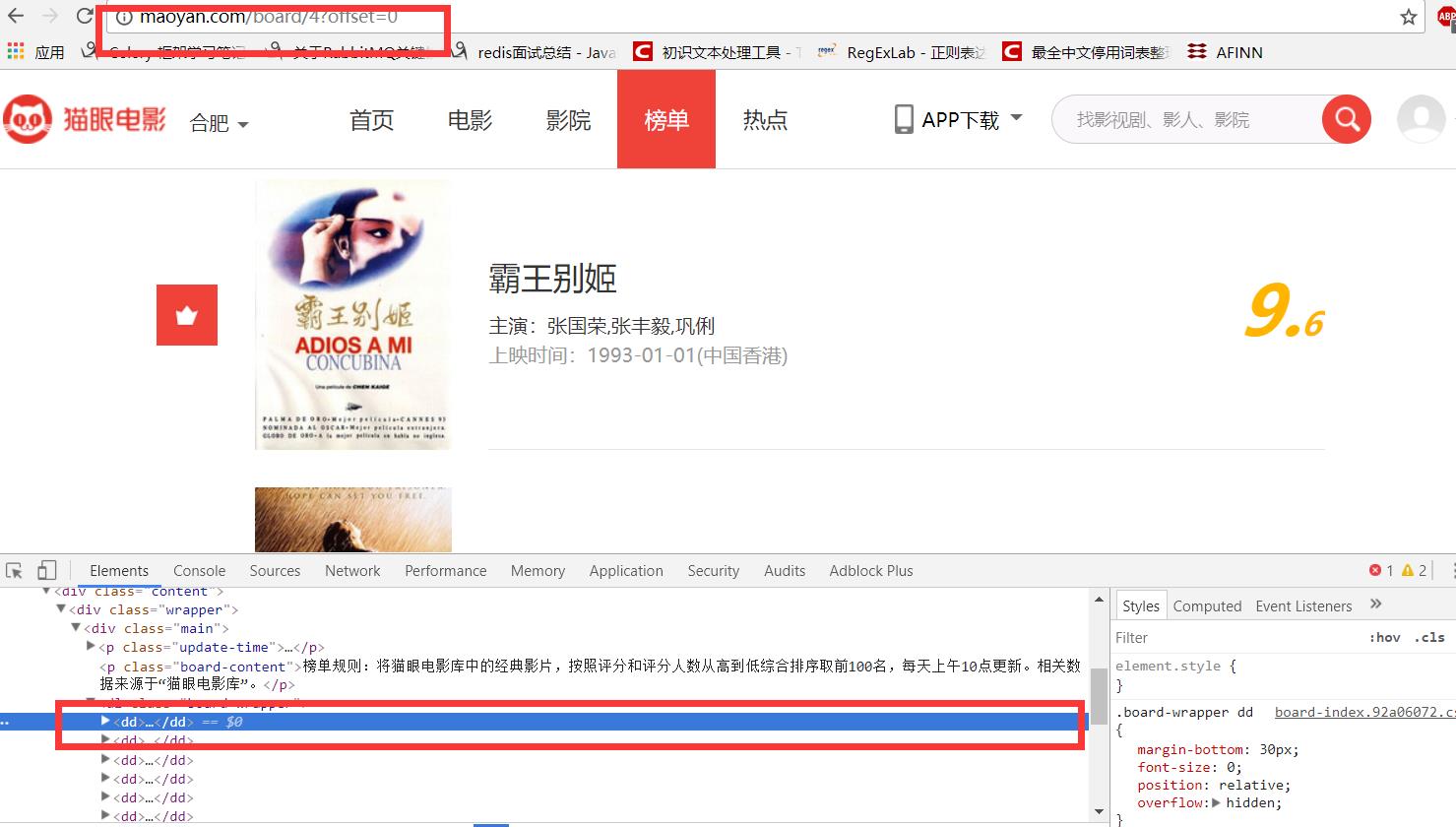
通过检查发现需要的内容位于网页中的<dd>标签内。通过翻页发现url中的参数的变化。
(3):获取html网页
# 获取一页的数据 def get_one_page(url): # requests会产生异常 headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36\', } try: response = requests.get(url, headers=headers) if response.status_code == 200: # 状态码是200表示成功 return response.text else: return None except RequestException: return None
(4):通过正则提取需要的信息 --》正则表达式详情
# 解析网页内容 def parse_one_page(html): pattern = re.compile( \'<dd>.*?board-index.*?>(\\d+)</i>.*?data-src="(.*?)".*?class="name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>\', re.S) # re.S可以匹配任意字符包括换行 items = re.findall(pattern, html) # 将括号中的内容提取出来 for item in items: yield { # 构造一个生成器 \'index\': item[0].strip(), \'title\': item[2].strip(), \'actor\': item[3].strip()[3:], \'score\': \'\'.join([item[5].strip(), item[6].strip()]), \'pub_time\': item[4].strip()[5:], \'img_url\': item[1].strip(), }
(5):将获取的内容存入mysql数据库
# 连接数据库,首先要在本地创建好数据库 def commit_to_sql(dic): conn = pymysql.connect(host=\'localhost\', port=3306, user=\'mydb\', passwd=\'123456\', db=\'maoyantop100\', charset=\'utf8\') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标的数据类型为字典 sql = \'\'\'insert into movies_top_100(mid,title,actor,score,pub_time,img_url) values("%s","%s","%s","%s","%s","%s")\'\'\' % ( dic[\'index\'], dic[\'title\'], dic[\'actor\'], dic[\'score\'], dic[\'pub_time\'], dic[\'img_url\'],) cursor.execute(sql) # 