ConcurrentHashMap
Posted 意犹未尽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentHashMap相关的知识,希望对你有一定的参考价值。
HashMap不是线程安全的。在多线程操作下 可能会数据丢失!
首先我们了解一下hashmap的存储结构。
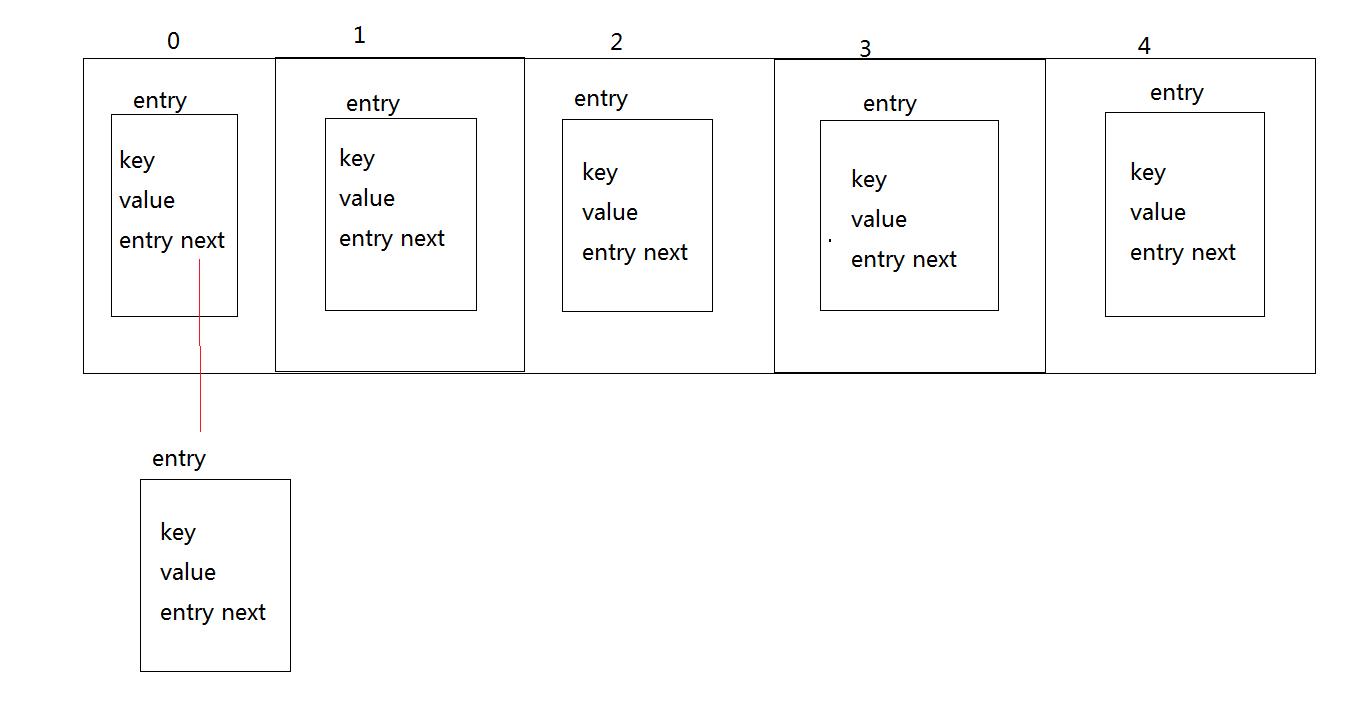
hashmap内部是通过数组加链表的形式存储的。
链表的作用则是防止hash碰撞产生的数据丢失而设计的。
什么是hash碰撞
2个不同的key hashcode相同
比如key1通过hashcode算出存储的位置是数组下标为1的位置,放置进去。这个时候key2也通过hashcode算出数组下标位1的位置 发现这个位置被占用了。则将原来当前位置的数据保存到next属性下 然后将key2对应的数据存储到数组下标位1的位置。
通过key2的去get的时候 通过hash算出下标为1的位置 发现这是一个hash碰撞域。则遍历链表通过eques去比较对应的值取出(ps:这也就是为什么重写hashcode也要重写eques)
测试代码
public class Classes { private int id; @Override public boolean equals(Object obj) { return super.equals(obj); } public Classes(int id){ this.id=id; } @Override public int hashCode() { return 55; } public int getId() { return id; } public void setId(int id) { this.id = id; } }
我们重写了hashcode保证hashcode都相同
public static void main(String[] args) { //ConcurrentHashMap <Classes,Student> school=new ConcurrentHashMap <Classes, Student>(); //Hashtable<Classes,Student> school=new Hashtable<Classes,Student>(); HashMap<Classes,Student> school=new HashMap<Classes, Student>(); for (int i=0;i<1000;i++){ final int index=i; new Thread(new Runnable() { @Override