执行sql语句并返回受影响的行数 # # 提交 conn.commit() # 关闭游标 cursor.close() # 关闭连接 conn.close()
(6):主程序及运行
def main(url): html = get_one_page(url) for item in parse_one_page(html): print(item) commit_to_sql(item) if __name__ == \'__main__\': urls = [\'http://maoyan.com/board/4?offset={}\'.format(i) for i in range(0, 100, 10)] # 使用多进程 pool = Pool() pool.map(main, urls)
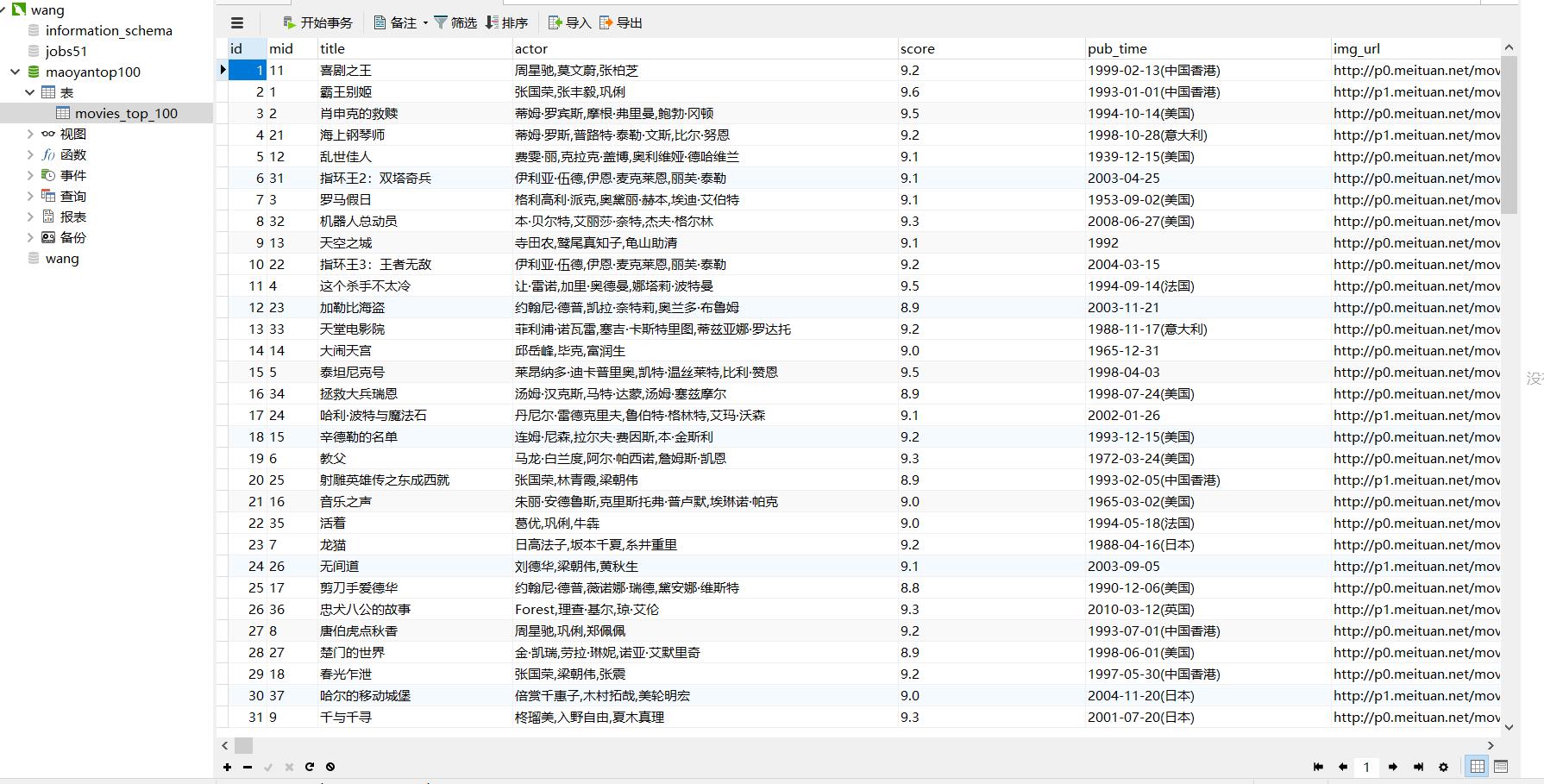
(7):最后的结果
完整代码:
# -*- coding: utf-8 -*- # @Author : FELIX # @Date : 2018/4/4 9:29 import requests from requests.exceptions import RequestException import re import pymysql import json from multiprocessing import Pool # 连接数据库 def commit_to_sql(dic): conn = pymysql.connect(host=\'localhost\', port=3306, user=\'wang\', passwd=\'123456\', db=\'maoyantop100\', charset=\'utf8\') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 设置游标的数据类型为字典 sql = \'\'\'insert into movies_top_100(mid,title,actor,score,pub_time,img_url) values("%s","%s","%s","%s","%s","%s")\'\'\' % ( dic[\'index\'], dic[\'title\'], dic[\'actor\'], dic[\'score\'], dic[\'pub_time\'], dic[\'img_url\'],) cursor.execute(sql) # 执行sql语句并返回受影响的行数 # # 提交 conn.commit() # 关闭游标 cursor.close() # 关闭连接 conn.close() # 获取一页的数据 def