public void run() { school.put(new Classes(index),new Student()); } }).start(); } try { Thread.sleep(5000); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(school.size()); }
运行 我们会发现school的size始终小于1000;
比如我们多个线程下 hash碰撞,线程a发现下标1被占用。将容器里面的数据设置到自己的next里面。还没有写入。这个时候线程b也将下标为一的设置到自己的next里面。线程a写入 线程b写入.这个时候线程a的记录就被线程b丢覆盖。(或者同时发现下标1没被占用 线程a写入 线程b写入)
还有一种并发体现。内部是数组实现 当数组需要扩容的时候。多个线程同时发现需要扩容会数据丢失
HashTable
如果我们把注释的HashTable打开 发现并不会有数据丢失的问题 输出是1000;
因为HashTable几乎在所有方法上都加上了一个sychronized关键字。
方法上使用sychronized关键字 都是使用对象锁。一个线程执行get操作。没是释放锁之前 其他线程都会放到monitor 的_wait里面等待;
直到锁释放 wait集合里面的线程采取竞争这把锁。
我们由此可以看出HashTable的缺点。
1. 调用hashTable的方法 没执行完毕之前其他线程调用 都会等待(效率低)
2.锁竞争 如上1000个线程 一个线程执行put 其他999线程都加 入到_wait集合里面。当锁释放,999个线程同时去竞争这把锁。线程越多 会(导致cpu 过高)
ConcurrentHashMap
ConcurrentHashMap是通过减小锁的粒度 来对HashTable进行优化
ConcurrentHashMap的存储结构
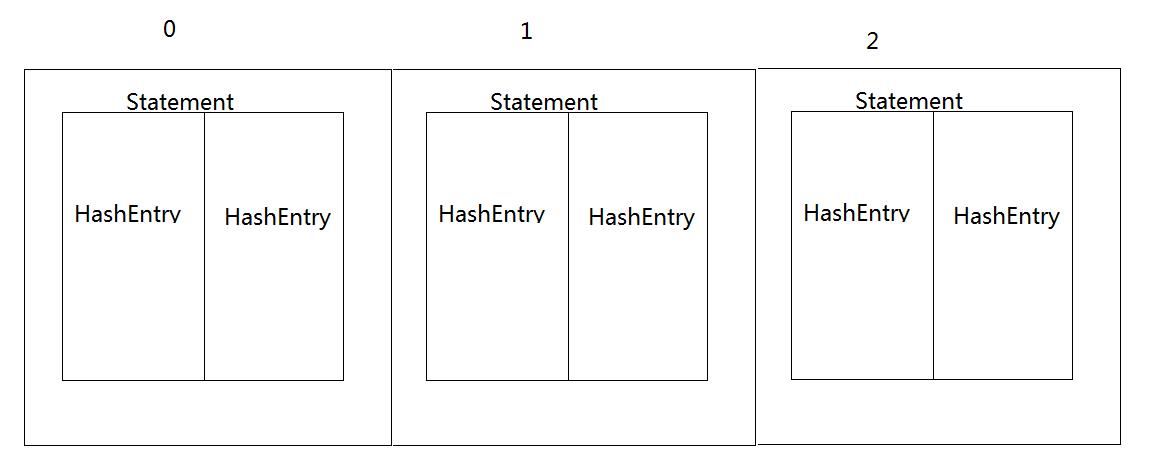
我们可以理解成 Statement就是一个HashTable。我们在put的时候 ConcurrentHahsMap会对key的hashCode进行二次运算 算出Statement的位置。然后根据hashcode存储到对应的位置。ConcurrentHashMap相当于是把大锁拆分成了对应的小锁
在并发操作下 size方法如何保证正确性呢。ConcurrentHashMap会通过获取几次的size进行比较 如果一样就返回。如果不一样表示有其他线程在操作。则所有statement都加上锁然后再获取size
以上是关于ConcurrentHashMap的主要内容,如果未能解决你的问题,请参考以下文章