get_one_page(url): # requests会产生异常 headers = { \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36\', } try: response = requests.get(url, headers=headers) if response.status_code == 200: # 状态码是200表示成功 return response.text else: return None except RequestException: return None # 解析网页内容 def parse_one_page(html): pattern = re.compile( \'<dd>.*?board-index.*?>(\\d+)</i>.*?data-src="(.*?)".*?class="name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>\', re.S) # re.S可以匹配任意字符包括换行 items = re.findall(pattern, html) # 将括号中的内容提取出来 for item in items: yield { # 构造一个生成器 \'index\': item[0].strip(), \'title\': item[2].strip(), \'actor\': item[3].strip()[3:], \'score\': \'\'.join([item[5].strip(), item[6].strip()]), \'pub_time\': item[4].strip()[5:], \'img_url\': item[1].strip(), } # print(items) def write_to_file(content): with open(\'result.txt\', \'a\', encoding=\'utf8\')as f: f.write(json.dumps(content, ensure_ascii=False) + \'\\n\') ii = 0 def main(url): html = get_one_page(url) for item in parse_one_page(html): global ii print(ii, item) ii = ii + 1 commit_to_sql(item) write_to_file(item) # print(html) if __name__ == \'__main__\': urls = [\'http://maoyan.com/board/4?offset={}\'.format(i) for i in range(0, 100, 10)] # 使用多进程 pool = Pool() pool.map(main, urls)
以上是关于爬虫:爬取猫眼电影top100的主要内容,如果未能解决你的问题,请参考以下文章